
北京大学最近提出了一种可以在文本到图像的基础模型中插入适配器,让它们能够执行复杂的下游任务,同时保持模型的泛化能力的方法HelloMeme。这个方法的核心思想是优化与二维特征图相关的注意力机制,从而提升适配器的性能。HelloMeme在生成表情包视频的任务上验证了该方法,取得了显著效果。这种方法与 SD1.5 派生模型兼容性良好,对开源社区也有一定的价值。 简单来说,HelloMeme方法相当于给图像生成模型加上了“插件”,帮助它在不影响原有功能的前提下,完成更复杂的任务,比如生成图片、生成视频、替换表情。但其也存在问题,生成视频的帧连续性不如基于GAN的方案。模块与风格化的SD1.5派生模型结合时,会显著削弱图像的风格特征
01 技术原理—
HelloMeme解决方案包括三个模块,每个模块分工明确,配合完成高清动画视频的生成。
1. HMReferenceNet:这个模块负责从参考图像中提取“高清特征”,帮助保留图像的清晰度和细节。
2. HMControlNet:该模块提取整体的面部信息,比如头部姿势和表情,以便后续处理。
3. HMDenoisingNet:这个模块是核心,接收前两个模块提供的特征并完成主要的去噪任务。同时,它还可以与一个经过微调的“Animatediff”模块结合,用于生成连续的动画视频帧。
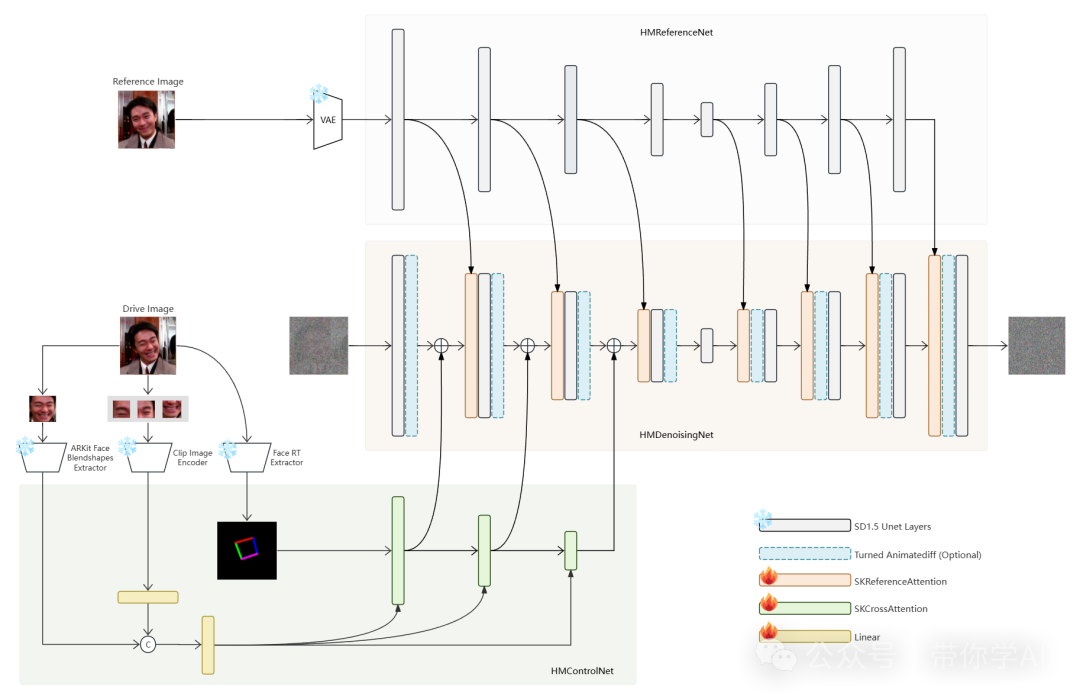

如果从驱动视频的每一帧中提取特征,并将这些特征输入到 HMControlModule,可以生成一个视频,但帧与帧之间可能会出现闪烁的问题。为了解决这个问题,引入了Animatediff模块,从而改善了视频的连续性,但也稍微牺牲了一些清晰度。于是,对 Animatediff模块进行了进一步微调,使生成的视频在保持连续性的同时,也能更好地保持画质。
02 实际效果—
表情编辑:HMControlModule的输入条件可以由一个绑定了ARKit面部混合形状(Face Blendshapes)的头部模型生成。因此,可以使用ARKit的混合形状值来控制面部表情的生成。
基于SD1.5的LoRA或Checkpoint:HelloMeme框架是一个热插拔适配器,建立在SD1.5之上,不会削弱文本到图像模型本身的泛化能力。因此,任何基于SD1.5基础开发的风格化模型都可以与HelloMeme无缝集成。
借助LCM:一个意外的好处是,由于HMReferenceModule引入的高保真条件,可以在较少的采样步骤中实现高保真结果。














暂无评论内容