大模型主要依赖于离散潜变量序列来模拟环境动态。然而,将信息压缩到紧凑的离散表示中,可能忽略了对强化学习至关重要的视觉细节。同时,扩散模型已成为图像生成的主流方法,挑战了传统的离散潜变量建模方法。受这一范式转变的启发,日内瓦大学、爱丁堡大学和微软研究院提出了DIAMOND(DIffusion As a Model Of eNvironment Dreams),一种在扩散世界模型中训练的强化学习代理。Atari 100k是一个用于评估强化学习算法性能的基准测试,包含100,000个游戏回合,主要基于Atari 2600游戏。它提供了一系列多样化的游戏,旨在测试和比较不同算法在处理复杂环境中的能力。DIAMOND在竞争激烈的Atari 100k基准测试中达到了1.46的人类标准化平均分,可以生成非常流畅的CSGO等游戏。
01 技术原理—
DIAMOND训练了一个扩散模型来预测游戏的下一帧。该扩散模型会考虑代理的动作和之前的帧,以模拟环境的响应来生成下一帧。

代理不断提供新的动作,扩散模型则更新游戏。扩散模型充当世界模型,代理可以在其中学习游戏玩法。

为了加快世界模型的运行速度,需要减少去噪步骤的数量基于DDPM的模型在去噪步骤较少时,由于累积的自回归误差会变得不稳定,而基于EDM的模型则保持稳定。减少去噪步骤可以使世界模型运行得更快。
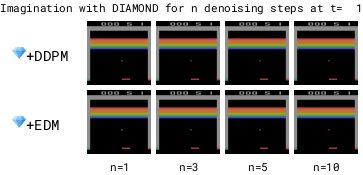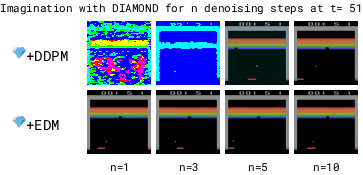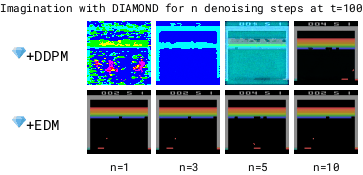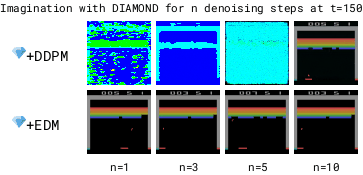
但在拳击游戏中,1步去噪会在可能的结果之间进行插值,导致对不可预测的黑方玩家做出模糊的预测。相比之下,增加去噪步骤可以更好地选择特定模式,从而提高预测的一致性。
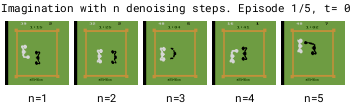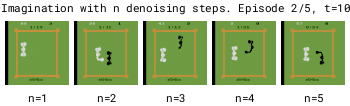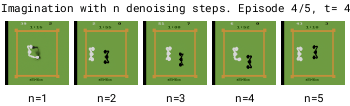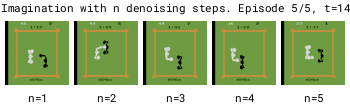
更多的去噪步骤 (n) 能够更好地选择具有多种模式的转换方式。因此,在 Diamond 的扩散世界模型中使用 (n=3) 的去噪步骤。

有趣的是,白方玩家的动作预测无论去噪步骤的数量如何都能正确。这是因为白方由策略控制,其动作直接输入到世界模型中,这消除了可能导致模糊预测的任何歧义。02 实际效果—所有视频均由人类使用键盘和鼠标在DIAMOND的扩散世界模型中生成,该模型是在《反恐精英:全球攻势》(CSGO)上训练的。
但也可以直观的看出存在一些问题,当固定动作并观察模型的反应时,短期内效果良好,但随着时间的推移,轨迹可能会变得不合逻辑。这突显了在复杂环境中,世界模型需要更好地理解和生成合理的行为序列。














暂无评论内容