多模态大型语言模型(MLLMs)在理解和分析视频内容方面取得了显著进展。然而,处理长视频仍然是一个重要挑战,因为受限于上下文长度。为了解决这个问题Meta和智普纷纷开源了最新的长视频理解技术LongVU与Video-XL,目前智普的素材视频没有全面公布,之前开源的视频生成模型效果也不是很好,因此本文重点介绍LongVU。LongVU提出了一种时空自适应压缩机制,旨在减少视频中的标记数量,同时保持长视频的视觉细节。LongVU的自适应压缩策略能够在有限的上下文长度内,有效处理大量帧,并且几乎不损失视觉信息。下边的视频可以看出LongVU可以很好的理解视频中物体的颜色和移动,以及对视频中故事内容的阐述和理解。
技术原理—
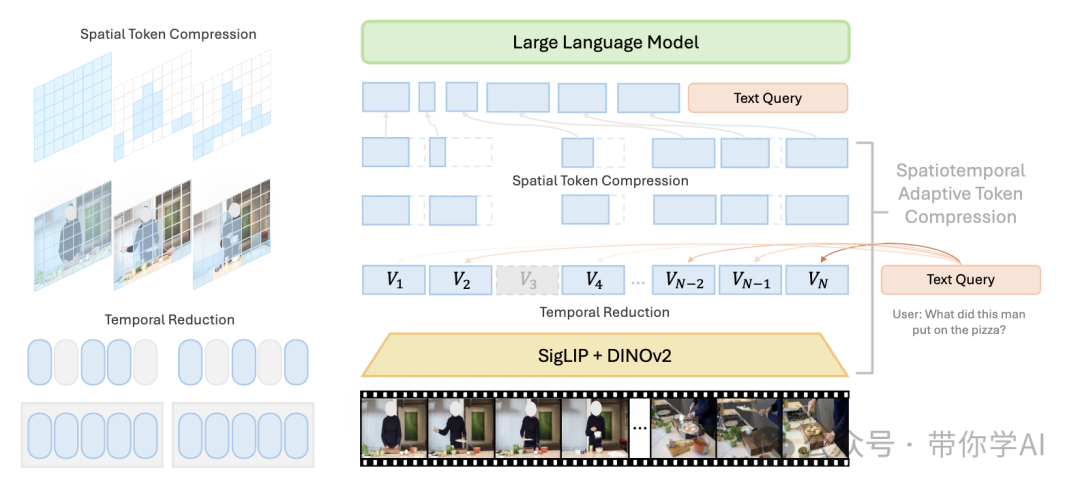
LongVU的架构设计如下:针对密集采样的视频帧,LongVU首先使用DINOv2技术去除冗余帧,然后融合剩余帧的特征,这些特征来自SigLIP和DINOv2。接下来,通过跨模态查询选择性地减少视觉标记。最后,根据时间依赖关系进行空间标记压缩,以进一步适应大型语言模型(LLMs)的有限上下文长度。
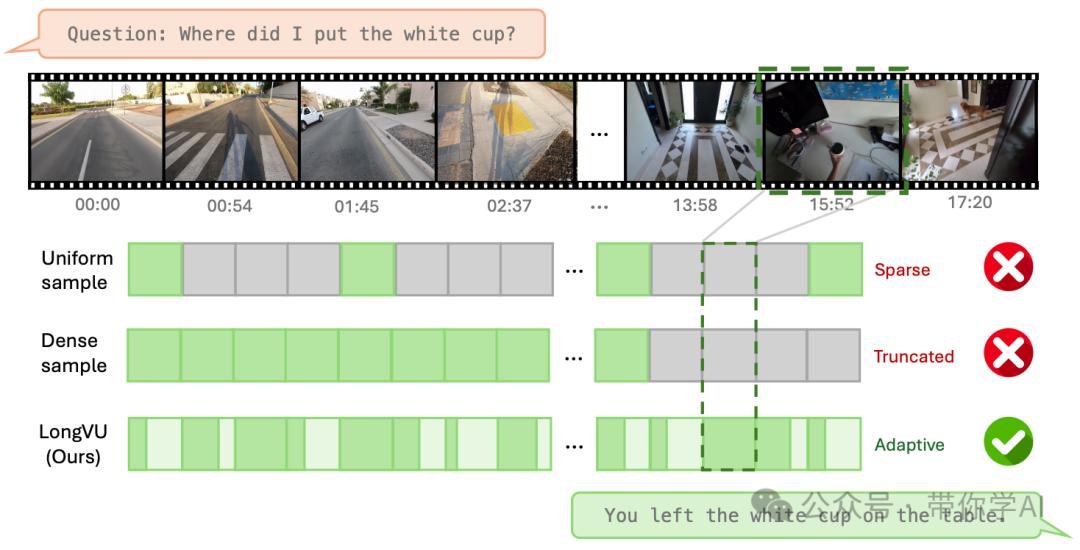
LongVU在常用的均匀采样和密集采样方法上表现出了明显的优势。均匀采样由于其稀疏特性,往往忽视了关键帧,而密集采样则可能超出最大上下文长度,导致目标帧的标记被截断。相比之下,LongVU可以自适应地进行时空压缩,能够处理长视频序列,同时更好地保留视觉细节。
LongVU提出了三步时空自适应压缩方案,以有效处理长视频。首先,利用DINOv2中的先验知识对帧序列实施时间减少策略。然后,通过跨模态查询,选择性地保留关键帧的完整标记,同时对剩余帧应用空间池化,将其简化为低分辨率的标记表示。最后,基于帧间的时间依赖关系实施空间标记减少机制。
© 版权声明
THE END














暂无评论内容