Accelerate 发展概况
在三年半以前、项目发起之初时,Accelerate的目标还只是制作一个简单框架,通过一个低层的抽象来简化多 GPU 或 TPU 训练,以此替代原生的 PyTorch 训练流程:
- Acceleratehttps://github.com/huggingface/accelerate
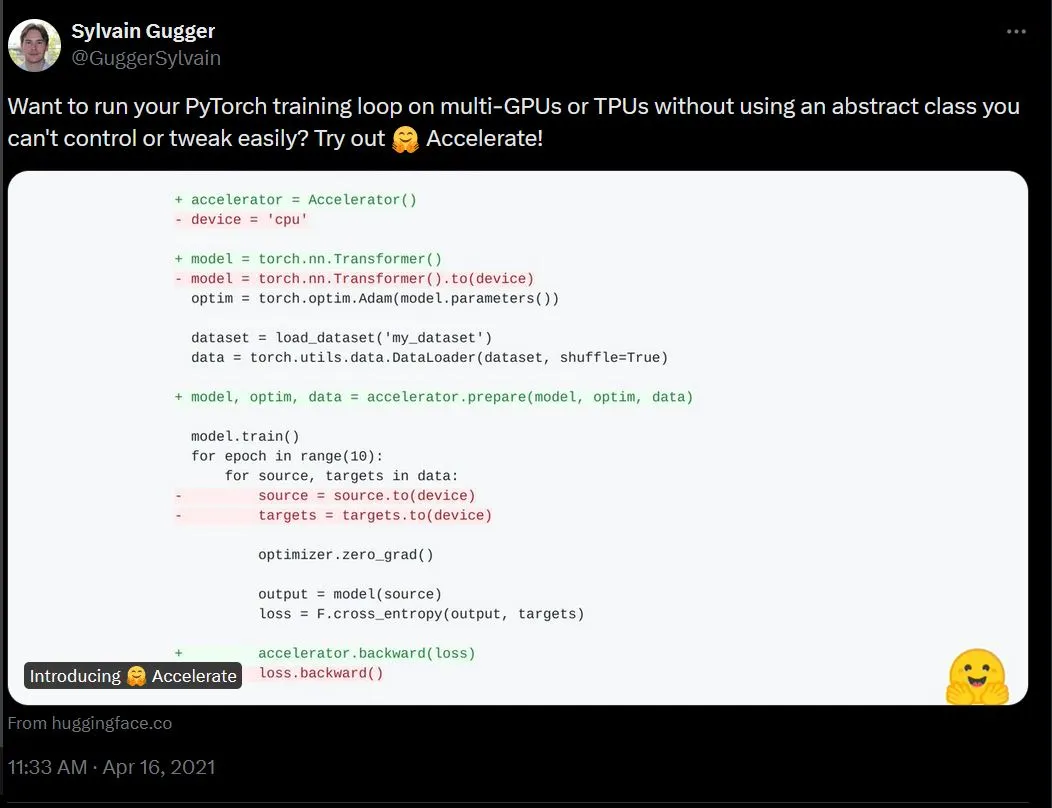
Sylvain’s tweet announcing accelerate
自此,Accelerate 开始不断扩展,逐渐成为一个有多方面能力的代码库。当前,像 Llama 这样的模型已经达到了 405B 参数的量级,而 Accelerate 也致力于应对大模型和大规模训练所面临的诸多难题。这其中的贡献包括:
- 灵活、低层的训练 API: 支持在六种不同硬件设备 (CPU、GPU、TPU、XPU、NPU、MLU) 上训练,同时在代码层面保持 99% 原有训练代码不必改动。https://hf.co/docs/accelerate/basic_tutorials/migration
- 简单易用的命令行界面: 致力于在不同硬件上进行配置,以及运行训练脚本。https://hf.co/docs/accelerate/basic_tutorials/launch
- Big Model Inference功能,或者说是 device_map=”auto” : 这使得用户能够在多种不同硬件设备上进行大模型推理,同时现在可以通过诸如高效参数微调 (PEFT) 等技术以较小计算量来训练大模型。https://hf.co/docs/accelerate/usage_guides/big_modeling
这三方面的贡献,使得 Accelerate 成为了 几乎所有 Hugging Face 代码库 的基础依赖,其中包括 transformers 、 diffusers 、 peft 、 trl 。
在 Accelerate 开发趋于稳定将近一年后的今天,我们正式发布了 Accelerate 1.0.0 —— Accelerate 的第一个发布候选版本。
本文将会详细说明以下内容:
- 为什么我们决定开发 1.0 版本?
- Accelerate 的未来发展,怎样结合 PyTorch 一同发展?
- 新版本有哪些重大改变?如何迁移代码到新版本?
为什么要开发 1.0
发行这一版本的计划已经进行了一年多。Acceelerate 的 API 集中于 Accelerator 一侧,配置简单,代码扩展性强。但是,我们仍然认识到 Accelerate 还存在诸多有待完成的功能,这包括:
- 为 MS-AMP 和 TransformerEngine 集成 FP8 支持 (详见这里和这里)https://github.com/huggingface/accelerate/tree/main/benchmarks/fp8/transformer_enginehttps://github.com/huggingface/accelerate/tree/main/benchmarks/fp8/ms_amp
- 支持在 DeepSpeed 中使用多个模型 (详见这里)https://hf.co/docs/accelerate/usage_guides/deepspeed_multiple_model
- 使 torch.compile 支持大模型推理 API (需要 torch>=2.5 )
- 集成 torch.distributed.pipelining 作为替代的分布式推理机制https://hf.co/docs/accelerate/main/en/usage_guides/distributed_inference#memory-efficient-pipeline-parallelism-experimental
- 集成 torchdata.StatefulDataLoader 作为替代的数据载入机制https://github.com/huggingface/accelerate/blob/main/examples/by_feature/checkpointing.py
通过在 1.0 版本中作出的改动,Accelerate 已经有能力在不改变用户 API 接口的情况下不断融入新的技术能力了。
Accelerate 的未来发展
在 1.0 版本推出以后,我们将重点关注技术社区里的新技术,并寻找方法去融合进 Accelerate 中。可以预见,一些重大的改动将会不久发生在 PyTorch 生态系统中:
- 作为支持 DeepSpeed 多模型的一部分,我们发现虽然当前的 DeepSpeed 方案还能正常工作,但后续可能还是需要大幅度改动整体的 API。因为我们需要为任意多模型训练场景去制作封装类。
- 由于torchaohttps://github.com/pytorch/ao和torchtitanhttps://github.com/pytorch/torchtitan逐渐变得受欢迎,可以推测将来 PyTorch 可能会将这些集成进来成为一个整体。为了致力于更原生的 FP8 训练、新的分布式分片 API,以及支持新版 FSDP (FSDPv2),我们推测 Accelerate 内部和通用的很多 API 也将会更改 (希望改动不大)。
- 借助 torchao /FP8,很多新框架也带来了不同的理念和实现方法,来使得 FP8 训练有效且稳定 (例如 transformer_engine 、torchao 、MS-AMP 、nanotron )。针对 Accelerate,我们的目标是把这些实现都集中到一个地方,使用简单的配置方法让用户探索和试用每一种方法,最终我们希望形成稳定灵活的代码架构。这个领域发展迅速,尤其是 NVidia 的 FP4 技术即将问世。我们希望不仅能够支持这些方法,同时也为不同方法提供可靠的基准测试,来和原生的 BF16 训练对比,以显示技术趋势。
我们也对 PyTorch 社区分布式训练的发展感到期待,希望 Accelerate 紧跟步伐,为最近技术提供一个低门槛的入口。也希望社区能够继续探索实验、共同学习,让我们寻找在复杂计算系统上训练、扩展大模型的最佳方案。














暂无评论内容