
本文将分析大语言模型训练的GPU内存需求,主要包括三个方面:训练数十亿参数基于Transformer的LLM时,每个GPU设备需要多少GPU内存;估算内存需求的公式是什么;如果模型无法匹配内存,在实践中应采取哪些措施来减少内存需求。
1
是什么占用了GPU内存?
这是当我在首次训练一个数十亿参数的LLM时,一看到错误就立刻问自己的第一个问题:
RuntimeError: CUDA out of memory(运行时错误:CUDA内存不足)
我敢打赌,每个机器学习工程师都见过这个报错成千上万次。在深度学习模型的早期时代(例如VGG或ResNet),常见解决方案是减少batch_size并使用gradient_accumulation_steps。
不幸的是,现在,当我们处理LLM时,找出错误的根源已经不再容易。
想象一下,你有一个10B参数(或权重)的模型。在16位精度下,它需要占用20GB的内存。这在任何流行的GPU上训练模型都绰绰有余:V100(拥有32GB的GPU内存)或A100(拥有40GB的GPU内存)。然而,即便如此,这样的模型也无法在单个GPU上使用TensorFlow或PyTorch进行训练。你可能会感到惊讶,但你甚至无法在32GB的GPU内存上训练一个1.5B的GPT模型。那么,内存究竟去了哪里?
在模型训练过程中,大部分内存被以下两件事占用:
- 模型状态:包括优化器状态、梯度和参数的张量。
- 激活:包括在前向传播中创建的任何张量,这些张量在反向传播期间用于梯度计算。
在接下来的部分中,我将解释每个组件需要多少内存,并给出可以在实践中使用的近似公式。
模型状态:优化器状态、梯度和参数
探索模型状态的内存消耗是微软ZeRO论文《面向训练万亿参数模型的内存优化》(https://arxiv.org/pdf/1910.02054v3)中的关键话题。作者们探讨了使用最流行的Adam优化器进行模型训练的内存需求。在实践中,这意味着在训练的任何时刻,对于每个模型参数,我们都需要足够的GPU内存来存储:
- 用于模型参数副本的p字节
- 用于梯度副本的p字节
- 用于优化器状态的12字节:参数副本、动量和方差(我们保留所有优化器状态为FP32,以保持稳定训练并避免数值爆炸)
总的来说,这意味着在训练过程中,我们需要下图所示的内存来存储所有模型状态:
(p+p+12)*model_size
其中,p是每个参数的精度(以字节为单位),通常为2或4,model_size是模型的大小(以十亿为单位)
如果我们有一个10B参数的模型,并且在混合精度模式下进行训练(此时p为2),我们将需要存储160GB的GPU内存。
这比A100 GPU的容量还要大。想象一下,如果你想在全FP32模式下训练(此时p为4)——那简直不敢想!
幸运的是,我们有一个有效的工程解决方案来缩小这个数字——模型状态分区,它可以将模型状态分布到多个GPU上。对于机器学习工程师来说,这在DeepSpeed库中更为人熟知,被称为零冗余优化器(ZeRO),或在Torch 2.x中称为FSDP。我将在后文中统一使用ZeRO,因为它是第一个成功的模型状态分片框架示例。
ZeRO通过将不同的模型训练状态分配到可用设备(GPU和CPU)上,降低了每个GPU的内存消耗。具体而言,ZeRO作为逐步优化的阶段来实现的,其中早期阶段的优化可在后期阶段中使用。想要深入了解ZeRO,请参阅论文:https://arxiv.org/abs/1910.02054v3
该库支持3个阶段:
阶段1:优化器状态在各个进程之间进行分区,因此每个进程只更新其对应的分区。
因此,模型状态的内存需求将变为:

阶段2:用于更新模型权重的梯度也会被分区,每个进程仅保留与其优化器状态部分对应的梯度。
因此,模型状态的内存需求将变为:

阶段3:模型参数在各个进程之间进行分区。ZeRO-3将在前向和后向传播过程中自动收集和分区模型参数。
因此,模型状态的内存需求将变为:
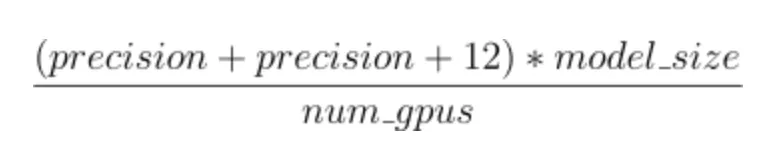
我们将在最终公式中使用这个分阶段内存优化方法来了解每个GPU设备所需的内存量。
激活
在前一节中,我们估算了仅存储模型及其训练状态所需的GPU内存量。但我们还需要存储每个模型层的所有中间输出,以便在反向传播步骤中更新模型权重。乍一看,这似乎微不足道,不过……
在论文《减少大型Transformer模型的激活再计算(Reducing Activation Recomputation in Large Transformer Models,https://arxiv.org/pdf/2205.05198)》中,Nvidia的研究人员推导出了一个近似公式,用于计算单个堆栈Transformer模型的前向传播中存储激活值所需的内存。我将使用论文作者相同的符号,并解释他们是如何推导出这个公式。
首先,让我们看看传统的Transformer块是什么样的:
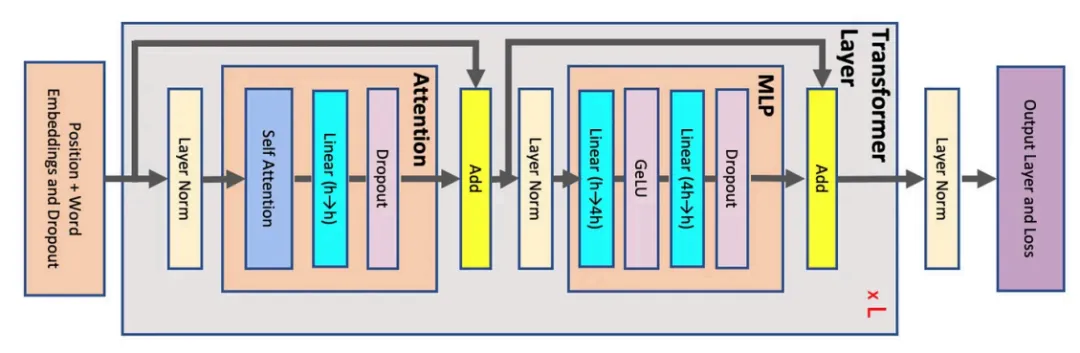
图源:“Reducing Activation Recomputation in Large Transformer Models”(https://arxiv.org/pdf/2205.05198)。该图表示Transformer架构。每个灰色块表示被复制了L次的单个Transformer层。
现在,让我们引入一些符号:

有了这些符号后,让我们分解一下每个组件所需的内存。
在这里和下文中,psbh表示 p * s * b * h,
首先从MLP部分开始:
- 我们需要存储第一个Linear层的输出,这需要4 psbh字节(输入到该层将需要psbh字节,Linear层会将输出宽度扩大4倍)
- 我们需要存储GeLU层的输出,这需要4 psbh字节
- 我们需要存储第二个Linear层的输出,这需要psbh字节
- 我们需要存储dropout掩码,这需要sbh字节(我们将在反向传播中使用dropout掩码,这里不引入精度因子p,因为掩码是二进制的)
因此,MLP部分总共需要存储:9psbh + sbh字节的激活值。
让我们来分析一下注意力机制部分。
在这里,我们需要存储:
自注意力(Self-Attention)的中间输出(将单独讲解)
自注意力的输出,这需要psbh字节
线性层的输出,这也需要psbh字节
Dropout掩码(在反向传播过程中我们需要使用掩码,且由于掩码是二进制的,因此这里不引入精度因子p),这需要sbh字节
接下来,分析最后一个模块——自注意力。
自注意力的公式如下:
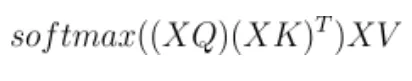
因此,我们需要存储:
psbh字节用于存储XQ的输出
psbh字节用于存储XK的输出
psbh字节用于存储XV的输出
我们还需要存储softmax操作的输出。在标准的自注意力机制中,(XQ)*(XK)^T的结果是一个包含了logits的b x s x s的矩阵。然而,实际上我们使用的是多头自注意力机制,因此每a个头的logits都会单独存储一个s x s的矩阵。这意味着,我们需要pas²b字节来存储这些logits。接下来,我们需要存储softmax的输出,这将再次需要 pas²b字节。最后,softmax后通常会应用dropout,因此我们还需要额外的as²b字节来存储dropout掩码。
总结一下,注意力部分需要存储的总字节数是:5psbh+sbh+2pas²b+as²b字节。
此外,Transformer层中还有两个归一化层,每个层的输出都需要存储psbh字节,因此总共需要存储2psbh字节。
现在,我们可以得到激活值的最终公式。只需将上述内容加总起来,经过一些简化后,存储激活值所需的总字节数大约为:
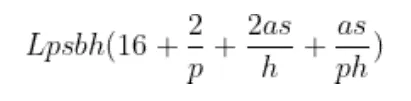
Transformer模型所需存储激活值的总字节数
接下来,我们编写一个简短的Python函数来根据架构自动计算所需存储的字节数:
def activations_memory(num_layers, seq_len, batch_size, hidden_dim, num_heads, precision=2):”Returns amount of GPU VRAM (in GB) required to store intermediate activations for traditional Transformer Encoder block” mem_bytes = num_layers * precision * seq_len * batch_size * hidden_dim * (16 + 2/precision + 2*num_heads*seq_len/hidden_dim + num_heads*seq_len/(precision*hidden_dim))return round(mem_bytes / 10**9, 2)
这个函数将计算存储定义的Transformer架构的激活值所需的GPU内存(以GB为单位)。
通常,当我们处理某个知名模型并希望在自定义数据上进行训练或微调时,我们通常不会改变架构,因此可以调整的关键参数就是批处理大小。
接下来,让我们看看如果使用一块GPU并且批处理大小不同,10B模型XLMRoBERTa-XL(https://huggingface.co/facebook/xlm-roberta-xxl) 的激活值内存会发生什么变化:
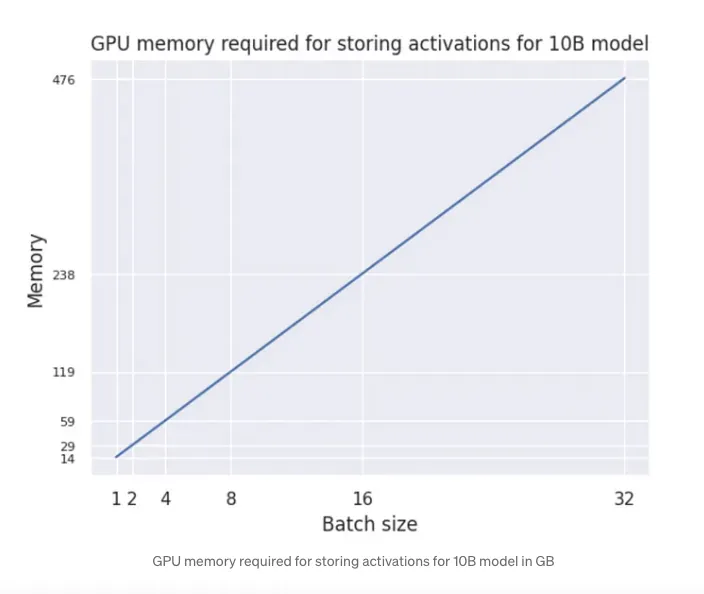
10B模型存储激活值所需的GPU内存(单位:GB)
虽然关系是线性的,但内存需求增长得非常快!那么我们该如何应对这种情况?
幸运的是,我们可以使用激活检查点技术(activation checkpointing)。通过这种技术,如果我们只在需要时重新计算中间张量,而不是保存这些用于反向计算的中间张量。论文《以次线性内存成本训练深度神经网络(Training Deep Nets with Sublinear Memory Cost,https://arxiv.org/abs/1604.06174)》表明,通过这种方法,我们可以将内存需求减少到大约是总激活总值的平方根,代价是增加了约33%的重新计算开销。
使用激活检查点技术后,激活所需的GPU内存大致为:
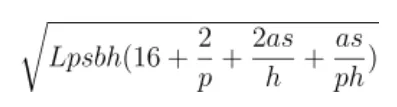
2
理解和估算训练LLM所需的GPU内存
在前面的部分中,我们推导了一些公式,帮助我们理解在训练大型语言模型时GPU内存会发生什么变化。
在这里,我将给出一个高层次的操作步骤列表,帮助ML工程师了解在训练自己的LLM时,硬件需求是怎样的。
- 了解可用的GPU加速器类型,具体来说,要了解数量。
- 获取模型的大小,并计算存储模型状态所需的GPU内存。在这一阶段,可能已经可以开始考虑ZeRO阶段。
- 获取详细的模型规格(例如配置文件)并进行分析。这将帮助我们建立对激活内存需求的直觉。此时,可以对批处理大小、是否使用激活检查点等做出直观的判断。
- 最终,得出一个合适的数字并进行简单的训练测试,以验证其是否符合估算结果。
下面的代码片段对于进行高层次的数学计算非常有用:
def activations_memory(num_layers, seq_len, batch_size, hidden_dim, num_heads, precision=2):”Returns amount of GPU VRAM (in GB) required to store intermediate activations for traditional Transformer Encoder block” mem_bytes = num_layers * precision * seq_len * batch_size * hidden_dim * (16 + 2/precision + 2*num_heads*seq_len/hidden_dim + num_heads*seq_len/(precision*hidden_dim))return round(mem_bytes / 10**9, 2)
def gpu_memory_required(model_size, num_gpus, num_layers, seq_len, batch_size, hidden_dim, num_heads, precision=2, activations_checkpoint=False, stage=0): model_in_memory = (precision + precision + 12) * model_size print(f’In default mode model states would have taken: {model_in_memory} GB’) if stage == 0: model_in_memory = (precision + precision + 12) * model_sizeelif stage == 1: model_in_memory = precision * model_size + precision * model_size + (12 * model_size) / num_gpuselif stage == 2: model_in_memory = precision * model_size + (precision +12) * model_size / num_gpuselif stage == 3: model_in_memory = (precision + precision + 12) * model_size / num_gpuselse:raise ValueError print(f’Stage {stage} selected, model states would require {model_in_memory} GB’)
activations = activations_memory(num_layers, seq_len, batch_size, hidden_dim, num_heads, precision) print(f’Model activations would require {activations} GB without activations checkpointing’)if activations_checkpoint: activations = activations ** 0.5 print(f’Activations checkpointing is enabled, activations would require {activations} GB’)
return activations + model_in_memory
假设我想训练XLM-RoBERTa-XL模型。这是一个10B模型。模型的配置文件,包括隐藏层维度、注意力头数量等信息,可以在这里找到(https://huggingface.co/facebook/xlm-roberta-xxl/blob/main/config.json)。
接下来,我需要理解内存需求。为了简化问题,我将批处理大小固定为8,并使用64个GPU。
考虑到这些,我可以在不同的设置下运行上面的代码片段,得到像这样的表格:
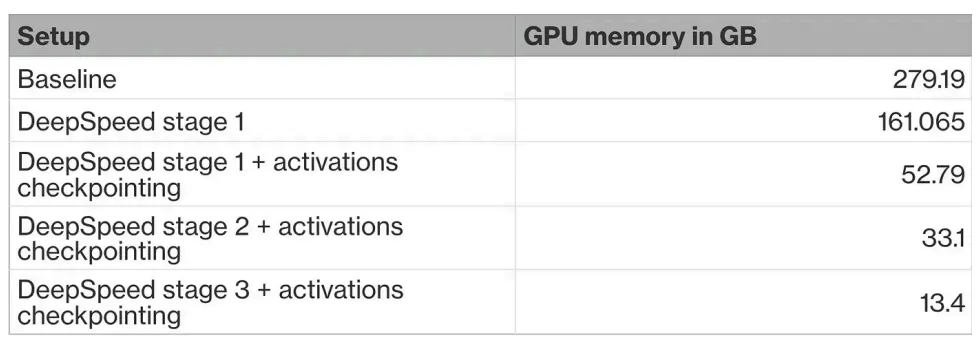
从这张表格可以看出,单纯通过模型状态分片(使用DeepSpeed第一阶段)是不够的,我还需要使用激活检查点技术。即便如此,还不足以应对,需要要么减少批处理大小(并使用gradientaccumulation),要么升级到DeepSpeed第二阶段。此时,使用A100 GPU进行训练变得可行(如果使用更小的GPU,还需要进一步调整训练超参数),我几乎可以像使用标准DDP(分布式数据并行)一样高效地训练大型LLM。最后,升级到DeepSpeed第三阶段是最后的选择,这将大幅减少内存占用,并对训练速度产生巨大影响。或者,也可以使用量化技术在较低精度下进行训练,从而释放额外的内存,或者尝试CPU离线加载,但这些都超出了本文的范围。
















暂无评论内容