
抄抄抄!Meta也抄起来了:开源版播客模型NotebookLlama来了
前段时间谷歌推出了播客模型NotebookLM,AI大神Andrej Karpathy连连点赞(关于谷歌NotebookLM可以看我之前写的这篇
Andrej Karpathy 强推谷歌NotebookLM 的播客功能:堪比ChatGPT的推出)
刚刚Meta推出了对标谷歌NotebookLM开源版本NotebookLlama,它让你用LLaMa模型把PDF直接变成播客!
体验地址:
https://huggingface.co/spaces/gabrielchua/open-notebooklm
NotebookLlama核心流程是这样的:
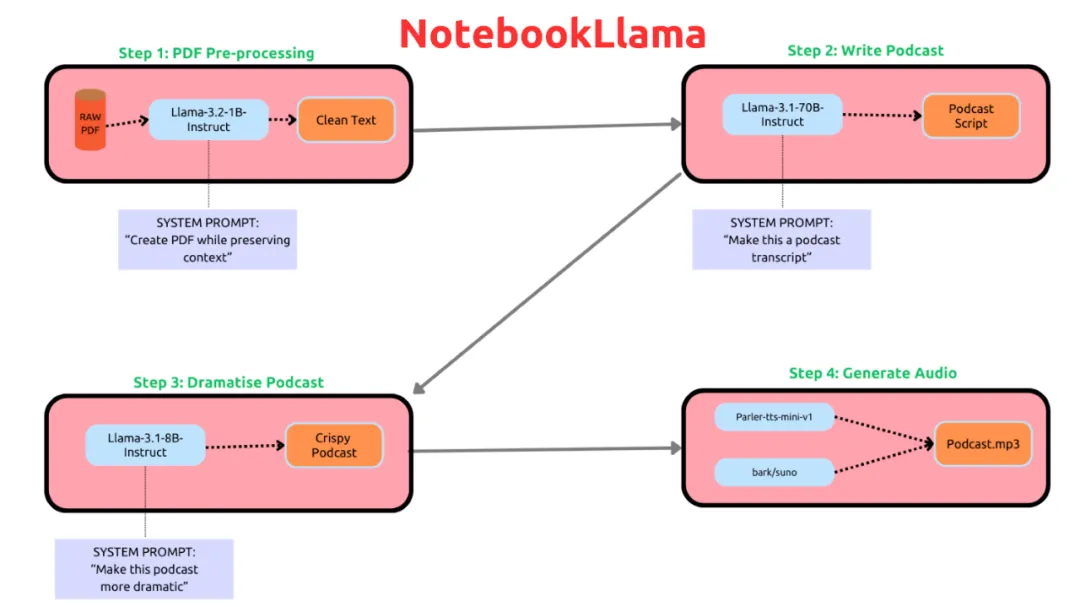
1B轻量级选手——预处理PDF: 就像一个勤劳的清洁工,把PDF里的乱七八糟字符、编码错误什么的都清理干净,省得后面出幺蛾子。这步用了Llama-3.2-1B-Instruct模型,重点是只清理垃圾,不改内容,不总结概括
70B重量级选手——写播客稿: 这才是真正的主力输出!用Llama-3.1-70B-Instruct模型,直接把文本变成播客稿,创意直接拉满!当然,如果你觉得70B太壕,太吃显存,也可以用Llama-3.1-8B-Instruct模型,作者也推荐大家多试试,看看哪个效果更好。据说70B模型写出来的播客稿更具创意
8B调味大师——戏剧冲突MAX: 播客稿写好了,还得加点儿戏剧冲突才够味儿!Llama-3.1-8B-Instruct模型负责把稿子变得更刺激,更引人入胜!更重要的是,它返回的是对话元组,方便后续的TTS处理,数据结构101终于派上用场了!为了适配不同的TTS模型,还需要在prompt里针对每个speaker做一些特定的设定
语音合成终极大杀器: 最后,用parler-tts/parler-tts-mini-v1和bark/suno模型把文字变成声音,完美!这里用到了两个不同的TTS模型,speaker和prompt都是经过反复实验和模型作者建议才确定的。作者也鼓励大家多多尝试,说不定能找到更好的组合!需要注意的是,Parler需要transformers 4.43.3或更早版本,而前面的步骤需要最新版本,所以在最后一个notebook里需要切换版本
敲黑板!重点来了!
你需要一个GPU服务器或者API provider来跑70B、8B和1B的LLaMa模型。70B模型需要大约140GB的显存 (bfloat-16精度)
运行之前,先用huggingface-cli登录,然后启动jupyter notebook server,确保能下载LLaMa模型。需要Hugging Face的access token
先clone仓库,安装依赖:
git clone https://github.com/meta-llama/llama-recipes && cd llama-recipes/recipes/quickstart/NotebookLlama/ && pip install -r requirements.txt
每个notebook都有详细的说明和建议,鼓励大家修改prompt,尝试不同的模型,看看哪个效果最好!
未来展望:
• TTS模型的自然度还有提升空间
• 可以用两个agent辩论的方式来写播客大纲
• 可以用405B模型写稿
• 优化prompt
• 支持更多输入格式,比如网站、音频文件、油管链接等














暂无评论内容