Jina AI宣布推出jina-embeddings-v3,一个拥有5.7亿参数的前沿文本向量模型。它在多语言数据和长文本检索任务上实现了最先进的性能,支持长达8192个token的输入长度。该模型具有针对特定任务的低秩适应(LoRA)适配器,使其能够为各种任务生成高质量的嵌入,包括查询检索、文档检索、聚类、分类和文本匹配。
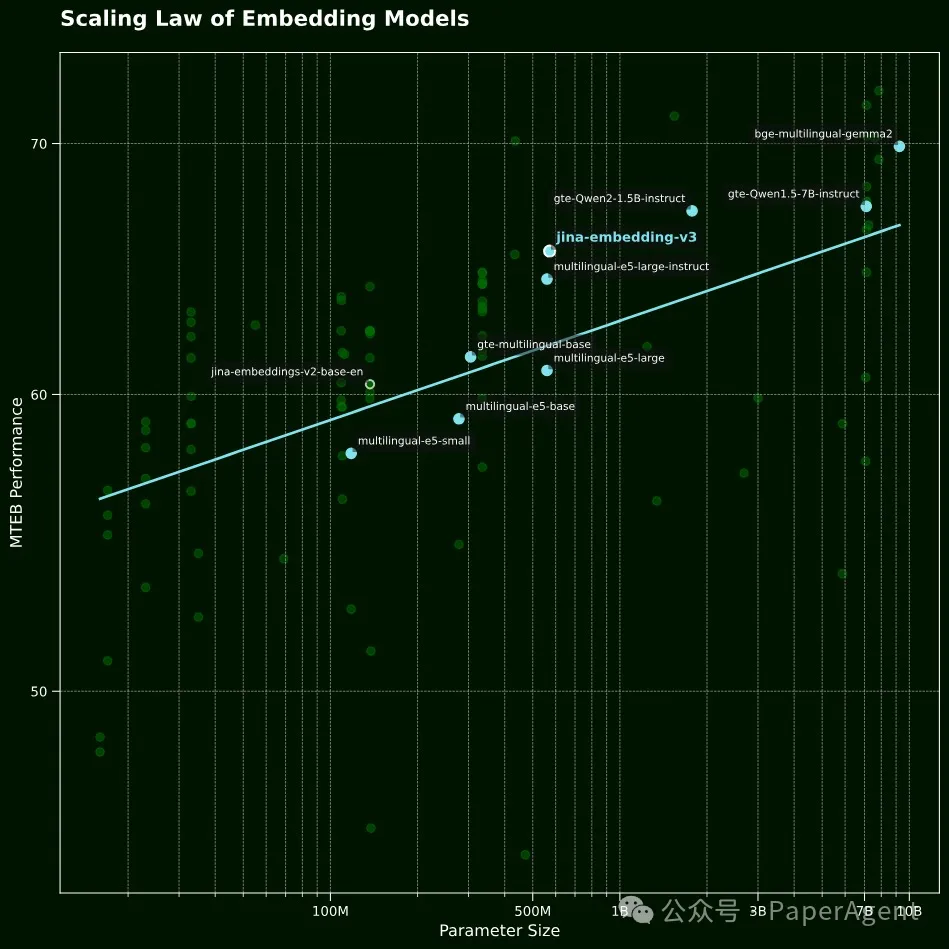
向量模型的规模法则(Scaling Law)。在英语任务上的平均MTEB性能与模型参数数量对比图。可以看出,jina-embeddings-v3与相似大小的模型相比展现出了更优越的性能,同时也显示出比其前身jina-embeddings-v2有超线性的提升。
在MTEB英语、多语言和LongEmbed的评估中,jina-embeddings-v3在英语任务上超越了OpenAI和Cohere的最新专有向量模型,同时在所有多语言任务上也超过了multilingual-e5-large-instruct。
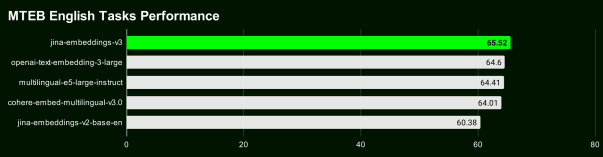
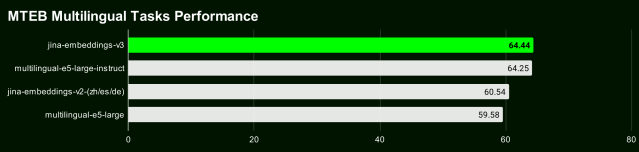

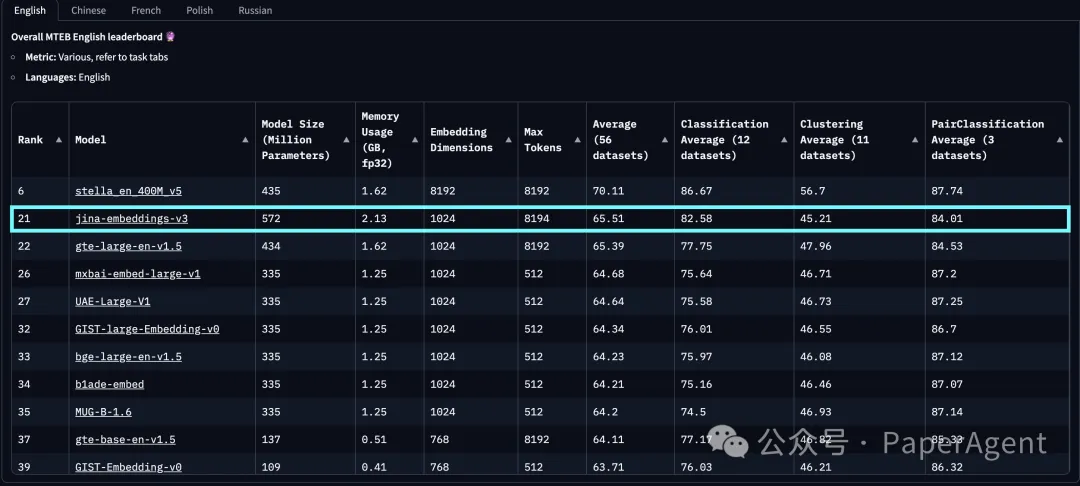
得益于套娃式表征学习(Matryoshka Representation Learning, MRL)的集成,用户可以将嵌入维度任意截断至32,而不会牺牲性能,默认输出维度为1024,支持灵活的维度(32, 64, 128, 256, 512, 768, 1024)截至2024年9月18日发布,jina-embeddings-v3是最佳的多语言模型,在少于10亿参数的MTEB英语排行榜上排名第二。v3总共支持89种语言,包括中文。
 jina-embeddings-v3模型结构
jina-embeddings-v3模型结构
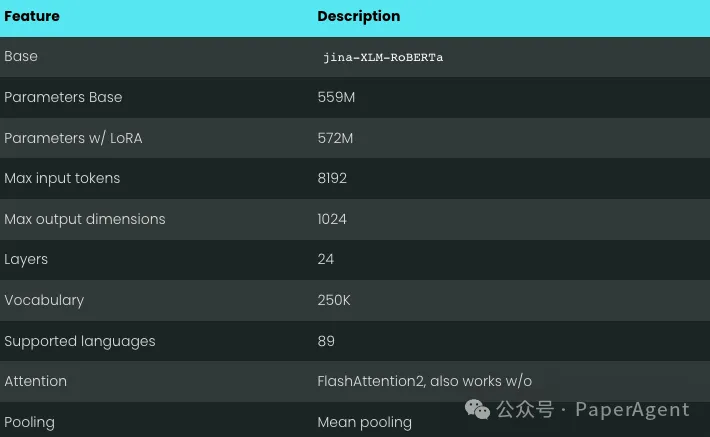
为了实现骨干架构,对XLM-RoBERTa模型进行了几项关键修改:
使长文本序列的有效编码成为可能,
允许特定任务的嵌入编码,
通过最新技术提高整体模型效率。
继续使用原始的XLM-RoBERTa分词器。尽管拥有5.7亿参数的jina-embeddings-v3比拥有1.37亿参数的jina-embeddings-v2要大,但它仍然比从大型语言模型(LLMs)微调的嵌入模型要小得多。
jina-embeddings-v3的架构
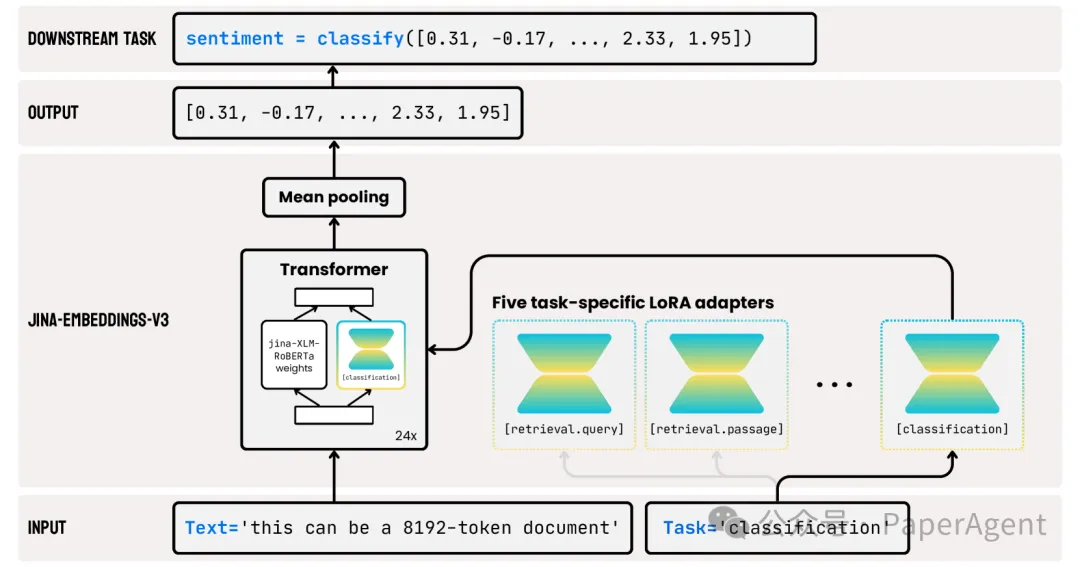
jina-embeddings-v3的关键创新是使用了LoRA适配器。引入了五个特定任务的LoRA适配器,LoRA适配器占总参数的不到3%,对计算的开销非常小。模型的输入由两部分组成:文本(要嵌入的长文档)和任务。5个任务task类型描述















暂无评论内容