英伟达推出了自家最新430亿参数大语言模型——ChipNeMo。

对于它的用途,英伟达在官方披露消息中也是非常的明确,剑指AI芯片设计。
具体而言,ChipNeMo可以帮助工作人员完成与芯片设计相关的任务——
包括回答有关芯片设计的一般问题、总结bug文档,以及为EDA工具编写脚本等等。
英伟达首席科学家Bill Dally对此表示:
我们的目标是让英伟达的设计师更有效率。即使我们的生产率(因ChipNeMo)只提高了几个百分点,这也是值得的。

△英伟达首席科学家Bill Dally
以英伟达H100 Tensor Core GPU为例,它由数百亿个晶体管组成,在显微镜下看着就像是一个精心规划建设的城市一般。
这些晶体管连接在比人类头发丝还细10000倍的“街道”上,需要多个工程团队协作两年多的时间来完成,其间繁琐且庞大的工作量,可见一斑。

因此,在英伟达看来,随着ChipNeMo这样大语言模型的问世,所有的工作流程都将在效率上得以提升。
用Bill Dally的话来说:
这项工作标志着将大语言模型应用于半导体设计的复杂工作的重要第一步。它展示了即使是高度专业化的领域,也可以使用其内部数据来训练有用的生成式AI模型。
英伟达设计芯片有了新帮手
总体来看,ChipNeMo能够帮助英伟达内部的芯片设计师们完成三大方面的工作。
首先就是问答。
ChipNeMo包含一个原型聊天机器人,它可以回答有关 GPU 架构和设计的问题,帮助许多工程师在早期测试中快速找到技术文档。
例如,你可以向它提问:
为什么我们要添加重新计时阶段(retiming stages)?

ChipNeMo就会基于这个问题,给出精准的答案:
重新计时阶段的增加是为了改善设计的时序,并考虑到芯片不同部分之间的物理距离。通过增加重定时级,我们可以减少信号在芯片不同部分之间传输所需的时间,这有助于提高设计的整体性能。此外,重定时级还可以帮助减少信号上可能出现的噪声和干扰的数量,从而进一步提高设计的性能。
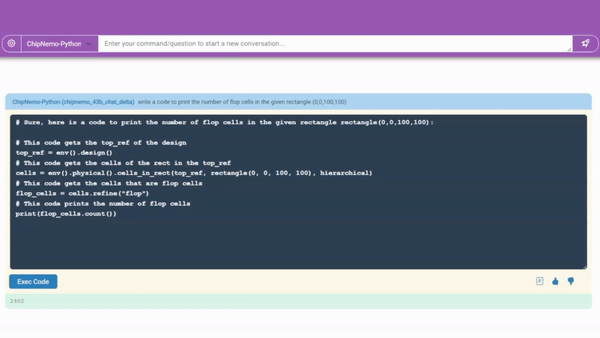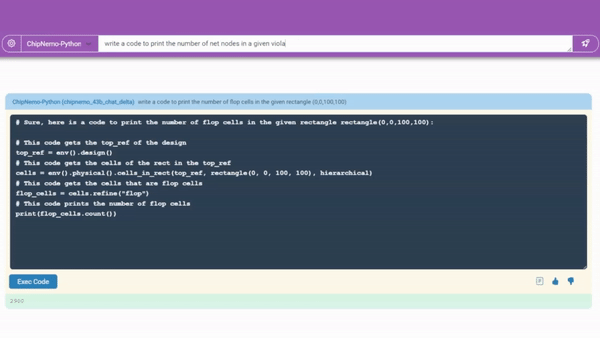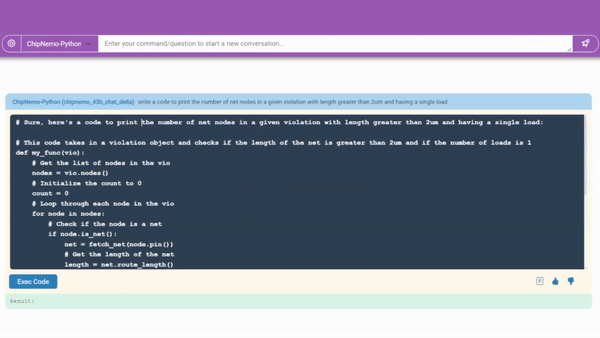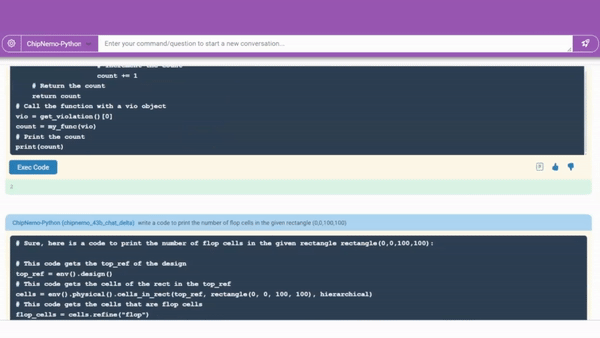
其次是DEA脚本生成。
例如只需向ChipNeMo用自然语言提出想要生成代码的要求即可:
在TOOL1中编写代码,输出给定矩形(0,0,100,100)中触发器单元的数量。

仅需静候片刻,带着注释的代码片段“啪的一下”就生成了。
据了解,英伟达目前还在对代码生成器(如下图所示)进行开发,它将来会和现有的工具做一个集成,好让工程师用起来更加方便。
最后是Bug总结和分析。
芯片设计人员只需要向ChipNeMo描述一下情况即可,例如prompt的内容可能包括Bug的ID、Synopsis、Module和Description等等。

而后ChipNeMo就会根据prompt,给出做好的技术总结和管理总结等。
ChipNeMo是怎么炼成的?
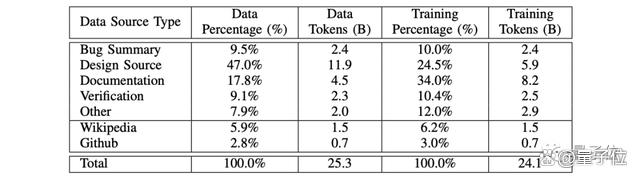
首先在数据集方面,英伟达主要采用的Bug总结、设计源(Design Source)、文档以及维基百科、GitHub等硬件相关的代码和自然语言文本。
再经过一个集中的数据采集过程来收集,最终在清洗和过滤之后,形成了241亿个token。
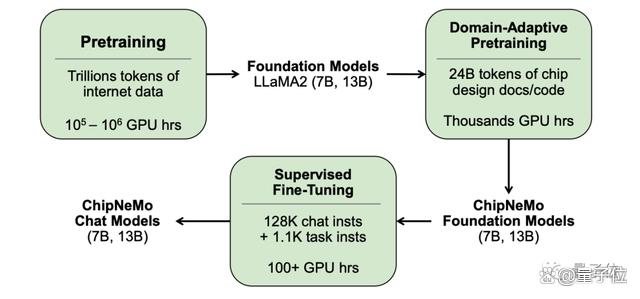
其次在算法、架构设计方面,英伟达并没有直接拿目前已商用、开源的大语言模型来做部署。
而是主要采用了这些领域自适应(Domain-Adapted)技术,包括自定义标记器、领域自适应持续预训练、带有领域特定指令的监督微调(SFT),以及领域自适应检索模型。
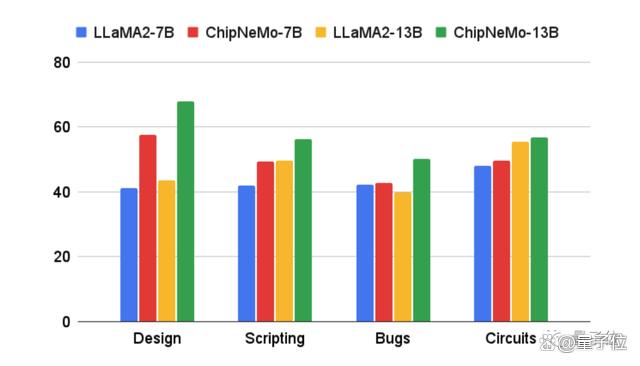
在此方法之下,便提高了大语言模型在工程助理聊天机器人、EDA脚本生成和Bug摘要和分析等三个应用中的性能。
结果显示,这些领域自适应技术使得大语言模型的性能超过通用基础模型;同时模型大小最多可减少5倍,且保持相似或更好的性能。
不过论文作者也坦言:
虽然目前的结果已经取得了一些进展,但与理想结果之间仍存在改进空间。进一步研究领域适应的LLM方法将有助于缩小这一差距。














暂无评论内容