团队介绍:本项目的核心开发团队主要由上海交通大学 GAIR 研究组的本科三年级、四年级学生以及直博一年级研究生组成。项目得到了来自 NYU 等一线大型语言模型领域顶尖研究科学家的指导。详细作者介绍见:https://github.com/GAIR-NLP/O1-Journey#about-the-team。
在人工智能领域掀起巨浪的 OpenAI o1 模型发布三周后,一支由高校年轻研究者组成的团队今天发布了题为 “o1 Replication Journey: A Strategic Progress Report (o1 探索之旅:战略进展报告)” 的研究进展报告。这份报告的独特之处在于 (1)不仅提出并验证了 “旅程学习” 的技术的巨大潜力(研究者也认为是 o1 取得成功的关键技术):通过 327 条训练样本,鼓励模型学会反思、纠错、回溯,其在复杂数学题目上表现 绝对性能就超过了传统监督学习 8% 以上,相对性能提升超过 20%;(2)并且,其前所未有的透明度和即时性,不仅详细记录了团队在复现过程中的发现、挑战、试错和创新方法,更重要的是,它倡导了一种全新的 AI 研究范式。研究团队负责人表示:” 我们的主要目标不是达到与 OpenAI 的 o1 相当的性能 —— 考虑到可用资源有限,这是一个极具挑战性的任务。相反,我们的使命是透明地记录和分享我们的探索过程,聚焦于我们遇到的根本问题,发现新的科学问题,并识别导致 o1 的成功的关键因素,并与更广泛的 AI 社区分享我们的试错经验。o1 技术无疑会成为全球各大 AI 科技公司争相复现的目标。如果我们能够及早分享一些复现过程中的经验教训,就能帮助其他公司减少不必要的试错,从而降低全球范围内 o1 技术复现的总体成本和时间。这不仅有利于推动技术的快速发展,也能促进整个 AI 行业的共同进步。”

团队提出的模型在同一道数学题上,与 OpenAI 的 o1-preview (答对)及 GPT-4o(答错)的比较实例,证明旅程学习不断试错、反思、自我纠正的能力在复杂推理任务场景上非常关键。
- 技术报告链接:https://github.com/GAIR-NLP/O1-Journey/blob/main/resource/report.pdf
- Github 链接:https://github.com/GAIR-NLP/O1-Journey
- o1 讨论资源:https://github.com/GAIR-NLP/O1-Journey/tree/main/resource
该报告发现了什么?从 “”捷径学习”” 到 “旅程学习”,从 “浮光掠影” 到 “深耕细作”
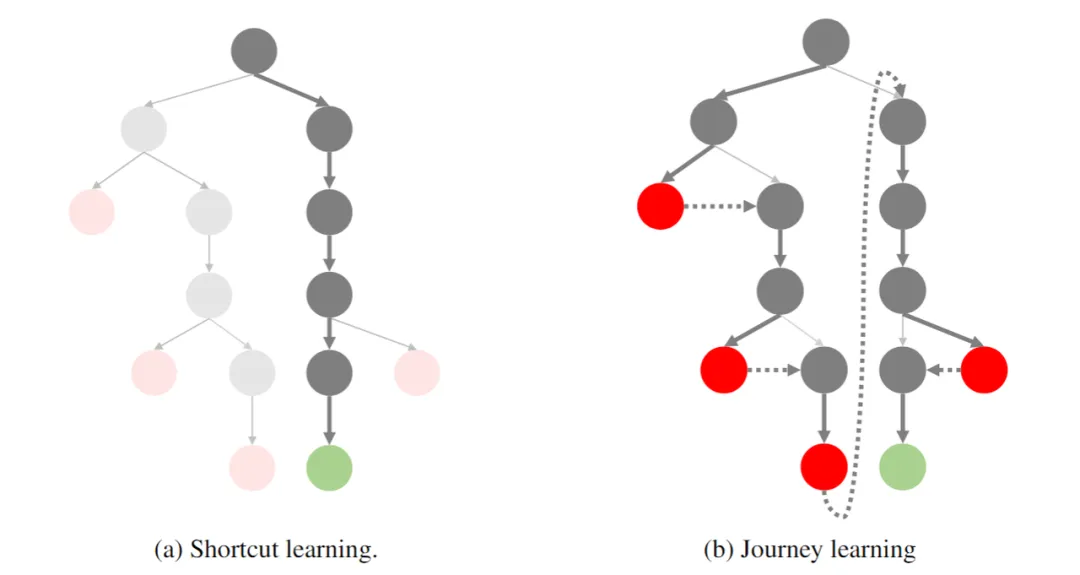
图:从 “捷径学习” 到 “旅程学习” 的范式转变。这是一个用于推理任务的搜索树。对于数学问题解决任务,根节点代表初始问题,而叶节点则是最终结论。绿色节点表示正确答案,红色节点表示错误答案。传统上,学习主要集中在对直接从根到叶的捷径路径进行监督训练。然而,本研究探索了对整个探索路径进行监督学习,这包括了试错和纠正的过程。
团队认为,大多数现有的机器学习或大模型训练方法(如监督式微调)都可以被归类为 “捷径学习” (Shortcut Learning),即模型学习到达正确答案的直接路径。这种传统范式虽然在特定、明确定义的任务中可能有效,但在面对复杂、动态和开放性问题时显示出明显的局限性。捷径学习具有以下几个关键特征:(1) 注重快速结果:强调在短时间内达到特定的性能指标或完成特定任务。(2) 高度依赖数据:性能改进通常依赖于增加训练数据量,而非改进学习算法本身。(3) 泛化能力有限:在训练数据分布之外的场景中,性能可能会急剧下降。(4) 缺乏自我纠正能力:这些系统通常缺乏识别和纠正自身错误的能力。尽管捷径学习推动了人工智能的许多进步,但它难以产生真正智能和可靠的人工智能系统,无法应对现实世界挑战的复杂性。随着我们追求更高级形式的人工智能甚至超级智能,这种方法的局限性变得越来越明显。
认识到这些缺点,本文提出了一种名为 “旅程学习”(Journey Learning) 的新范式。旅程学习旨在使人工智能系统能够通过学习、反思、回溯和适应不断进步,就像人类一样,从而展现出更高水平的智能。
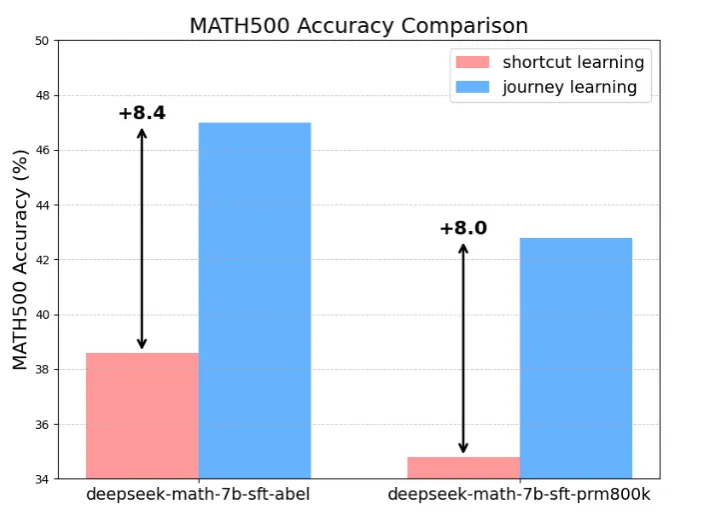
图:”捷径学习”(Shortcut Learning) 和 “历程学习”(Journey Learning) 在 MATH500(Lightman 等人,2024 年)上的表现。
如图所示,团队提出了 “旅程学习” 范式,它鼓励模型不仅学习捷径,还要学习完整的探索过程,包括试错、反思和回溯。仅使用 327 个训练样本,不借助任何额外训练技巧,旅程学习在 MATH 数据集上的表现就超过了传统监督学习 8% 以上,展示了其极其强大的潜力。作者也认为这是 o1 技术中最关键的组成部分。
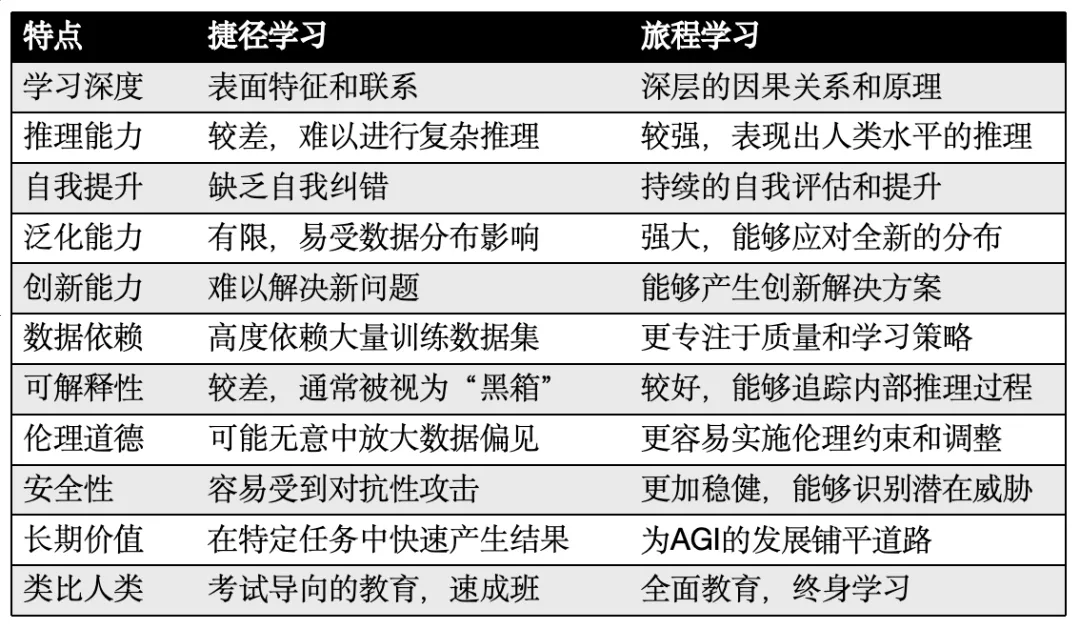
表:捷径学习和旅程学习的多维度比较
模型生成的例子



技术细节是什么?o1 技术探索之旅
团队负责人分享:“如果我们能够及早分享一些复现过程中的经验教训,就能帮助其他公司减少不必要的试错,从而降低全球范围内 o1 技术复现的总体成本和时间。这不仅有利于推动技术的快速发展,也能促进整个 AI 行业的共同进步。”
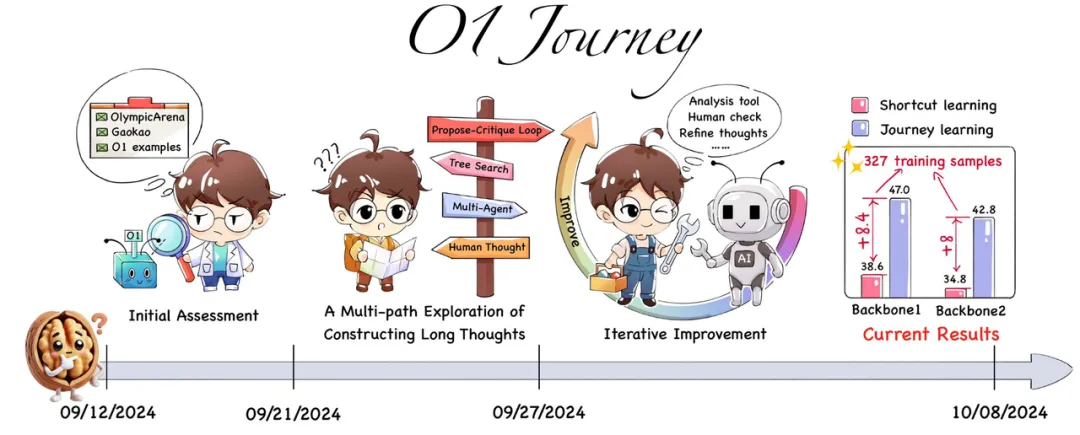
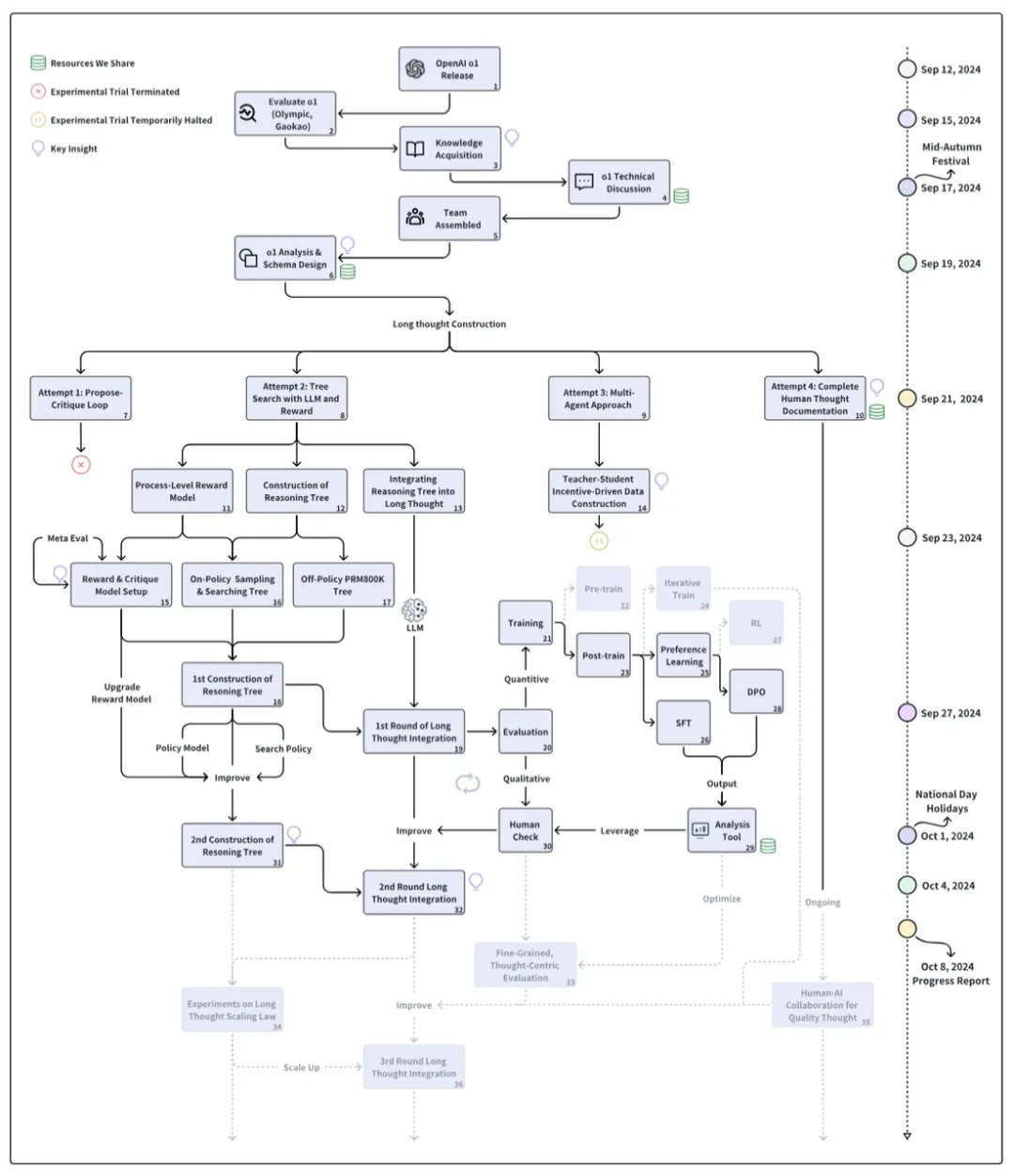
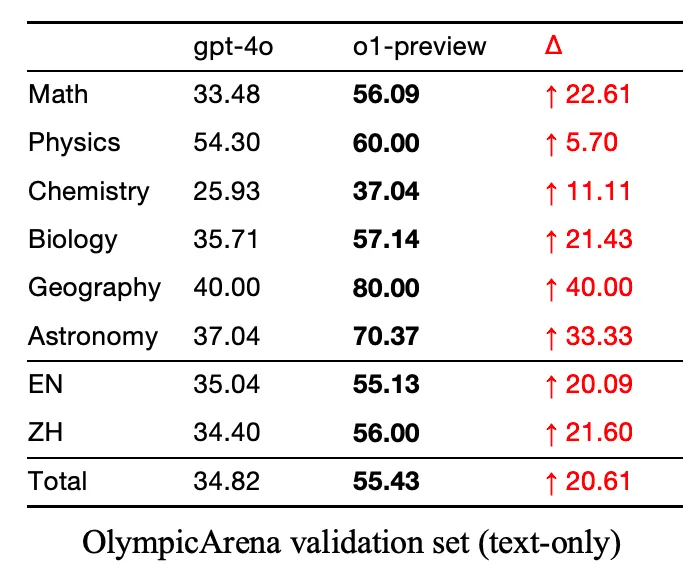
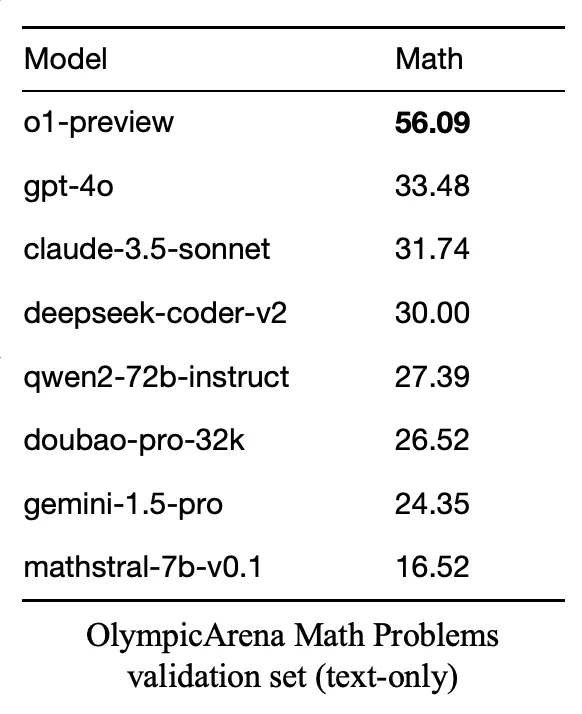
如图所示,从 OpenAI o1 9 月 12 日发布的过去三周内,该团队对 o1 技术已经完成了系统化、多阶段的探索。这个过程始于使用 OlympicArena 数据集对 o1 进行初步评估(如下表格),旨在全面了解其在多个学科领域的认知能力。研究的核心集中在 o1 思维结构的分析上,特别关注 “长思维” 这一关键概念。整个探索技术涉及多个复杂的步骤,包括奖励模型的开发、在策略推理树的构建,以及将这些元素整合为连贯的长思维过程。整个研究过程采用了迭代和并行的方法。进行了多次尝试,不断调整和完善技术和方法。评估过程包括定量和定性分析,结合人工检查和专门的分析工具,以确保研究的准确性和有效性。
团队强调了探索过程的重要性,而不仅仅关注最终结果。这种重视科研探索过程的思路与团推提出的 “旅程学习” 范式相一致,强调了在复杂、动态环境中不断试错、纠错的持续学习和适应的重要性。通过这个过程,不仅获得了关于 o1 技术的深入理解,还开发了一套探索未知 AI 技术的系统方法。研究过程涉及决策分析、挑战识别以及创新解决方案的开发。最终,这项研究不仅仅是对 o1 技术的探索,更是对先进 AI 系统研究方法的一次实践和验证。通过分享研究过程,包括成功和失败的经验,旨在为 AI 研究社区提供有价值的见解,促进该领域的集体进步。
这个探索过程展示了开放、协作的 AI 研究在推动技术边界方面的重要性,为未来更复杂的 AI 系统研究提供了有益的参考和指导。
具体地,团队凝炼了复现 o1 过程中的几个关键问题,并做了非常细致的探索分享:
- Q1: o1 的思维链是什么样子的?
- Q2: 长思维 (Long thought) 是如何工作的?
- Q3: 如何构建长思维?
- Q4: 如何构建奖励模型?
- Q5: 如何构建 on-policy 推理树?
- Q6: 如何从推理树中推导出长思维?
- Q7: 如何评估我们的尝试方法?
- Q8: 如何训练我们的模型?
- Q9: 什么是人类和 AI 协同标注的有效策略?
Q1: o1 的思维链是什么样子的?
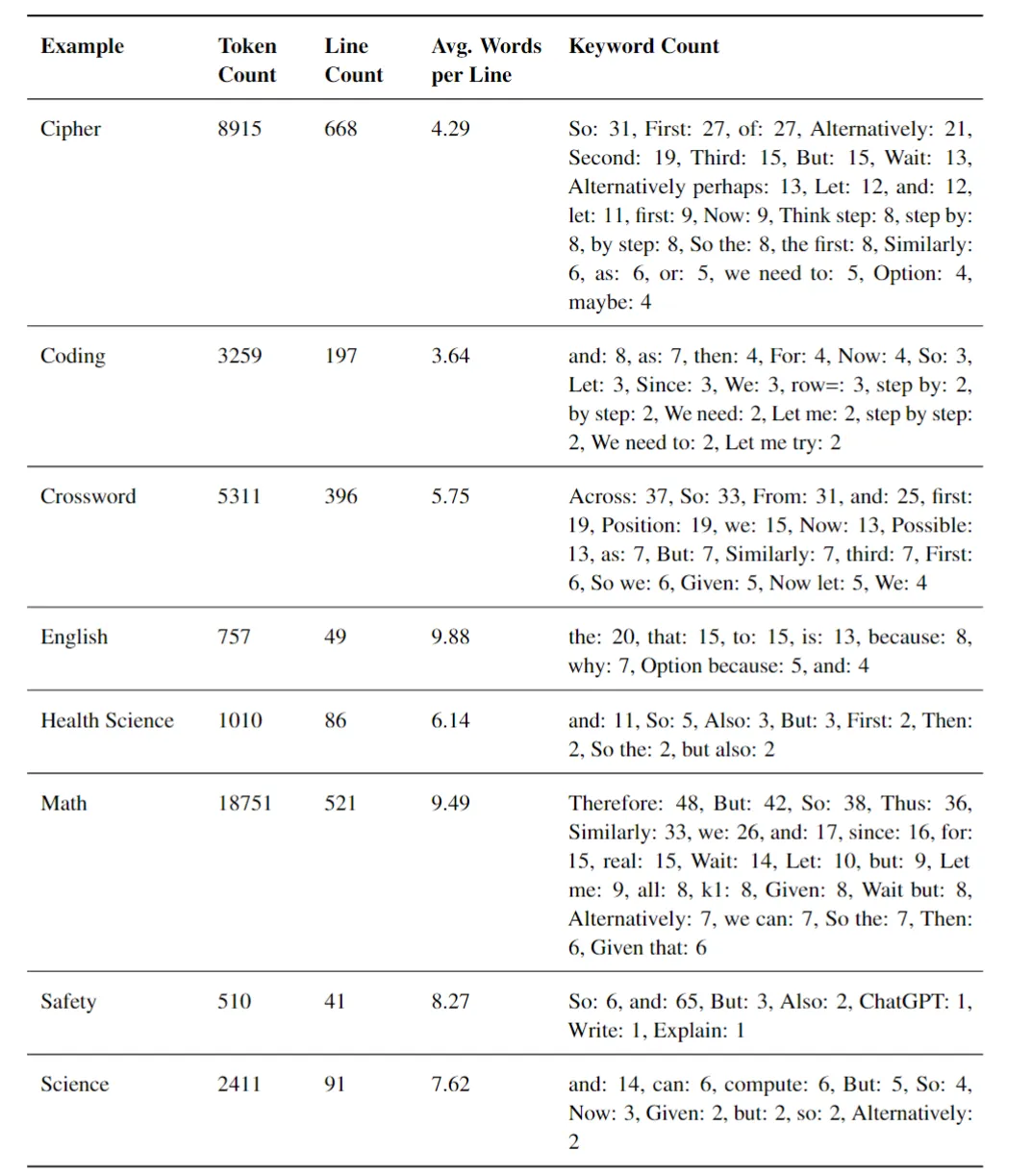
表:基于对 OpenAI 提供的 o1 思维示例的详细分析而创建的 其中包括八个用于解决复杂任务的推理步骤或 “思维” 实例。仔细检查了每个示例,提取了相关特征,如标记数、行数和关键词。
观测:
- 这些示例被分类为不同的问题类型,每种类型都与一个难度级别相关联,从简单的英语阅读理解到复杂的多步骤数学推理任务。分析显示了一个趋势:随着难度的增加,响应长度(包括标记数和行数)往往成比例增长。这表明更高难度的问题涉及更多的推理步骤。
- 除了标记数和行数外,团队还进行了关键词频率分析,以识别可能表征推理过程的重复出现的术语。除了常见的连接词如 “and” 和 “so” 之外,分析还突出了几个出现频率较低但意义重大的关键词。”consider”、”if” 和 “possible” 等关键词经常出现,通常表示推理过程中的分支,考虑多条路径。这些关键词在复杂度更高的问题中出现频率明显更高,表明模型在这些情况下探索不同的解决方案路径。像 “wait” 和 “Alternatively” 这样的关键词是模型能够进行反思和自我纠正的重要指标。这表明模型具有更深入的理解和更细致的推理方法,因为模型不仅仅是遵循线性路径,还能够基于反思重新考虑和完善其方法。
为了理解 OpenAI 的 o1 的思维过程,团队让两位博士水平学生仔细审查 OpenAI 的 o1 在解决数学问题时使用的推理过程。通过他们的详细检查,他们提取了反映 o1 如何处理和推理复杂方程的底层思维链。这个结构化的思维图在图中有所展示。

图:OpenAI o1 真实推理过程的结构化形式本质是一颗搜索树(数学题)

图:OpenAI o1 真实推理过程的结构化形式本质是一颗搜索树(破译题目)
经过这些探索,团队确定需要构建的长思维数据应具有以下特征:
- 迭代式问题解决:模型首先定义函数,然后逐步探索相关表达式,将复杂方程分解为更简单的组成部分,反映了一种结构化和有条理的方法。
- 关键思维指标:使用 “Therefore” 表示结论,”Alternatively” 探索不同路径,”Wait” 表示反思,以及 “Let me compute” 过渡到计算,突出了模型的推理阶段。
- 递归和反思方法:模型经常重新评估和验证中间结果,使用递归结构确保一致性,这在严谨的数学推理中很典型。
- 假设探索:模型测试不同的假设,随着获得更多信息而调整其方法,展示了推理过程中的灵活性
- 结论和验证:最后,模型解方程并验证结果,强调在完成之前验证结论的重要性。
Q2: 长思维 (Long thought) 是如何工作的?
这是团队认为重要的问题。然而,在当前的研究阶段,该团队仅仅提出了猜想。团队认为还没有足够的经验证据来验证它们的准确性,这也是未来需要重点展开的工作。
o1 长思维方法的显著成功可以归因于在上述中介绍的旅程学习 (Journey Learning)。与传统的捷径学习 (Shortcut Learning) 不同,旅程学习允许模型探索整个决策轨迹,模仿人类的问题解决过程。这种全面的探索使 o1 能够考虑多种解决方案路径,从错误中学习,并理解完整的问题解决过程。通过经历正确和错误的路径,模型发展出强大的错误处理和自我纠正能力,增强了其适应新挑战的能力。这种方法培养了对问题领域更深入的理解,不仅仅是知道正确答案,而是理解为什么以及如何得出答案。旅程学习过程密切模拟人类的认知过程,包含试错、反思和调整。这大大增加了模型输出内容的可解释性,因为 o1 可以提供详细的解决步骤并解释其推理过程,包括如何从错误中恢复。因此,基于旅程学习的 o1 长思维过程不仅仅是计算时间的扩展,还代表了一种彻底的、人类般的推理探索。这种方法使 o1 能够处理更复杂的问题,提供更可靠和可解释的答案,并在面对新挑战时表现出更大的适应性,从而解释了它在各种任务中的卓越表现。
Q3: 如何构建长思维?
尝试 1:基于 LLM 和奖励的树搜索 根据在 Q1 中对长思维的观察,其最显著的特征是在推理产生错误时或遇到冗余的推理步骤时尝试反思和回溯。这类似于在推理树上搜索问题的解决方案,在错误节点处回溯,直到找到正确的解决路径。为实现这一点,需要构建一棵推理树,其中根节点代表问题,其他每个节点代表一个推理步骤。从根到任何节点的路径代表从问题到该结论的推理过程。此外,回溯和反思必须基于错误的推理步骤,这需要一个更细粒度的奖励模型(即过程级)来指示树中每个节点的正确性。通过在具有过程级奖励的推理树上执行搜索算法,可以将错误步骤整合到思维链中,从而构建包含回溯和反思等行为的长思维。
尝试 2:提议 – 批评循环 尝试 1 通过基于预定义规则在树上执行搜索来构建长思维,但这限制了回溯和反思等行为的自由度。因此,团队尝试让模型选择自己当前的行为。团队构建了一个提议 – 批评循环,其中为模型预定义了一些可能的行为(即继续、回溯、反思、终止),并让模型自身选择行为来构建推理树。如果树没有达到最终答案,可以将这个负面信号告知模型,引导它反思和纠正其方法。
尝试 3:多智能体方法 基于推理树构建长思维存在几个挑战,包括存在许多冗余的无效节点,以及存在不依赖于反思行为的推理步骤,从而引起构建的长思维逻辑不一致。为解决这个问题,团队设计了一个利用多智能体辩论的算法,其中一个智能体充当策略模型,持续推理,而另一个智能体充当评论模型,指示策略模型是否应该继续当前推理或执行回溯等行为。两个智能体进行持续对话,在找到正确答案时自然构建长思维数据集。
尝试 4:完整的人类思维过程注释 当人类处理推理问题时,他们通常不会不断地向前推理直到解决问题或失败;相反,他们在无法继续时会反思、回溯和重写推理。这种行为与长思维的特征高度一致。因此,可以忠实且全面地记录人类解决推理任务的过程,从而产生高质量的长思维。
Q4: 如何构建奖励模型?
使用奖励模型的第一步是定义粒度。团队的目标不仅仅是关注最终结果,而是专门提高 LLMs 在反思、回溯和相关认知过程方面的能力。因此,团队将评估粒度定义在步骤层面。具体来说,团队使用来自 Abel 的微调数据,通过行号使解决方案变得清晰可辨。
实现奖励模型的过程可以使用开源模型或是调用闭源模型的 api。团队比较了不同奖励模型在 PRM800K 和 MR-GSM8K 子集上的元评估表现。如下表格展示了结果,其中,o1-mini 在不同数据集上表现最佳,证明其是一个良好的奖励模型。
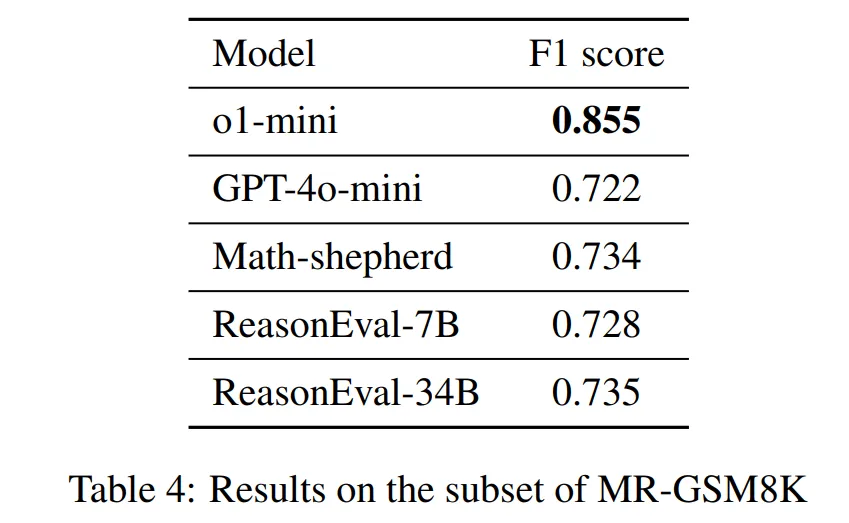
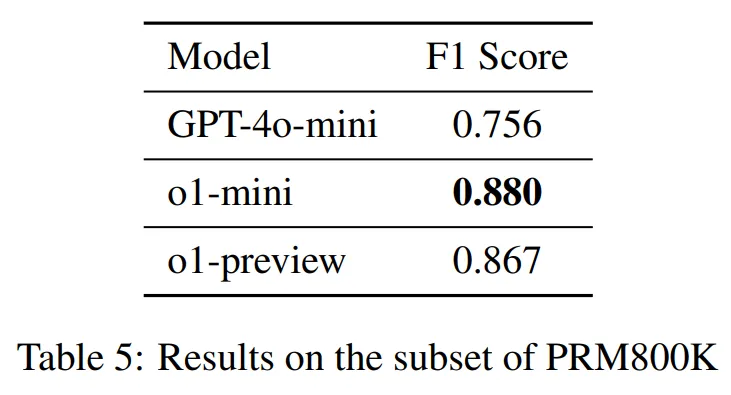
Q5: 如何构建 on-policy 推理树?
构建推理树需要一个能够执行单步推理的策略模型。给定一个问题及其相应的最终答案,策略模型从问题作为根节点开始,不断向树中添加新节点。它首先生成 w 个可能的第一步推理步骤作为根节点的子节点。然后,它迭代地进行前向推理,为每个当前节点(如第一步推理)生成 w 个可能的后续推理步骤作为该节点的子节点。这个过程重复进行,直到达到预设的最大深度或所有叶节点达到最终答案。
策略模型和步骤分段 构建推理树需要清晰定义推理步骤。为此,团队采用 Abel 提出的数据格式,将数学问题解决方案转化为具有清晰步骤的形式,将答案分成多行,每行以行号开始,并包含该行内的推理。因此,使用 Abel 数据集对 DeepSeekMath-7B-Base 进行微调,得到 Abel-DSMath,作为策略模型。在这种特定格式数据上微调的模型可以方便地控制单个推理步骤的生成。
奖励模型和剪枝 上述提出的树生成算法计算成本高昂。当设置后续推理步骤数目为 3 和深度为 10 时,最后一次迭代需要生成 3 的 10 次方个推理步骤。因此,使用奖励模型来剪除错误的推理步骤,提高操作效率。具体来说,团队采用束搜索,在每次迭代中只选择少量候选项保留到下一轮。根据使用的奖励模型,剪枝实现的细节有所不同。团队尝试了两个奖励模型:math-shepherd 和 o1-mini。
Math-shepherd 为每个步骤提供一个介于 0 和 1 之间的实数,表示当前步骤正确的概率。在树生成的每次迭代中,对所有推理步骤进行评分,并选择得分最高的前 K 个进入下一次迭代。这将总生成次数进行剪枝。然而,math-shepherd 在评估困难问题的推理步骤时存在困难,需要一个更强大的奖励模型,能够为每个步骤提供高准确度的正确性指示。因此,最终使用 o1-mini 为每个步骤提供奖励,直接指示每个推理步骤是否正确。此时,在树生成的每次迭代中,利用来自 o1-mini 的奖励,选择最多 K 个正确的推理步骤进入下一次迭代。
Q6: 如何从推理树中推导出长思维?
一旦构建了推理树,目标就变为探索如何从推理树转换为包含试错过程的长思维。在该团队的框架中,推理树的每个节点都被奖励模型标注,指示该步骤是否正确或错误。具体的合成步骤如下:
- 从推理树构建捷径 首先从推理树构建捷径,其中只包括正确答案和有效的中间步骤。从代表问题的根节点开始,找出通向正确答案叶节点的路径。如果有多个正确答案节点,则建立多条正确路径。
- 遍历推理树 为了得到长思维,采用深度优先搜索(DFS)遍历树。这种遍历按 DFS 顺序构建路径,记录从根问题节点到正确答案叶节点的每一步,同时包括任何被标记为错误的节点的推理。DFS 的挑战在于它探索了庞大的搜索空间,产生了大量可能无法得到正确解决方案的试错路径。为了简化这一初始探索,团队还引入了具体的约束来缓解由于遍历路径过长导致的合成数据的复杂性。首先,根据节点是否位于正确路径(即捷径)上来标记树中的所有节点。遍历遵循以下规则:
- 正确路径上的节点:DFS 遇到正确路径上的节点时,它可能会探索导致错误结果的子节点,从而模拟试错的过程。一旦这个节点到达叶节点并被确定为错误,算法就会回溯并切换到正确的路径继续遍历。
- 不在正确路径上的节点:随机选择一个子节点进行探索,并不产生试错的分支。
为进一步简化过程,应用了一个额外的约束:正确路径上的每个节点最多允许 K 次试错 —— 一次在错误路径上的试错和一次在正确路径上的探索。 这些约束确保 DFS 遍历专注有意义的试错探索,同时避免过度探索错误路径。在未来的实验中,计划移除或调整这些约束,以研究试错路径长度与最终模型性能之间的关系。
- 从遍历路径得到长思维 生成遍历路径并将推理附加到错误节点后,通过连接路径中的所有步骤来构建长思维,其中还包含了每个错误步骤的推理。然而,初步实验表明,使用这个形式的长思维数据来训练模型的性能不佳。为解决这个问题,团队尝试使用 GPT-4o 来修改草稿。GPT-4o 在保留所有推理步骤(包括错误步骤、反思和修正)的同时,增强了思维过程的连贯性和流畅性。这种方法确保最终的长思维不仅准确,而且自然流畅,模拟了包含正确和错误步骤的人类问题解决过程。
Q7: 如何评估我们的尝试方法?
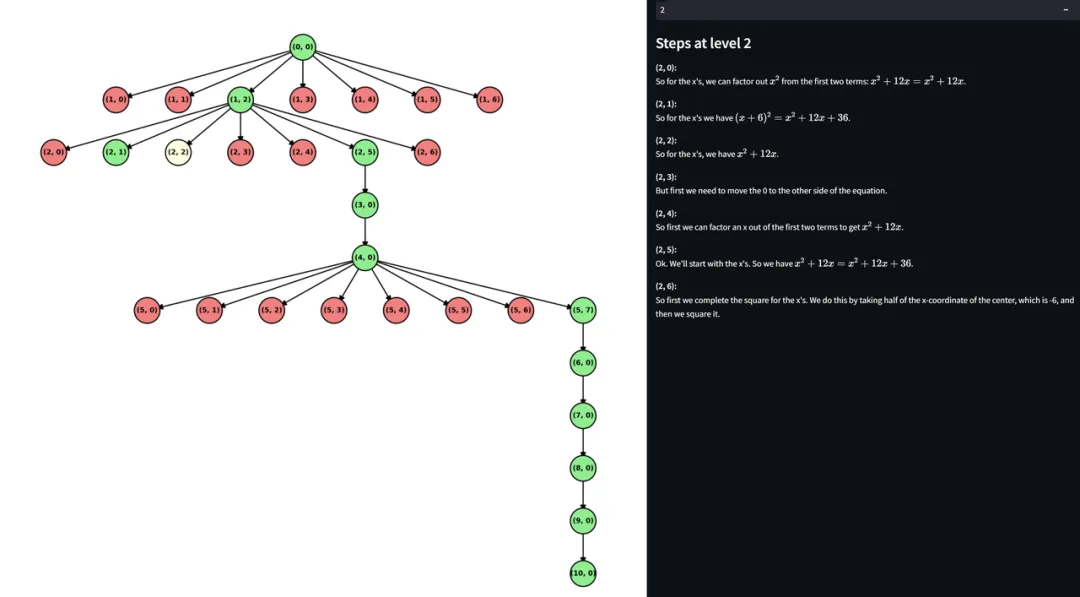
图:通过可交互的数据分析平台可视化构建的搜索树
除了使用特定评估指标在基准测试上测试准确率分数外,人工审查实际案例(输入输出)是评估数据和模型的关键步骤。因此,为了提供一种更直观的方式来评估模型在特定问题上的表现,团队构建了一个可视化数据分析平台。
具体来说,可视化平台包括合成树及其对应长思维的可视化,以及训练模型的输出。此外,在可视化结果时,支持详细的条件过滤,例如过滤正确或错误回答的问题,或输出是否包含表示反思或犹豫的关键词(如 “wait”)。另外,可视化平台支持不同迭代轮次的合成数据和模型输出之间的比较,这使得团队可以非常直观地验证新一轮的数据或模型是否有效。
Q8: 如何训练我们的模型?
团队实验使用预训练语言模型 deepseek-math-7b-base(更多其他模型已经在等待列表中)。训练过程分为两个主要阶段:监督微调(SFT)和直接偏好学习(DPO)。
第一阶段:监督微调(SFT):
SFT 过程包括两个阶段:
- 初始阶段:在这个初始阶段,团队专注于使用只包含正确中间步骤和最终正确答案的响应来微调模型。在 Abel 数据集和 PRM800K 数据集上微调 Deepseek-math-7b-base。对于 PRM800K 中的每个问题,使用单个正确的逐步解决方案,丢弃不导向最终答案的回复。在这个阶段,对每个数据集进行一个 epoch 的微调,主要目的是让模型熟悉所需的响应格式。
- 旅程学习:在第二阶段,使用构建的长思维(包含 327 个示例)进一步微调初始阶段的 SFT 模型。这个阶段旨在增强模型发现错误、自我反思、自我修正和执行回溯的能力。通过在合成的包含试错、反思的长思维数据上训练,模型对更长推理链中涉及的复杂性有更深入的理解。为了比较,团队还在从同一推理树生成的相应捷径上 (Shortcut Learning) 微调模型(同样是 327 个),从而更直观的比较旅程学习相比捷径学习所带来的增益。
第二阶段:直接偏好学习(DPO)
在这个阶段,使用核采样(top_p = 0.95 和温度 T = 0.7)从 MATH Train 数据集为每个问题生成 20 个回复。这 20 个回复根据最终答案的正确性分类为正面和负面响应。从中,随机选择 5 个正面响应和 5 个负面响应来创建 5 对偏好对。然后,使用这些偏好对和 DPO 损失来训练模型,使其能够从正确和错误答案的比较中学习。
Q9: 什么是人类和 AI 协同标注的有效策略?
团队开发了一种人类和 AI 协作的数据标注流程,用于生成基于 MATH 数据集的高质量、长文本推理数据。通过这个流程,我们将短短几行人类标注的解题方案扩展为包含数千个 token 的、符合 “旅程学习” 范式的详细推理过程。在构建流程的过程中,我们发现了下面几种有效的标注技巧:
- 完整的思维过程:标注者不必详细记录每一个想到的词语,但必须记录每一个尝试、反思、联想和修正的过程。这些发散的认知路径在日常思考中可能并未被表达成文字,甚至没有被显式认知。然而,捕捉这些思维转变以及背后的原因是至关重要的。这种规划和理解认知转换的能力是大语言模型从我们的数据中必须学习的核心技能。
- 补充解释常识:人类在用语中经常省略一些可以从上下文中推断的信息,比如对前述公式的引用,或是对广为人知的理论的应用。然而,当大语言模型尝试解读人类标注时,这种省略可能导致幻觉。因此,高质量的数据必须包括对常识性知识的明确解释,以防止大模型的误解。
遵循以上两个关键要素,人类专家即可完成数据标注,这些数据精简但准确,非常利于大模型做进一步增强。下一阶段,通过设计复杂的提示词,我们通过大语言模型实现了数据扩展和增强。我们的提示词包含以下关键点:
- 数据颗粒度的增强:提示词强调将问题解决过程分解为更细小的步骤。通过将过程拆解成细粒度且易于理解的步骤块,大语言模型能更好地掌握和内化每个概念,确保在每个阶段都有深入的理解。
- 逐步推理:提示词控制大语言模型需频繁暂停,反思已知信息或提出下一步的操作。这种停顿模仿了学生在思考问题时的自然过程,帮助他们保持参与感和对推理过程的连接感,而不仅仅是被动地遵循指令。
- 探索者视角:与直接呈现答案不同,大语言模型被鼓励以探索的语气进行推理,即假设自己是第一次思考这个问题。这种方式可以激发某种程度的 “好奇心”,鼓励模型批判性思考,使他们感觉自己是学习过程的一部分,而不是简单地接收信息。
为什么科学进展报告很重要?
研究团队表示:传统发论文方无法适应新的科研范式,人工智能技术的快速发展开创了一个新的研究范式时代,其特点是长期的、基于团队的努力,通常持续六个月或更长时间。这种转变虽然有利于突破性创新,但无意中给科学过程带来了新的挑战。长期团队合作的内向性经常导致向更广泛科学界信息流动的减少。此外,这些项目的长期性质往往导致研究人员满足感的延迟,可能在整个研究过程中培养焦虑和动力减弱。另外,大规模团队项目的复杂性使得认可个人贡献变得复杂,可能侵蚀传统的学术激励结构。团队的进展报告方法旨在通过增强透明度、促进实时反馈和认可,以及鼓励对长期研究计划的持续承诺来解决这些新出现的挑战。在这样的背景下,团队认为 ”Scientific Progress Report“ (科研进展报告)是一种比 现在”Scentific Paper“ (科研论文)更有价值的科研产出和成果分享的组织形式。团队科学探索过程的细致记录,尤其在 AI 能力快速发展的背景下,具有深远意义。通过全面记录探索过程,包括成功和失败,团队正在培育一个独特而宝贵的数据集。这份全面的记录对于训练真正理解科学方法的 AI 模型至关重要。o1 的成功强调了 AI 系统不仅要学习结果,还要学习完整的科学探索过程,包括试错的重要性。通过科研进展报告,不仅可以捕捉技术细节,还包括决策理由、灵感来源和思维过程。这些 “人类因素” 对于训练能够进行真实科学发现的 AI 模型至关重要。
下一步探索
团队根据的研究时间线和取得的进展,确定了几个未来探索和发展的关键方向:
- 扩展长思维的合成: 基于在长思维合成方面的成功迭代,团队计划进行第三轮的数据集成。这将涉及处理更复杂和多样的思维模式,可能揭示 o1 能力的新维度。
- 长思维扩展定律实验: 这个研究流程旨在理解模型的性能和能力如何随着数据、模型大小和计算资源的增加而扩展。对这个规律的掌握对优化方法和挖掘超级 AI 系统背后的基本原理至关重要。
- 细粒度、以思考为中心的评估: 计划开发和实施更复杂的评估方法,专注于细粒度、以思考为中心的评估。这种方法将让我们更准确地衡量生成的长思维的质量和连贯性,为模型推理能力提供更深入的洞察。
- 人机协作以提高思考质量: 未来计划的一个关键部分是探索和增强人机协作,以产生更贴近人类思维的高质量思考数据。这涉及开发利用人类智能和 AI 能力的共同优势,促进 AI 能力的突破。
- 持续改进奖励和批评模型: 基于过程级奖励模型和评论模型设置,旨在进一步完善这些系统。这个持续的过程将涉及迭代改进,以更好地提供细粒度的监督信号。
- 推理树的合成优化: 计划探索从推理树中推导和集成长思维更复杂、有效的方法。这将涉及探索更加先进高效的算法来遍历并利用复杂结构中的信息。
- 扩展训练方法: 未来计划包括进一步实验和完善训练流程。这包括增加预训练阶段、迭代训练、强化学习、偏好学习和 DPO(直接偏好优化)。
- 持续的透明度和资源共享: 将继续分享在整个科研旅程中开发的资源、观察到的结论和工具。这种持续的做法旨在促进更广泛的 AI 研究社区的协作和加速进展。
- 探索多代理方法: 基于在多代理系统方面的初步尝试,计划深入研究这一领域,发现建模复杂推理和决策过程潜在的新方法。
- 完善分析工具: 旨在进一步开发和增强分析工具。这些工具对解释模型输出、跟踪进展和指导未来研究方向至关重要。
通过追求这些途径,不仅推进我们对 o1 能力的理解和复制,还要推动 AI 研究方法的边界。














暂无评论内容