Amphion 是一个音频、音乐和语音生成的工具包,旨在支持可重复的研究,并帮助初学者和工程师入门这方面的研究和开发。Amphion 目前支持以下功能:文本转语音(TTS)和歌声转换(SVC)。文本转音频(TTA)也已支持。正在开发中的功能包括歌唱声音合成(SVS)、语音转换(VC)和文本转音乐(TTM)。Amphion推出了一种新的非自回归 TTS 模型,称为掩码生成编码器变换器(MaskGCT)。该模型不需要在文本和语音之间进行明确的对齐,也不需要预测音素级的持续时间。简单来说,MaskGCT 是一种新型的文本转语音技术,它能在没有明确对齐信息的情况下生成高质量的语音,且不需要提前预测每个音的持续时间。通过新的学习方法和模型结构,它在多个方面表现优于现有技术。
技术原理—
最近的大规模文本到语音(TTS)系统通常分为自回归和非自回归系统。自回归系统在建模时会隐含地考虑语音持续时间,但在稳健性和持续时间控制方面存在一些不足。非自回归系统在训练过程中需要文本与语音之间的明确对齐信息,并预测语言单位(例如音素)的持续时间,这可能影响生成语音的自然性。

MaskGCT系统主要由四个部分组成:语音语义表示编码器:将语音转换为语义标记;文本到语义模型:根据文本和提示的语义标记预测语义标记;语义到声学模型:根据语义标记预测声学标记;语音声学编码器:从声学标记重建语音波形。
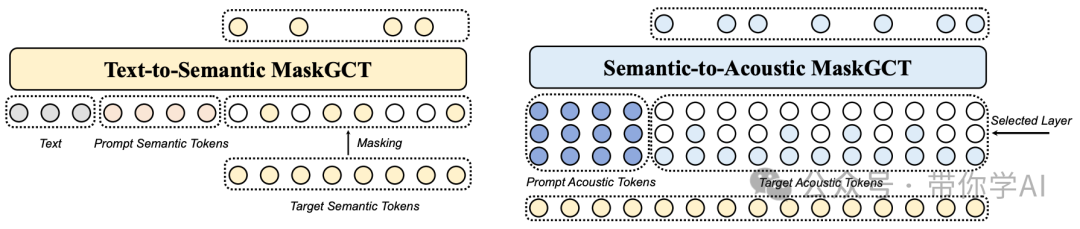
MaskGCT 是一个两阶段的模型:在第一阶段,模型根据文本预测从语音自监督学习(SSL)模型中提取的语义标记;在第二阶段,模型基于这些语义标记预测声学标记。
MaskGCT 采用了掩码和预测的学习方式。在训练过程中,MaskGCT 学习如何根据给定条件和提示来预测被掩盖的语义或声学标记。在推理阶段,模型能够并行生成指定长度的标记。














暂无评论内容