1个人+10000个GPU,就能打造价值10亿美元的公司?OpenAI已经掌握了通往AGI的内部路径,我们距ASI只有几千天时间了?就在最近,OpenAI CEO奥特曼在最新访谈里,再次爆出不少金句。

YC总裁兼CEO Garry Tan对奥特曼展开了一次访问,谈论了OpenAI的起源,公司的下一步发展,以及他对于创始人该如何驾驭一个庞大公司的建议。在所有人都在认为奥特曼又在炒作的同时,德扑之父、OpenAI研究员Noam Brown却证实,「但据我所见,他所说的一切都与OpenAI一线研究人员的普遍观点相符」。
另一位OpenAI员工称,「100%赞成!在OpenAI工作的三年里,我一直在专心地听奥特曼的话,他的言辞和评论都很准确」。

这也就意味着,4级AGI——「AI发明者」很快将要实现了!

ASI几千天内降临,现在是创办科技公司的最佳时机吗
前不久,奥特曼的一篇《ASI几年内降临,人类奇点将至》在圈内引发热议。他表示,深度学习已经奏效了,它能够真正学习任何数据的分布模式。如今人类奇点已经近在咫尺,我们眼看着就要迈进ASI的大门。奥特曼甚至直接预言:ASI将在「几千天内」降临!
由此,Garry Tan和奥特曼展开了进一步讨论。奥特曼表示,如今可以说是创办科技公司的最佳时机。每次重大技术革命,都让我们能比之前做得多,这也让他希望,公司会更令人惊奇,更有影响力。当事情进展缓慢时,大公司会占据优势。当移动互联网/半导体/AI革命发生时,新兴公司就会占据优势。Garry Tan提到奥特曼之前对ASI几千天内到来的预判,奥特曼表示,这其实是OpenAI的愿景,其实相当疯狂。他认为,自己能看到这样一条路径。当OpenAI的工作不断积累,过去三年中的进展继续在接下来的三年、六年、九年中持续下去,保持这种速度,那系统能做的事情,就会非常非常多。跟封闭的、在某领域有明确任务的原始智商相比,o1已经非常聪明了。奥特曼认为,我们可能会遇到未知的障碍,或者错过一些东西,但目前看来,前方还有许多复合增长尚未发生。在他看来,解决气候问题、建立太空殖民地、发现所有物理学、近乎无限的智能和充足的能源这些事情,也许的确离我们并不遥远。而他喜欢YC的一点就是,它鼓励这种稍微不切实际的技术乐观主义,以及「你可以做到」的信念感。如果我们能实现充足能源,人类的体力劳动就能通过机器人和随时可调动的语言和智能来解锁,我们将进入一个真正的富足时代。我们会更快地得出更好的想法,然后在物理世界中将之实现(当然也需要大量能源)。如今,太阳能加储能的发展轨迹已经足够好,即使没有重大的核突破,我们也会很好。奥特曼预言到:未来,我们会解决物理学中的每一个问题,这只是时间问题。到那一天,我们不会再讨论核聚变,而是讨论戴森球。
对我们的曾孙来说,地球的能源已经不够了,他们会去有大量物质的外太空。
OpenAI「5级AGI」蓝图
Garry Tan表示,对OpenAI来说,这是伟大的一年,尽管有一些戏剧性事件。你从去年秋天的罢免事件中学到了什么,对一些离职有什么感受?奥特曼称,很累,但还好。我们用了不到两年的时间,加速一个中型、甚至是大型科技公司的进程,这通常来说会需要十年的时间。
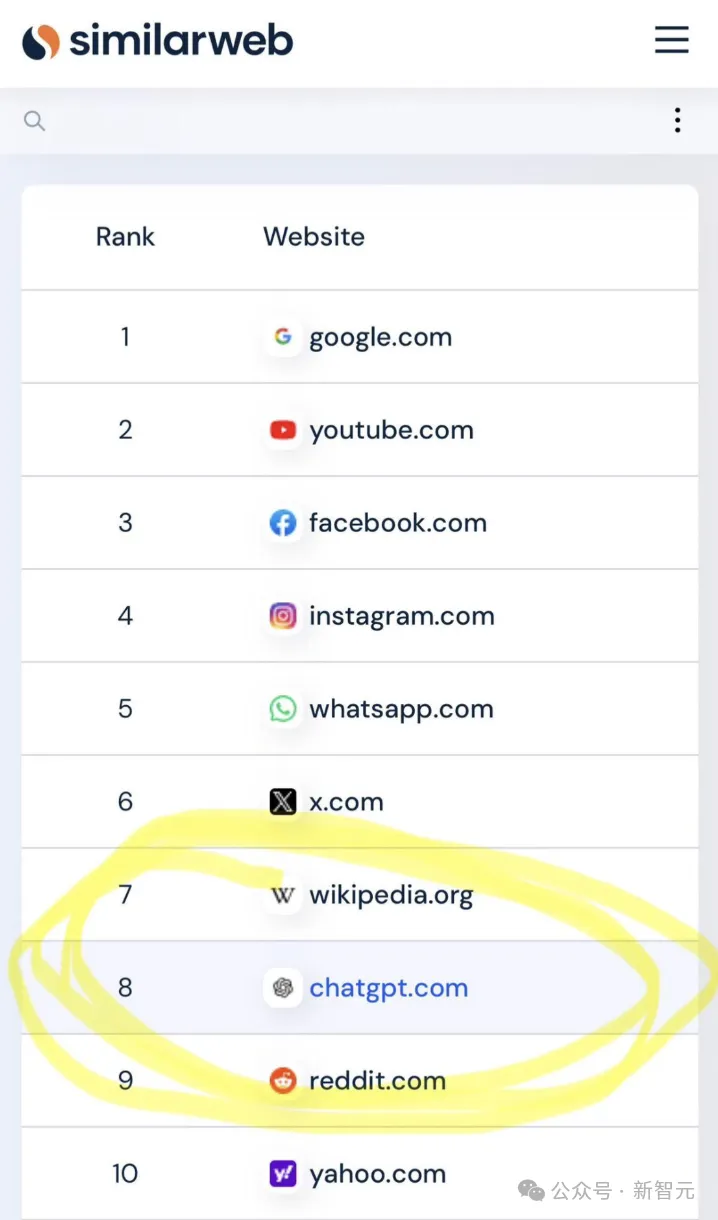
奥特曼最近表示,ChatGPT已经成为世界上第八大网站
Garry Tan对此表示肯定。这会伴随着很多痛苦的事情。任何公司随着规模扩大,都会以某种速度经历管理团队的变动。那些在0-1阶段表现出色的人,也不一定适合1-10,10-100的阶段。奥特曼继续称,我们也在改变目标。在这个过程中犯了很多错误,但也做对了一些事情。这带来了很多变化,奥特曼认为公司的目标不论是AGI还是其他,就需要我们在每个阶段尽可能做出最好的决策。奥特曼希望,OpenAI正在走向一个更稳定的时期,但他也确定信未来还会有其他的,毕竟一切发展都是动态的。Garry Tan追问道,OpenAI现在是如何运作的?奥特曼称,我认为从目前为止到构建AGI仍有大量工作要做。而且,OpenAI的研究路径相当清晰,基础设施路径、产品路径也越来越清晰。最近,OpenAI在YC举办了o1黑客马拉松,获胜者之一是Camphor。所以CAD/CAM初创公司,在黑客马拉松期间,也可以构建出一个可以迭代改进的模型,这听起来有点像AGI第四级,也就是创新者阶段。

Garry Tan称,我认为从二级跃升到三级很快就会发生,但三级到四级的跳跃会更加困难,需要一些中型或更大模型的想法。奥特曼表示,那个演示和其他一些演示让我相信,只要以非常有创意的方式使用现有模型,就可以获得大量的创新。Garry称,Camphor基本上已经构建了CAD/CAM的基础软件。然后,语言就像是LLM的接口,可以像工具一样使用软件。如果你将其与代码生成的想法结合起来,那是一个有点可怕又疯狂的想法,对吧?不仅LLM可以编写代码,它还可以为自己创建工具,然后组合这些工具,就像一个思维链一样。奥特曼肯定道,「是的,我认为事情的发展速度会比人们现在所意识到的要快得多」。Garry Tan问道,你能简要谈谈第三级、第四级和第五级吗?奥特曼称,AGI已经成为一个被严重滥用的词,人们指的东西各不相同。我们试图说,这是我们对事物顺序的最佳猜测。第二级推理者,o1已经实现了这一阶段。第三级是智能体,能够执行长期任务,比如与环境多次互动,并与人类协同工作….我认为,OpenAI很快就实现这点。第四级是创新者,就像科学家一样,能够在很长一段时间内,探索不太被理解的现象,并理解其本质。第五级,在整个公司/整个组织的规模上,将带来巨变。
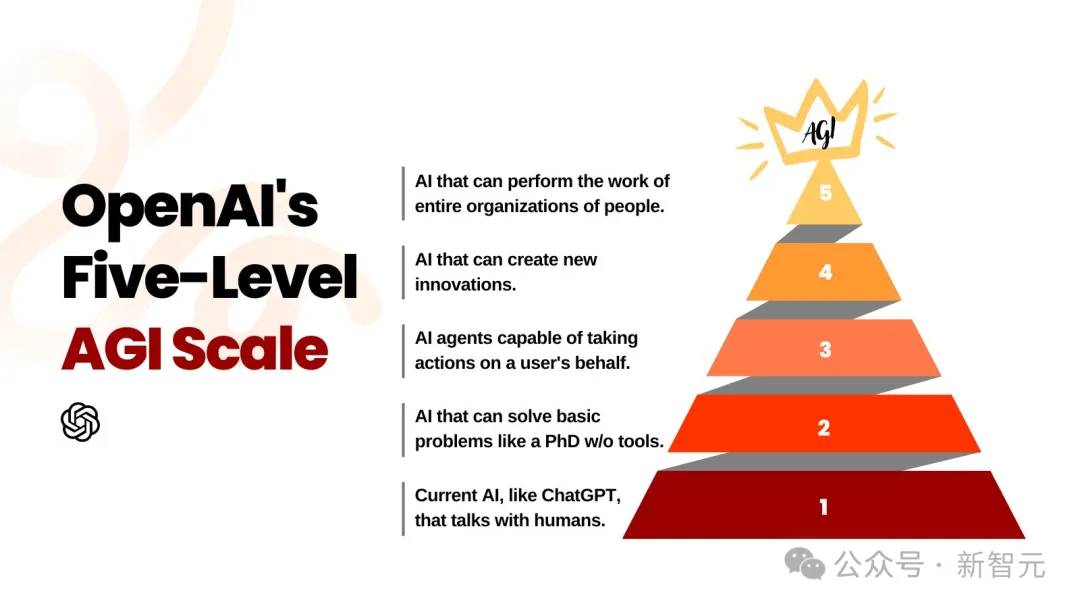
不得不承认,这听起来感觉有点像分形,第二级目标是为了和第五级相呼应,让多个智能体自主纠正,并协同工作。奥特曼继续表示,这将会成为创业公司的最大时机,我不知道如何看待这一点,但它确实发生在我的身上。要知道,一个人+1万块GPU,将会打造数十亿美元的公司。最后,Garry Tan问道,你对那些即将开始创业,或刚刚开始创业的人,有什么建议?奥特曼表示,继续押注这个趋势,当前技术还远未达到饱和点。未来,模型会变得更好,而且速度非常快。作为创业公司创始人,利用这这点与没有用上其相比,能够做到的事情,是截然不同的。那些大公司,中型公司,甚至是成立几年的初创公司,他们已经在进行季度规划周期。谷歌则是在进行年度、十年规划周期。你的速度、专注、信念,以及对技术快速发展的反应能力,是创业公司最大的优势。从古至今几乎一直都是如此,但尤其是现在。因此,我建议去构建一些与AI相关的东西,并利用这种能力去发现新事物,并立即做出行动,而不是将其纳入季度规划周期。此外,奥特曼还表示,当有一个新的技术平台时,一些人很容易陷入误区:我在做AI,所以普通的商业规则不适用于我。有了AI就足够了,因此不需要其他竞争优势。实际上,商业基本规则依然适用,不要被AI的光环迷惑,技术优势只是成功的一个要素,而并非全部。
奥特曼:我是如何加入YC的
Paul Graham追忆过,在2005年,奥特曼还是斯坦福大学的大一新生时,就坚持加入YC。Graham跟他说,你太年轻了可以再等等,奥特曼于是当场撒了个谎,表示我大二了,我就要来。Garry Tan问道,是这样吗?奥特曼承认了这个故事,并且表示自己并不像这些人传说中的那样强大。在他看来,YC之所以如此特别,就是有一个了不起的人告诉你:去做吧,我相信你。而另外一个原因,就是在这里拥有一群同样做事的同伴群体。因此奥特曼给年轻人最好的建议就是找到这样一群做事的同伴。当时,他还没有意识到,这件事对着自己后来的成功如此重要。

主持人提到:通过辍学,你选择了一条收益更大的路。奥特曼表示,自己很喜欢斯坦福,但的确并没有感觉到自己被一群让自己想变得更好、更有雄心的人包围。在斯坦福,所有的竞争就集中在:谁能去哪个投行实习?奥特曼惭愧地表示,自己也掉进了那个陷阱。但在看到YC的氛围后,选择从斯坦福辍学其实并不那么难。奥特曼认为,没人能免于同辈压力,但你可以选择和优秀的人同行。在他进入YC研究的早期时间里,几乎每个人都在谈论着AI,似乎它已触手可及,但那是10年前。在这样的氛围影响下,奥特曼开始希望他能够讲述一个AI显然能成功并成为焦点的故事。YC所做的,以及奥特曼此后的行为,就是将资源分给聪明的人。有时会成功有时会失败,但这种尝试是必不可少的。在奥特曼加入YC后不久,经历了AI发展的一个小高潮。在2014年年末到2016年年初这段时间,DeepMind取得了一系列瞩目的成就,超级智能成为了当时的热议话题。作为一个AI迷,奥特曼决定自己应该尝试做些什么了。
OpenAI的创业那些事
寻找志同道合同伴的感觉,就像银行抢劫的电影开头,你开着车四处寻找合适的人。而那些被你掳到车上的人,他们会说:「你这个混蛋,我加入了」。在奥特曼听闻了Ilya的大名,并通过Youtube上的视频,确认了他却有不负盛名的能力后,他立即向Ilya发送了邮件。当然,Ilya没有回复。奥特曼便去了Ilya演讲的一个会议去见他,在见面后,他们开始了频繁的交流。而Greg Brockman是奥特曼在Stripe的工作的早期认识的。奥特曼回忆,他与OpenAI初创成员间的第一次谈话中,就立下了追求通用人工智能的目标。

这种言论在当时几乎是疯狂且不负责任的,但它确实引起了成员们的注意和热情。奥特曼表示,他们当时就像是掌握主流话语权的老顽固眼里的一群乌合之众。奥特曼那时大概是30岁,是成员里年龄最大的那个,和其他人的差距也很大。但就是这样的一群充满热情的小年轻,到处奔波、逐个找人,与不同的群体会面。而关于实现通用人工智能的这件事,在历经九个月后,开始成形。2016年的1月3日,在Ilya处理完与谷歌的事宜后,团队一起去了Greg的公寓,开始决定他们未来究竟要做哪些事。而那时他们只有10个人左右。而OpenAI的成员花了很长的时间才弄清楚他们究竟要做什么。奥特曼现在回顾时,发现当时的努力的目标其实只有三个:弄清楚如何进行无监督学习,解决强化学习,团队人数不超过 120 人。虽然第三个目标没有达成,但前两项在预期内完成得不错。但他们的第二个大目标却在当时引起了许多争议和批评。强化学习的核心信念就是深度学习有效,并且会随着规模的扩大变得更好。但在当时,扩大规模的做法被视为一种异端,批评者认为这些是一些偷懒的小把戏,不是真正的学习,也算不上推理。扩大规模只是在浪费计算资源,甚至可能导致AI冬天的到来。但对OpenAI来说,扩大规模的做法虽然一开始源于团队的直觉,后来有了数据来证明它的可预测性。OpenAI的团队开始前,就通过自己得出的数据结果坚定了扩大规模的趋势。随着他们不断提高模型的规模,结果也在不断变好。人们期望「少即是多」,但OpenAI却证明了「多即是多」。奥特曼表示,深度学习就像一种非常重要的涌现现象。虽然他们现在还没完全理解实践中的所有细节,但确实有一些非常基础且重要的东西在发生。对于OpenAI这样的创业公司来说,它所拥有的资源比DeepMind这样的公司要少得多。大公司可以尝试很多事,但创业公司只能专注在一项中,这就是OpenAI获胜的原因和方法。「我们不知道我们不知道的事,但我们知道这件事有效,所以我们会真正专注于此」。「我们没有花费努力去找到一个聪明的方式去解决问题,而只是做眼前的事并持续推进它」。奥特曼表示,自己一直对规模感兴趣,它对所有事物都具有涌现的特性。对创业公司是这样,事实也证明,它对深度学习也同样起效。但让OpenAI获得成功的原因,是它即使在籍籍无名时,也拥有一个极具才华的研究团队。他们为目标的推进贡献非常巨大。而另一点是OpenAI将所有资源都赌在了他们扩大规模的信念上。人们总觉得鸡蛋不能当放同一个篮子里,但OpenAI则对自己的选择All in。做一个坚定的乐观主义者,奥特曼认为这是许多成功的YC创业公司中的共同点。
同样的,奥特曼也表示,没有人能掌握世界上的所有正确答案,会告诉你应该怎么去做。
你需要的是去寻找并快速迭代自己的路,而在初期,没有数据和结果能支持你,你只能依靠自己的信念。
满血版o1、Sora即将大放送
未来几周,甚至两个月内,OpenAI真的要放大招了。还记得几周前,奥特曼突然冒泡,「下个月是ChatGPT的第二个生日,我们应该送它什么生日礼物呢」?
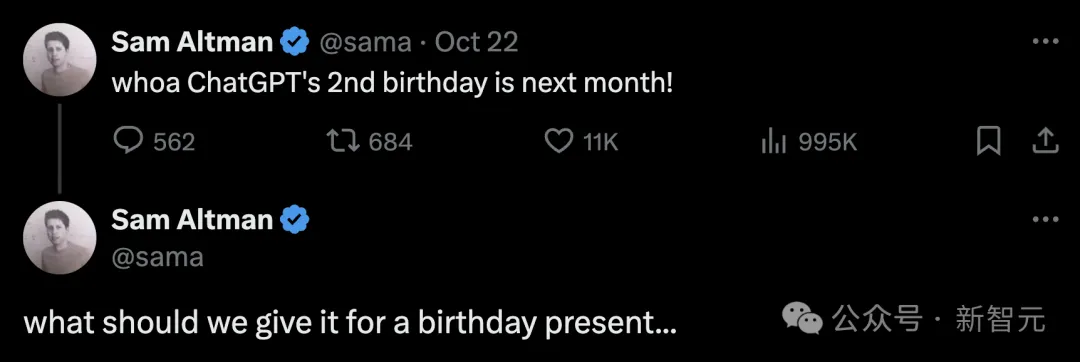
在11月30日,即将迎来的ChatGPT两周年前后,人们都在等着OpenAI新模型的发布。这不,就连ChatGPT官方账号都不藏着掖着了,满血版o1快来了。
就在刚刚,OpenAI研究员Jason Wei解释了,o1推理思维的过程。在o1范式之前,思维链的实际表现和人类期望它达到的效果之间存在差距。它更像是先有了答案,再去对答案进行解释,列出步骤。实际上,模型只是模仿了它在预训练中见过的推理路径,比如数学作业解答,而不是一步步推理得到答案。这些数据的问题在于,它是作者在其他地方完成所有思考后才总结出来的解答,而不是真正的思维过程。所以这些解答通常信息密度很差。一个明显的例子就是「答案是5,因为…」这样的表述,其中「5」这个数字突然包含了大量新信息。
在o1范式下,你可以看到思维链与教科书中的数学解答很不相同。这些思维链更像是「内心独白」或「意识流」。你可以看到模型在不断调整思路,说一些像「另外,让我们试试」或「等等,但是」这样的话。虽然我没有直接测量过,但我敢打赌(我的心理语言学朋友们可能能够确认),思维链中的信息密度比互联网上的普通文本要均匀得多。由此可见,o1的思维链更接近「人类的思维过程」,答案是通过推理得出的。另一边,关了近一年的Sora,终于要解禁了。

Runway的联合创始人表示,有传言称,OpenAI计划在两周内发布Sora。我最担心的是,不得不听AGI领域的人在播客上谈论艺术和创造力的未来。
除此之外,OpenAI内部还有什么惊喜?毕竟,奥特曼都称AGI明年就降临了。
下一代Orion,改进不大
Information独家爆料称,下一个代号为Orion旗舰新模型,可能并不会像前代那样实现巨大的飞跃。

OpenAI员工测试后发现,尽管Orion性能超过了OpenAI现有模型,但与从GPT-3跳跃到GPT-4相比,改进幅度较小。换句话说,OpenAI模型的改善速度似乎正在放缓。事实上,Orion 在某些领域(例如编码)可能根本不会比以前的模型更好。为此,OpenAI内部已经成立了一个基础团队,以研究如何在新训练数据减少的情况下,继续改进模型。据称,这些新策略包括,在AI模型上生成的合成数据来训练Orion,以及在训练后过程中进行更多的模型改进。OpenAI副总称,「人们低估了测试时计算能力的强大:可以计算更长时间,并行计算,或任意分叉和分支 —— 就像克隆你的思维1000次并挑选最好的想法。」就是说,在AI推理阶段,我们可以通过增加计算资源来显著提升模型表现。

但有网友表示,「听说从某个前沿实验室(老实说不是OpenAI)传出消息,他们在尝试通过延长训练时间,使用越来越多数据来强行提升结果时,遇到了一个意想不到的巨大收益递减瓶颈」。

如此说来,OpenAI该如何挽救Scaling Law?














暂无评论内容