始智AI wisemodel.cn社区是源自中国的中立开放的AI开源社区。正在招募 | 新一期开源共创志愿者计划,欢迎加入共同成长。wisemodel社区算力平台上线,H800/H20等资源上线,价格实惠,灵活方便,支持在线微调训练模型,及模型在线体验和专属API服务,并全面支持ollama在线运行。
01
引言
从DeepMind发布的AlphaCode在竞赛级编程能力上超越人类平均水平之日起,代码大模型便广受关注。与此同时,OpenAI发布的CodeX更是展示出了代码大模型具有超越传统编程范畴的数值推理、逻辑推断、工具调用等高阶能力,进一步引爆了对该领域的研究与讨论。以BigCode StarCoder为代表的开源项目对完善该领域的研究生态做出了卓越的贡献。然而,目前开源代码大模型提升编程能力的同时会严重损害通用语言能力。为此,哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)推出了“珠算”代码大模型,其以2.7B参数在代码与通用语言平均性能上均超越了DeepSeek-Coder-1.3B、Yi-Coder-1.5B、Stable Code-3B、Granite-3B-Code等参数量3B及以下的代码大模型,希望通过开放权重、训练细节以及配套的微调适配平台与插件,助力开源社区的发展。珠算系列模型已经发布到始智AI wisemodel开源社区,欢迎大家前往使用。
02
面向代码的继续预训练与微调
目前,主流代码大模型的构建方式大体分为从头预训练与基于通用大模型继续预训练两种。相比之下,后者收敛速度更快且可以较大程度保留通用语言能力,因此,珠算大模型采取继续预训练范式构建,所基于的通用大模型选取为面壁智能的MiniCPM-2B,其具备优异的通用语言能力以及更为开放的训练细节。参照MiniCPM的WSD(Warmup-Stable-Decay)学习率调度,珠算大模型将其修改为WCL(Warmup-Cosine-Linear),在保留原算法快速收敛特性的同时适配了我们数据量固定的训练场景,更充分地利用了现有数据。在微调阶段,为了充分激发预训练习得的能力,微调数据的选取与配比尽可能地与预训练过程进行了对齐。接下来将分别详细介绍继续预训练与微调两个阶段的数据以及训练过程。
2.1 面向代码的继续预训练
面向代码的继续预训练需要海量高质量数据与高效训练调度算法的支撑,其中预训练数据是支撑模型各项能力的基础,决定了模型的性能上限;训练调度算法则是将数据中蕴含的知识转换为模型能力的关键路径,同时也是影响模型学习效率和核心要素。因此,为了提升数据质量与训练效率,珠算大模型在前人工作的基础上针对两者分别进行了相应的优化。
2.1.1 预训练数据处理
继续预训练阶段的数据主要包含海量代码与一定量的通用语言数据,前者是将通用大模型转换为代码大模型的必要条件,而通用语言数据则是维持模型通用语言能力避免灾难性遗忘的有效补充。
(1)代码数据
珠算大模型采用的预训练代码数据主要来源于The Stack V2,在原始预训练数据的基础上进行了数据过滤以及代码依赖分析的处理流程。如图2-1所示,数据过滤主要包括语法分析、数据密集型代码检测与全面静态代码分析。首先,语法分析阶段借助抽象语法树(AST)分析代码的结构,去除存在低级语法错误与包含过时语法特性(如print “Hello World”,Python3解释器已不再支持)的代码。其次,数据密集型代码检测阶段旨在去除主要用于存储数据的文件。经训练过程观测,损失函数会在特定步数时出现过高或过低的尖刺。通过detokenize发现,过高损失对应数据多为数据密集型代码(例如base64格式编码或长字符串),过低损失对应数据多为简单重复代码(如使用大量if分支枚举所有可能情况),为此我们提取了该类数据的特征并设计了正则表达式进行了针对性的过滤。最后,为了进一步提高代码的规范性、可读性,我们利用静态代码分析工具Ruff提供的漏洞检测与修复功能,去除了含有未定义变量错误的代码、修复了剩余代码的常见规范性错误(如多余的空行、空格)。图2-2展示了上述三个阶段滤除数据的典型示例与占比。

图2-1 数据过滤方法
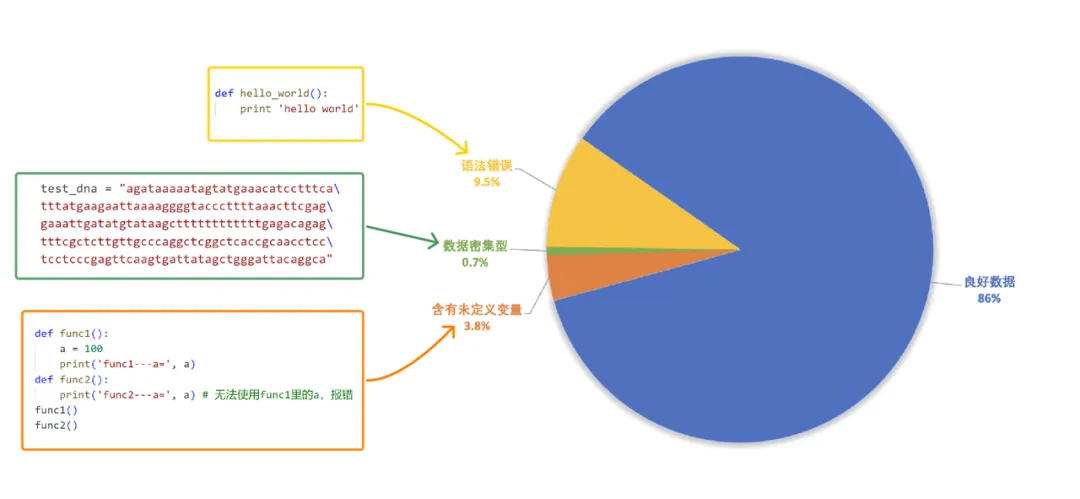
图2-2 滤除数据示意图
代码依赖分析旨在按代码的逻辑结构合理地组织数据训练顺序。通常,代码大模型训练样本的基本单位为一个代码库,在代码库内部按照依赖关系组织文件顺序更符合代码编写的逻辑顺序。经DeepSeek-Coder验证,该顺序有助于提升项目级别代码的处理能力。然而,现有的分析方法未充分考虑循环依赖的情况。珠算大模型针对该问题进行了优化,首先对依赖关系图进行tarjan缩点,将图中的环整体缩为一个点,然后进行拓扑排序,以此对环外点进行正确排序。对于环内点,使用PageRank算法单独排序。
(2)通用语言数据
珠算大模型采用的预训练通用语言数据来源于SlimPajama[11]数据。其中,StackExchange子集包含大量编程相关问答对,是编程意图理解能力的重要来源。为此,我们针对该数据设计了额外的过滤方案,以充分保证问题与答案的匹配程度。StackExchange数据由StackOverflow上编程相关问答对组成。为了排除答非所问的低质量数据,我们借鉴了The Stack V2中的处理方法。首先使用Llama3.1-70B-Chat[12]对随机采样的2万个样本进行评分并使用评分结果训练了质量评估模型(准确率与召回率达95%),然后利用该模型对完整数据进行过滤。图2-3展示了分数分布。在过滤掉得分低于-0.3的样本(约占14%)之后,剩余约82GB数据。
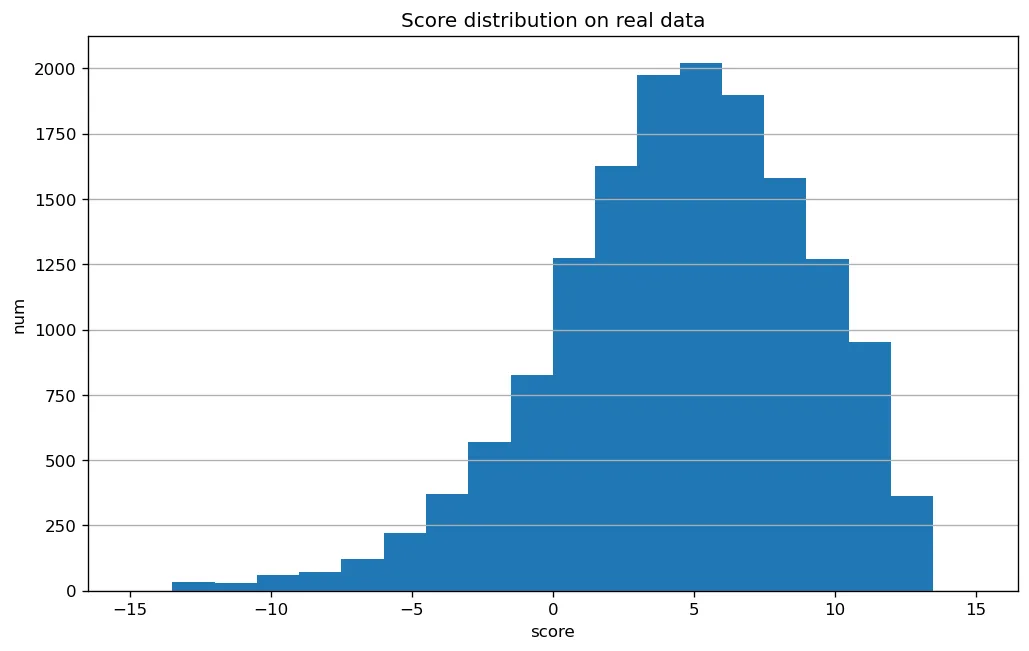
图2-3 质量分数分布
技术文档通过启发式方法从The Stack V2数据集中收集。具体而言,我们从数据集中筛选出了Markdown与reStructureText格式的文件,这些格式的文件常为项目的说明文档或技术文档。然后,从中过滤出语言为中英文、包含Python代码块的文件,最终获取了约1.5GB的文档数据。
2.1.2 预训练策略
为使珠算大模型保持较高的通用语言能力,我们从MiniCPM-2B退火前的最后一个检查点开始继续预训练。学习率调度参照了WSD方法,即Warmup至一个较高的恒定学习率(称之为Stable阶段),用以搜索全局最优点,最后结合微调数据快速线性退火收敛至较低损失。其中,Stable阶段的恒定学习率设计主要为了便于随时接入新数据。在珠算大模型数据确定的场景下,我们观测到在该阶段缓慢降低学习率更有利于预训练数据的充分学习,因此应用了cosine学习率调度进行替换,形成WCL学习率调度(Warmup-Cosine-Linear)。学习率曲线如图2-4所示,训练超参数数如表2-1所示。
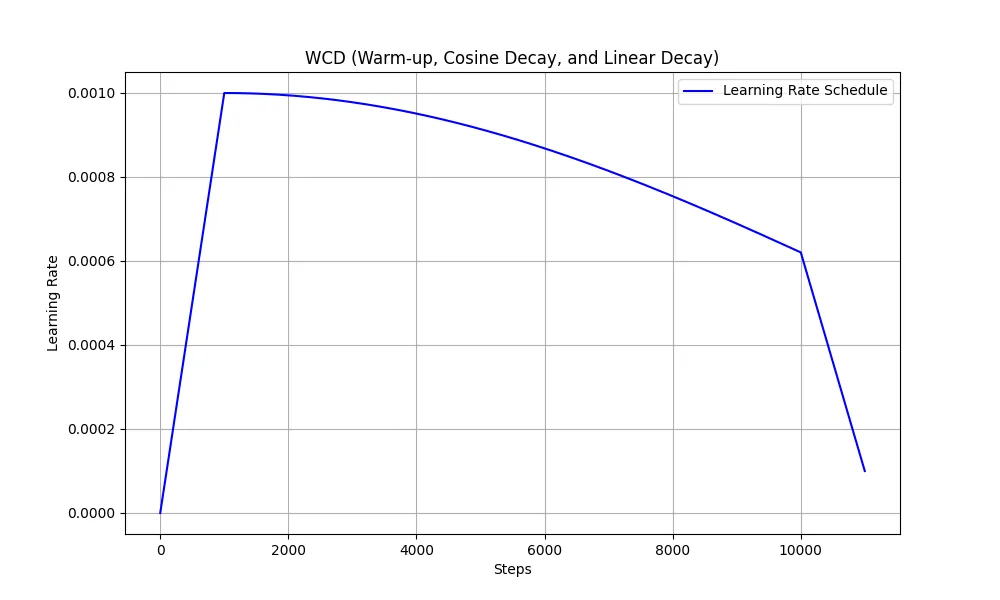
图2-4 WCL学习率调度曲线
表2-1 超参数设置
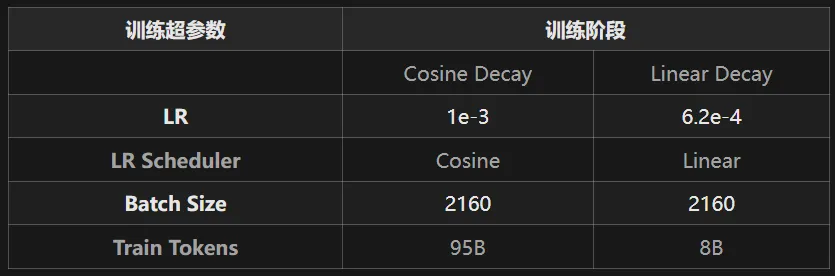
Cosine Decay阶段的预训练数据由70%的代码数据、10%数学相关数据、20%的通用语言数据组成,具体的数据组成及比例如图2-5所示。

图2-5 Cosine Decay阶段数据组成
Linear Decay阶段参考MiniCPM的设置引入了高质量微调数据。其中,预训练与微调数据比例为8:2,预训练内部组成与Cosine Decay阶段保持一致,微调内部代码与通用语言数据的比例为1:1。具体的数据组成及比例如图2-6所示。
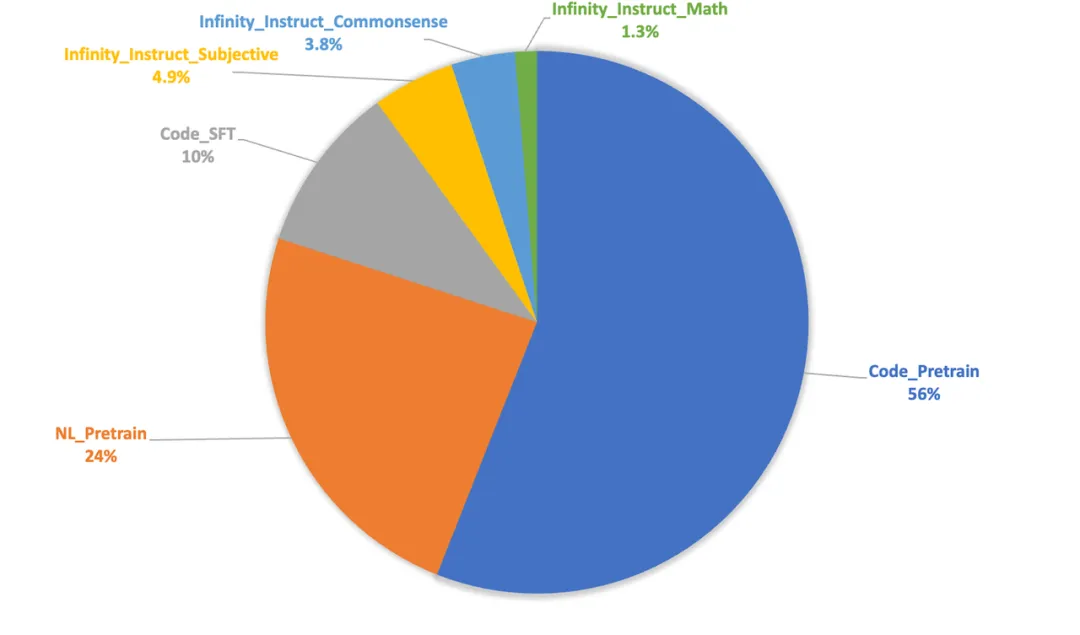
图2-6 Linear Decay阶段数据组成
为保证训练效率,预训练阶段通常采取packing策略,将不同长度的样本拼接后整体作为一条训练数据。然而,该策略导致了训练数据内部多个样本之间互相干扰,造成了样本间的污染。目前主流的训练框架大多忽略了该问题,每条训练数据使用固定的下三角Attention Mask,如图2-6(左)所示。为此,珠算大模型将其优化为了Block Attention Mask,将训练数据内部每个样本的注意力机制范围限制在自身,避免了样本间的污染,如图2-7所示。
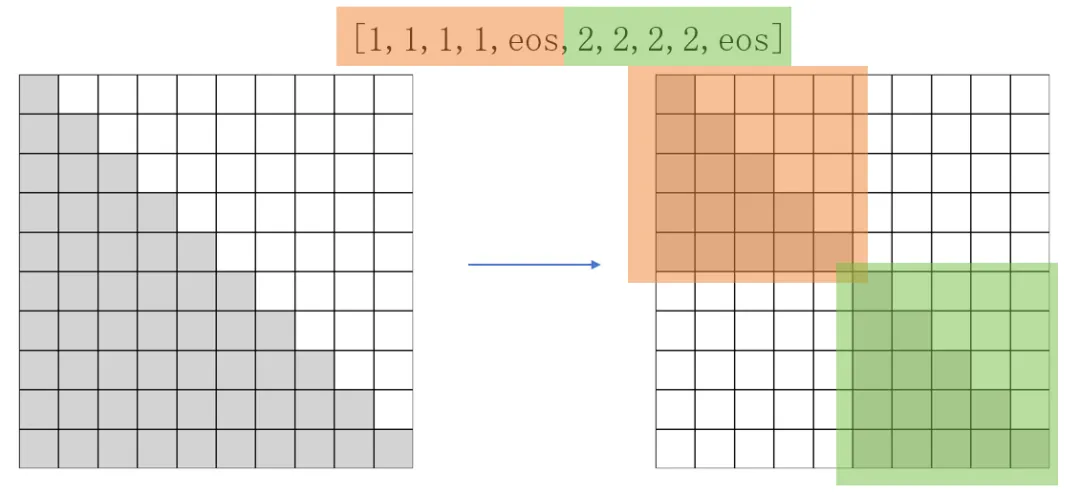
图2-7 下三角Attention Mask和Block Attention Mask
2.2 面向代码的微调
面向代码的微调数据多为“指令-代码”形式,用以将模型与人类编程意图对齐。微调数据来源庞杂质量高低不一,同时为充分激发预训练习得的能力,需要针对数据自身以及训练策略进行针对性的优化。
2.2.1 微调数据处理
目前,Natural-Instruct(自动收集)和Self-Instruct(模型合成)是收集代码微调数据的两种主要方式。其中,Natural-Instruct的代码多样性和正确性较高,但缺乏高质量的自然语言指令,且格式不规范。相比之下,Self-Instruct能自动生成成对数据,但缺乏多样性和正确性。我们提出了Semi-Instruct[13]结合了两种方式。首先,通过类似Self-Instruct的方法,修复Natural-Instruct代码的规范性问题并补充缺失的指令。同时,生成测试用例的输入,利用原始代码的正确性,执行原始代码获得输出。然后,利用完整的测试样例验证新代码的正确性。最终,为去除不同来源的数据之间的重复样本,我们借助基于句子嵌入的SemDeDup方法对数据整体进行了深层语义去重,确保了微调数据的多样性。
2.2.2 微调策略
为充分激发模型预训练阶段习得的能力,微调阶段的数据配比与超参数设置训练尽可能地与预训练退火阶段保持了对齐,以减小两者之间的差距。具体而言,微调数据量约80万条,共训练3个epoch。学习率(1.6e-4)、数据配比(如图2-7)与退火阶段保持一致,经实验观测可以有效提升模型性能。Batch size设置为64(我们在实验中发现该参数对最终性能影响并不显著)。数据来源上,Code数据主要来自一些高质量的开源Code数据,NL数据我们则使用了Infinity-Instruct-7M[15]数据中的Math、Commonsense和Subjective3个类别的数据。
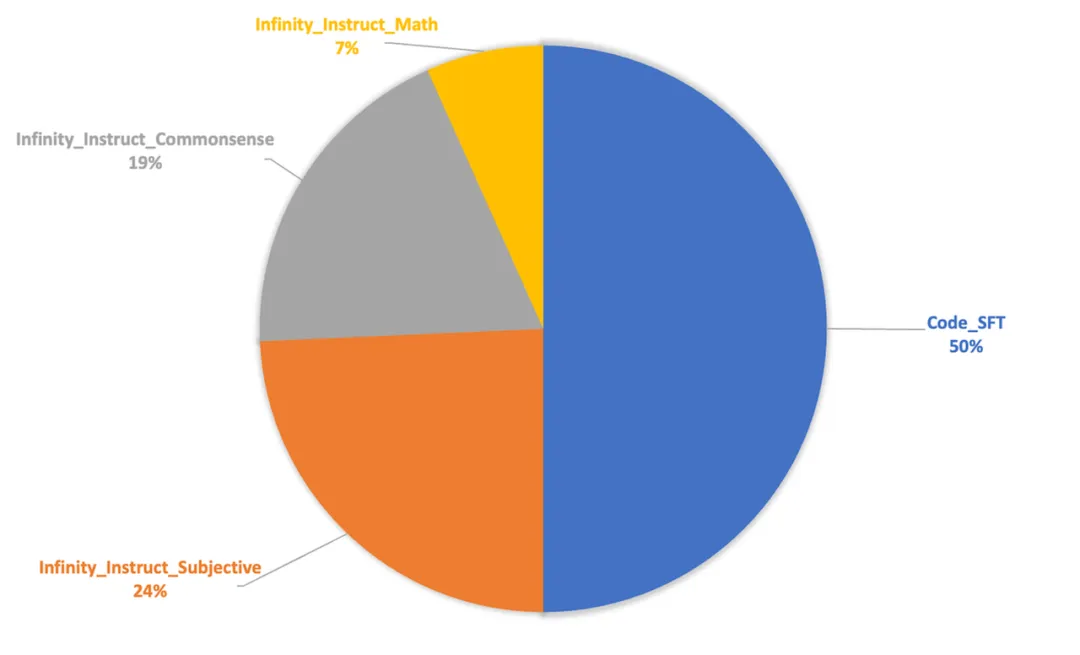
图2-8 微调阶段数据组成
03
评测结果
为了评价珠算大模型在代码与通用语言上的性能,我们在多个公开评测基准上对比了参数量3B及以下的主流代码大模型,结果概览如图3-1所示。
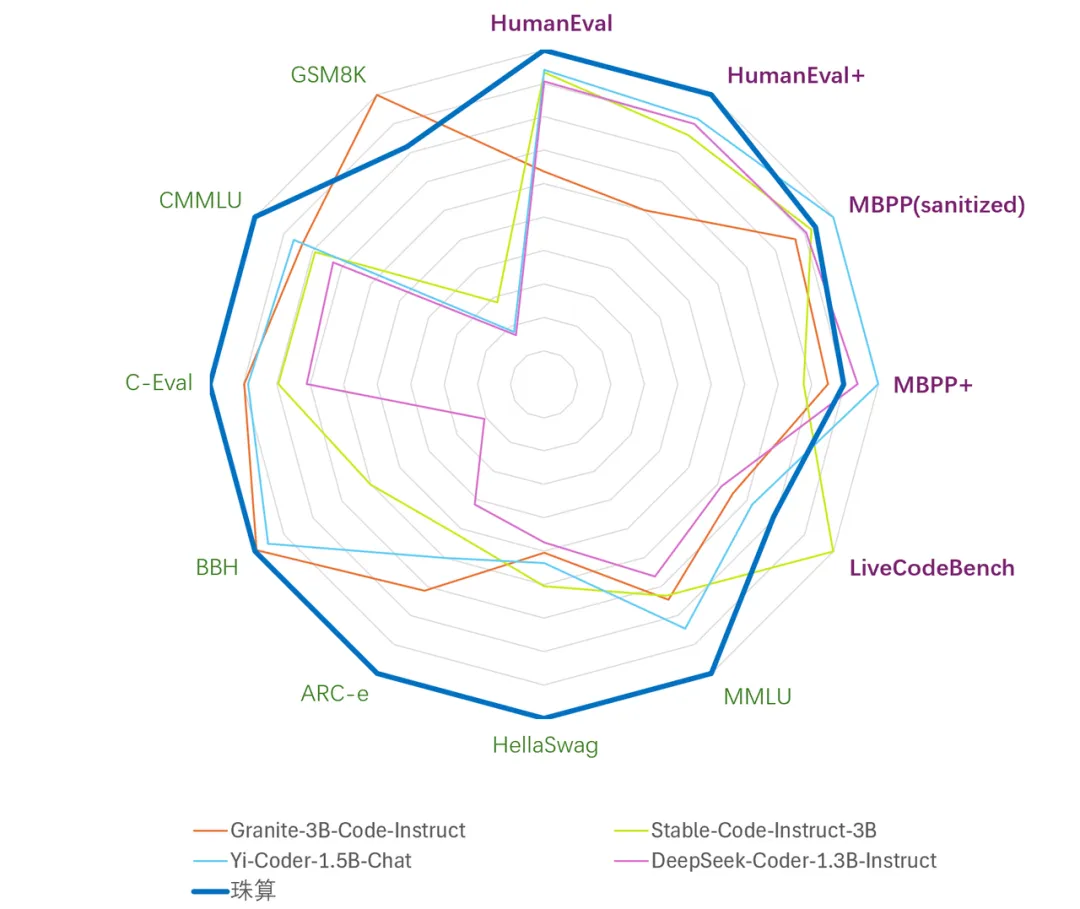
图3-1 3B以下参数代码大模型综合相对性能
3.1 代码生成能力
模型代码生成能力的评估主要基于以下评测基准:
HumanEval:由 164 道原创编程题组成的评测基准,通过衡量从文档字符串生成程序的功能正确性,评估语言理解、算法和简单的数学能力。
HumanEval+:HumanEval+将原始HumanEval中164道问题的单元测试的规模增加了80倍,用于严格评估 LLM 生成代码的功能正确性。
MBPP(sanitized):Python编程任务评测基准,经过人工验证后的MBPP子集,删减修改了原始MBPP中描述模糊、错误、不符合正常习惯的问题。
MBPP+:精简了原始MBPP中的问题数量,并将单元测试的规模增加35倍,用于严格评估 LLM 生成代码的功能正确性。
LiveCodeBench:旨在为 LLM 提供全面、公平的竞赛编程评估。通过持续收集LeetCode、AtCoder和CodeForces竞赛平台的新问题,形成了动态的综合基准库。为了确保数据不受污染,我们选择了 2024 年 1 月至 9 月的问题进行测试。
评测时,我们参考前人工作,在HumanEval,HumanEval+、LiveCodeBench采用0-shot,MBPP(sanitized)、MBPP+采用3-shot,所有测试均使用pass@1指标与greedy策略。
对于HumanEval,HumanEval+、MBPP(sanitized)、MBPP+,我们使用OpenCompass进行评测,版本为稳定发布的0.2.3版,使用vLLM 0.4.3加速推理。LiveCodeBench使用官方仓库代码进行评测。
下表为相关模型在上述评测基准上的表现,其中最高得分加粗、第二高得分加下划线。表3-1 3B以下参数代码大模型代码生成能力评估
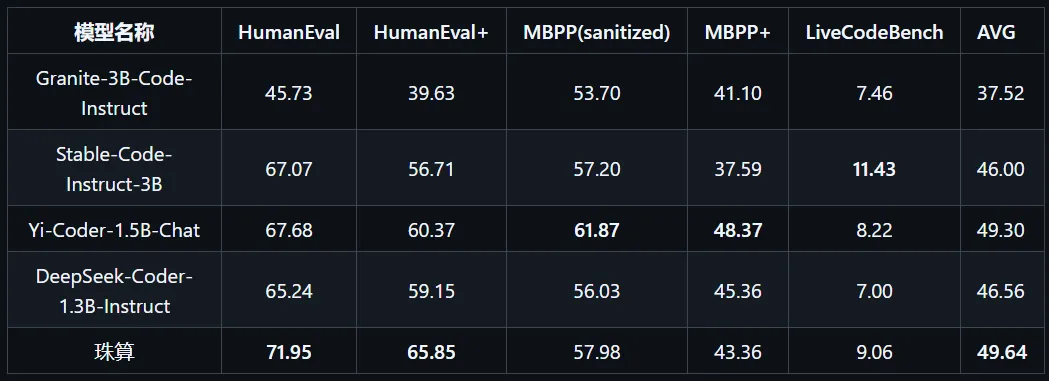
在国内外3B以下代码大模型中,珠算大模型在五个主流代码评测基准上的综合表现达到最佳,各项指标均处于领先水平。其中,在Humaneval和Humaneval+基准上的表现尤为突出;在MBPP(sanitized)和MBPP+基准上的表现略逊于最新发布的Yi-Coder-1.5B-chat;而在LiveCodeBench基准上的表现仅次于Stable-Code-Instruct-3B。
3.2 通用语言能力
通用语言能力的评估主要基于以下评测基准:
MMLU:包含57个多选任务的英文评测基准,涵盖初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的LLM评测基准之一。
HellaSwag:极具挑战的英文NLI评测基准,需要对上下文进行深入理解,无法基于常识直接回答。
ARC-e:多项选择题的问答评测基准,包含了从三年级到九年级的科学考试题目。ARC-e(easy) 是其中的一个简单难度测试子集。
BBH(BIG-Bench Hard):BIG-Bench 是一个用于评估语言模型的多样化的数据集。BBH 专注于从 BIG-Bench 中挑选出的23个具有挑战性的任务。
C-Eval:全面的中文LLM评估基准,包含了13,948个多项选择题,涵盖了52个不同的学科和四个难度级别。
CMMLU:综合性中文评估基准,用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的67个主题。
GSM8K:高质量小学数学应用题评测基准,需要2到8个步骤来解决,解决方案主要涉及基本算术运算,可用于评价多步数学推理能力。
评测时,我们参考前人工作,在HellaSwag、ARC-e上采用0-shot,在BBH上采用3-shot,在GSM8K上采用4-shot,在MMLU、C-Eval、GSM8K上采用5-shot,所有测试均基于greedy策略。
对于上述所有数据集,我们使用OpenCompass进行评测,版本为稳定发布的0.2.3版,使用vLLM 0.4.3加速推理。
下表为相关模型在上述评测基准上的表现,其中最高得分加粗、第二高得分加下划线。
表3-2 3B以下参数代码大模型通用语言能力评估
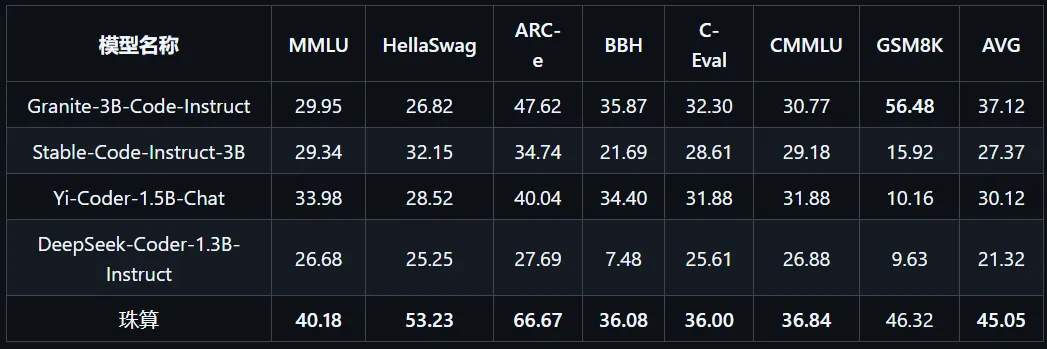
在国内外3B以下代码大模型中,珠算大模型在七个主流通用语言评测基准上的综合表现达到最佳,且具有明显优势。除在数学推理GSM8K基准上低于Granite-3B-Code-Instruct,其余各项指标均达到最优;通用语言能力与通用大模型MiniCPM-2B-sft-bf16还有一定差距,后续版本将对此进行强化,以此带来更自然、更流畅的对话,以及对用户需求更充分的理解,最终在自动化编程辅助、代码智能体领域有更加广阔的应用前景。
04
局限性与未来工作
受限于计算资源等原因,模型目前还存在如下的局限性:
目前模型的代码能力主要体现在Python语言上,多编程语言能力将于后续版本中发布;
通用语言能力优于同量级代码大模型,但相比于最优的同量级通用大模型仍有差距,后续版本将对此进行强化。














暂无评论内容