
当年Jürgen Schmidhuber那句“循环神经网络(RNN)是我们所需要的一切”,如今似乎又有了新的佐证。尽管Transformer模型已在自然语言处理领域占据主导地位,尤其在大语言模型领域表现亮眼,但它们仍然在处理长序列时面临挑战。
为了弥补这个短板,研究人员尝试了多种架构,比如Mamba等。不过,Borealis AI的研究人员决定重拾RNN,探索其能否解决当前LLM的局限性。
深度学习之父之一Yoshua Bengio领导的研究团队指出,早期的RNN(如LSTM和GRU)因需经过繁琐的反向传播(BPTT)过程,导致训练速度缓慢。Schmidhuber对此常引以为豪。研究人员则反思道:“难道RNN才是我们需要的吗?” 他们通过消除输入中的隐状态依赖,提出了一种无需反向传播且可以并行训练的新方式。

1
RNN为何卷土重来?
研究团队推出了简化版的LSTM和GRU,分别命名为minLSTM和minGRU。这些“极简版”模型较传统RNN大幅削减了参数量,并且可以通过并行扫描算法训练,大幅提升了训练速度。数据显示,在处理长度为512的序列时,minGRU和minLSTM每步训练速度比传统GRU和LSTM快了175倍和235倍。
有开发者表达了对minGRU架构的喜爱,他提到新提议的隐状态和混合因子仅依赖当前token,若在训练时已知整个序列,便能并行计算所有状态,并线性时间内通过并行扫描合并结果。
尽管如此,这位开发者也指出,minRNN在小规模实验中的竞争力令人欣慰,但是否能在大规模实验中超越Transformer,还需进一步验证。
2
Transformer的不可替代性?
Transformer在处理长序列时可以随时检索过去的信息,这在类似ChatGPT的交互场景中极具优势。它可以实时从上下文中提取重要信息,而RNN则是逐步更新和覆盖其记忆,因此它们需要更好地预测哪些信息将来可能重要,并将其保留。
虽然一些混合模型,如Jamba,将Transformer与RNN的优势结合,但Transformer在上下文处理中的优势依然不容忽视。
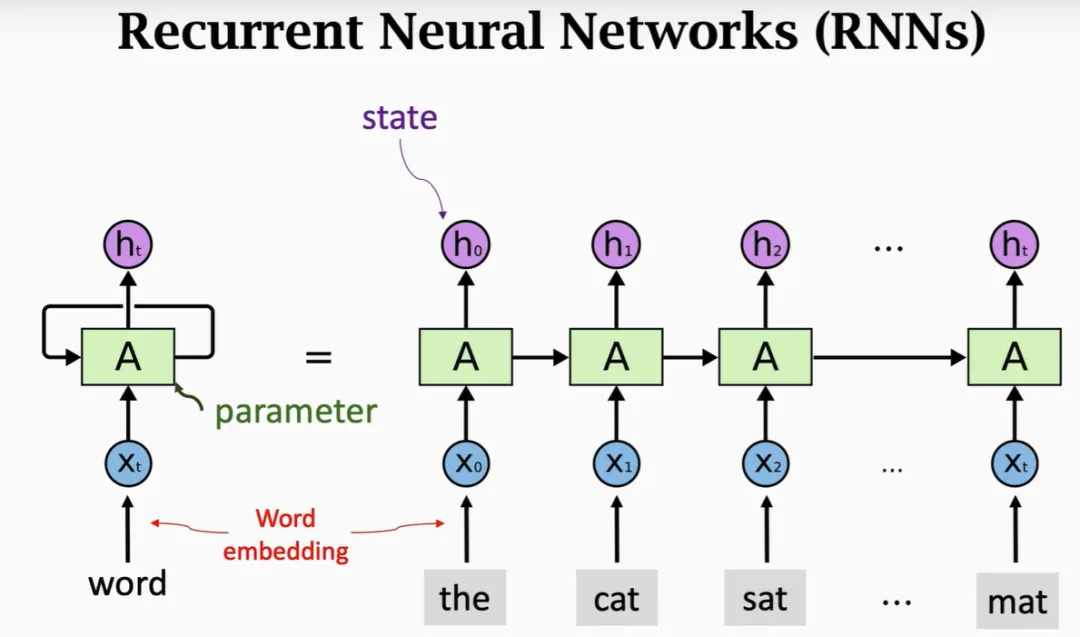
早在2019年,研究人员就曾在《Single-Headed Attention RNN: Stop Thinking With Your Head》一文中提出LSTM可以达到接近SOTA的水平,暗示Transformer的风头或许有些“过度吹嘘”。
3
RNN或许能大放异彩
某位Reddit用户早些时候预测,RNN将在找到更好的训练方法和自适应计算时间方案后回归。他指出,随着模型变得多模态并开始处理大量图像、视频、声音等信息时,Transformer将因存储整个序列的需求而面临内存瓶颈,而RNN则天生无需存储所有数据,更适合应对这些挑战。
最终,minLSTM和minGRU的提出,似乎验证了这一观点:极简版RNN通过削减参数量和训练时间,在可扩展性上超过了传统RNN,并有望在与Transformer的竞争中取得更大优势。
或许,未来的序列建模将采用RNN和Transformer的混合方式,以最大化二者的优势。这种效率和简洁兼具的新方法,可能正是我们在大数据时代所需要的答案。














暂无评论内容