
最近,视频生成领域取得了显著进展,开源社区贡献了大量研究论文和工具,用于训练高质量的模型。然而,尽管有这些努力,现有的信息和资源仍不足以达到商业级的性能。日本初创公司Rhymes开源了文生视频模型Allegro,这是一种在质量和时间一致性方面表现出色的先进视频生成模型。Allegro在性能上超越了现有的大多数开源模型和商业模型,仅次于Hailuo和Kling。Allegro使用户能够从简单的文字提示生成高质量的6秒视频,视频的帧率为15帧每秒,分辨率为720p。这样的质量水平可以高效地创造出各种电影主题,从详细的特写镜头到不同场景中动物的动态表现,几乎可以根据文字描述想象出任何场景。
技术原理—
该模型的能力基于核心技术,这些技术用于处理视频数据、压缩原始视频和生成视频帧,使得文字提示能够转化为短视频片段。1. 大规模视频数据处理:为了创建一个能够生成多样化和逼真视频的模型,需要一个系统来处理大量的视频数据。为此,Allegro设计了系统化的数据处理和过滤流程,从原始数据中提取训练视频。这个过程是按步骤进行的,包括以下几个阶段:
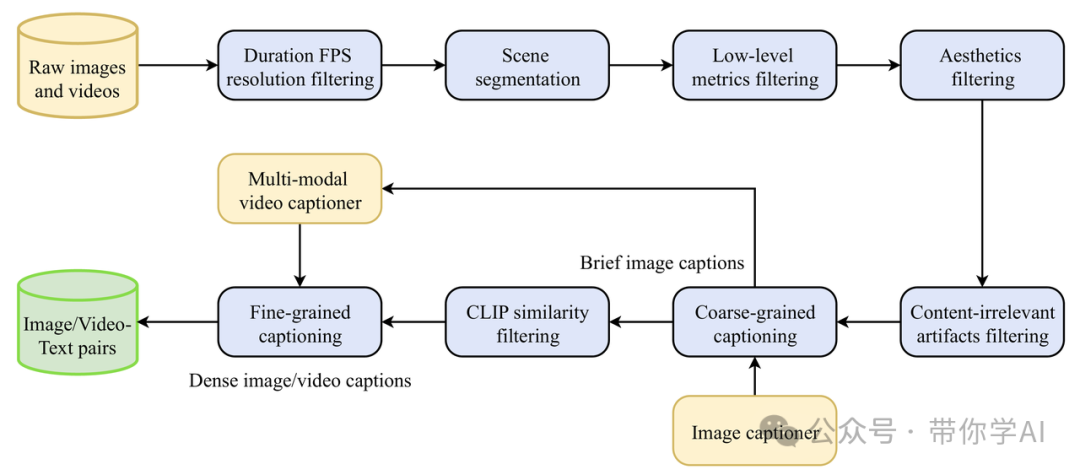
接下来,基于处理过程中获得的指标,Allegro开发了一个结构化数据系统,可以对数据进行多维分类和聚类,从而方便模型的训练和调整,以适应不同的阶段和目的。
2. 将视频压缩为视觉标记:视频生成中的一个关键挑战是处理大量的数据。为了解决这个问题,Allegro将原始视频压缩成更小的视觉标记,同时保留重要细节,从而实现更流畅、更高效的视频生成。
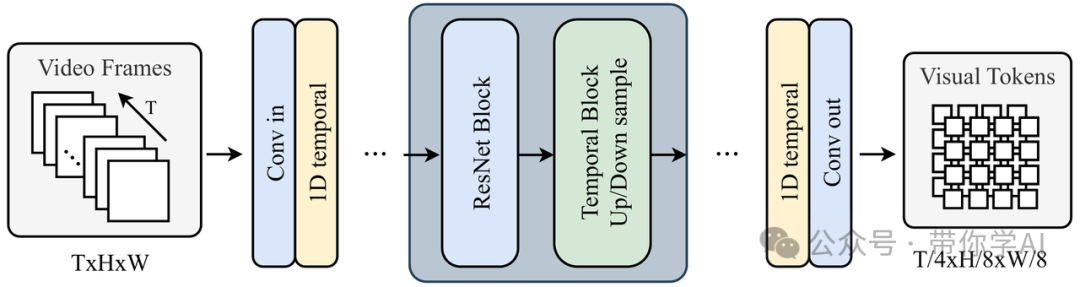
具体来说,Allegro设计了一个视频变分自编码器(VideoVAE),它将原始视频编码为时空潜在空间。VideoVAE基于预训练的图像VAE,并扩展了时空建模层,以有效利用空间压缩能力。
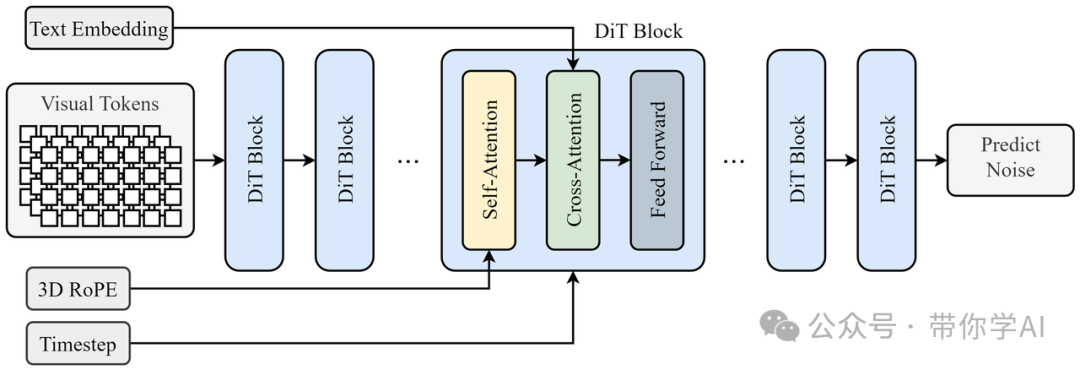 3. 扩展视频扩散Transformer:Allegro视频生成能力的核心在于其扩展的扩散Transformer架构,这种架构利用扩散模型生成高分辨率的视频帧,确保视频运动的质量和流畅性。Allegro的主干网络基于DiT(扩散Transformer)架构,采用了3D RoPE位置嵌入和3D全注意力机制。这种架构能够高效捕捉视频数据中的空间和时间关系。
3. 扩展视频扩散Transformer:Allegro视频生成能力的核心在于其扩展的扩散Transformer架构,这种架构利用扩散模型生成高分辨率的视频帧,确保视频运动的质量和流畅性。Allegro的主干网络基于DiT(扩散Transformer)架构,采用了3D RoPE位置嵌入和3D全注意力机制。这种架构能够高效捕捉视频数据中的空间和时间关系。














暂无评论内容