LLM 自我训练取得重大进展!
大型语言模型(LLM)在各种自然语言任务中取得了显著成功,但其推理能力仍有巨大的提升空间。现有的LLM自我训练方法大多依赖于LLM生成的响应,并筛选具有正确输出答案的样例作为训练数据。然而,这种方法通常会导致低质量的微调训练集,因为即使最终答案正确,中间的推理过程也可能存在错误或无效步骤。这限制了LLM在复杂推理任务中的最终性能
为了解决这个问题,清华智谱研究人员提出了一种名为ReST-MCTS* 的新型强化自我训练方法

清华智谱新方法 ReST-MCTS* 解决了扩展中的一个关键限制:
由于中间步骤 “有问题”,许多当前的自我训练方法在低质量的微调数据中举步维艰,从而限制了 LLM 在复杂任务中的应用。ReST-MCTS* 利用蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)进行强化学习,在无需大量人工标注的情况下,引导模型生成可靠的推理路径,并获得高质量的训练数据。通过估算每一步正确答案的概率,它可以创建高质量的训练轨迹,在每次迭代中提升 LLM 性能
ReST-MCTS* 将过程奖励引导与树搜索MCTS*算法相结合,用于收集高质量的推理轨迹以及每一步的价值,以训练策略模型和奖励模型
ReST-MCTS* 的核心思想及优势:
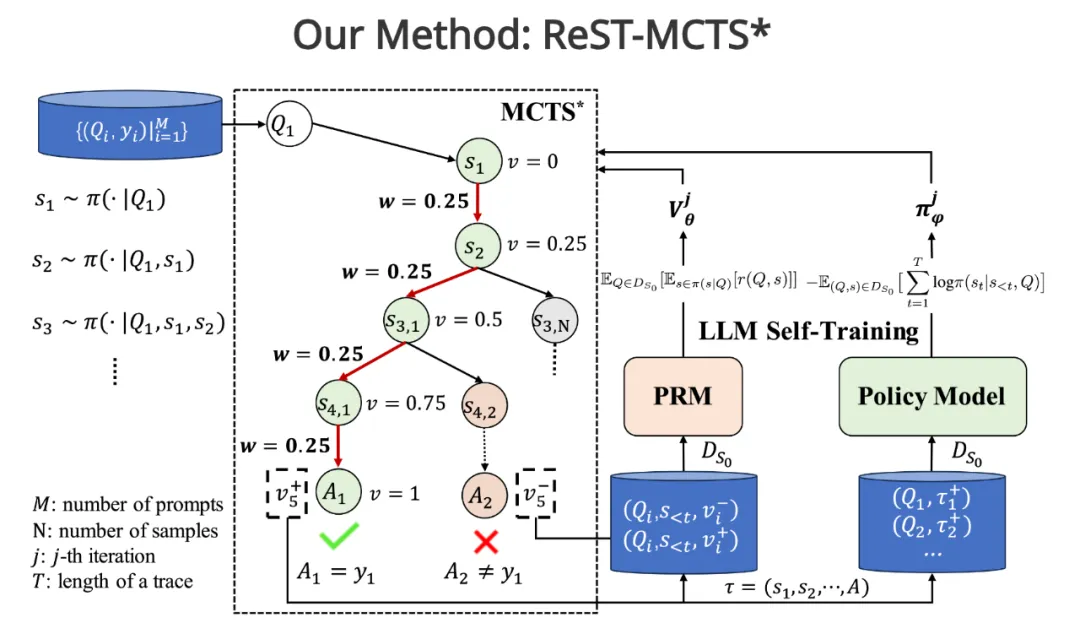
左侧部分:推断过程奖励的过程,以及如何进行过程奖励引导树搜索。右侧部分:表示过程奖励模型和策略模型的自我训练
过程奖励引导的树搜索: ReST-MCTS* 使用经过训练的每步过程奖励(价值)模型来引导改进的蒙特卡洛树搜索(MCTS*)算法。该算法会在搜索树中探索不同的推理路径,并根据过程奖励模型的评估来选择最有希望的路径。
自动生成过程奖励标签: ReST-MCTS* 的一个关键创新在于能够自动生成每步训练过程奖励模型所需的标签。它通过执行足够数量的 rollout(从当前状态模拟到最终状态),并根据 rollout 的结果来推断每一步对最终答案的贡献。这种自动标注方法有效地过滤掉了质量最高的样本子集,无需额外的人工干预。
避免传统方法的局限性: 传统的自我训练方法通常只关注最终答案的正确性,而忽略了中间推理步骤的质量。ReST-MCTS* 通过使用过程奖励来评估每一步的质量,从而解决了这个问题。即使最终答案正确,如果中间步骤存在错误或低效,也会得到较低的奖励。这鼓励模型学习更准确、更有效的推理路径。
双重用途的奖励信号: 推断出的奖励具有双重用途:它们既可以用作价值目标来进一步改进过程奖励模型,也可以用来选择高质量的轨迹用于策略模型的自我训练。这种双重用途最大限度地利用了奖励信号,提高了训练效率。
ReST-MCTS* 的组成部分:
1. MCTS * 搜索算法: 在过程奖励模型的指导下进行高效的树搜索
2. 过程奖励模型(PRM): 评估部分解决方案的质量,并指导 MCTS* 的搜索过程
3. 策略模型: 为每个问题生成多个中间推理步骤
4. LLM 自我训练: 使用 MCTS* 收集推理轨迹,在正样本上训练策略模型,并在所有生成的轨迹上训练过程奖励模型
实验结果:
实验结果表明,ReST-MCTS* 在多个方面优于现有方法:
• 在自我训练方面,ReST-MCTS* 在多次迭代中均优于 ReSTEM 和 Self-Rewarding 等方法
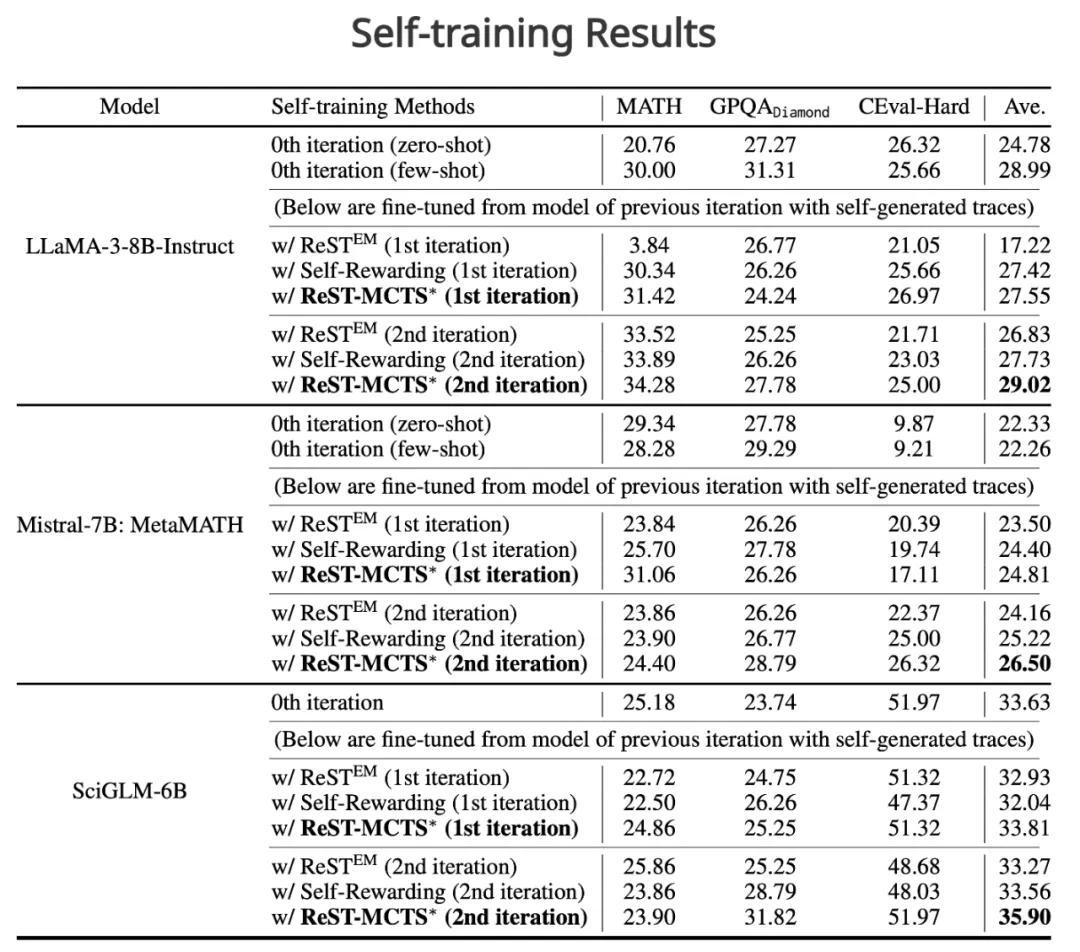
• 在过程奖励模型方面,ReST-MCTS* 优于 MATH-SHEPHERD 和 Self-Consistency + MATH-SHEPHERD 等现有技术
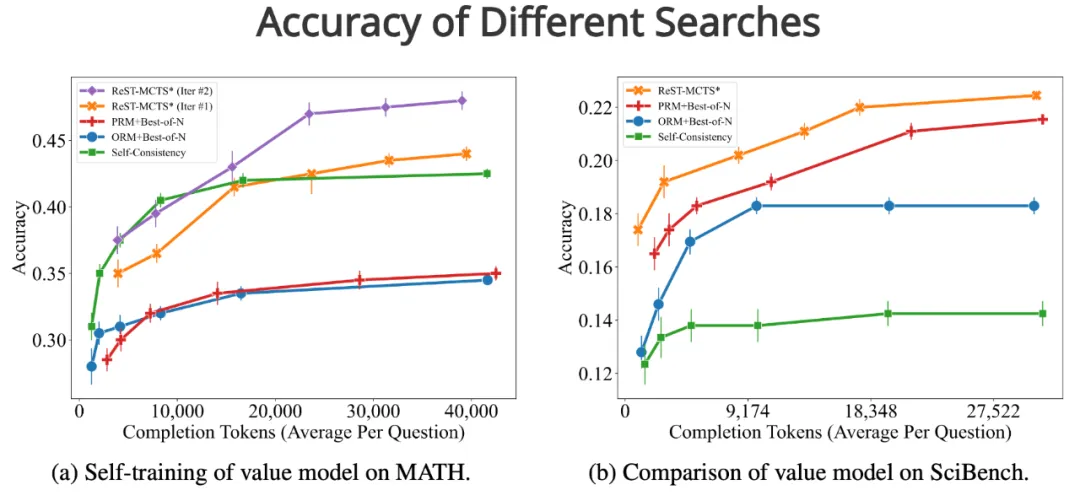
• 在推理策略方面,ReST-MCTS* 在相同的搜索预算下,比 Self-Consistency 和 Best-of-N 等基线模型实现了更高的准确性














暂无评论内容