位于西雅图的非营利人工智能研究机构——艾伦人工智能研究所(Ai2)最近推出了Molmo,这是一系列多模态人工智能模型,旨在与大型科技公司如OpenAI和Anthropic的专有视觉产品相媲美。本周二,Molmo的发布没有像许多大型AI模型那样受到广泛关注,但它具备了任何顶尖视觉模型所需的所有先进功能。甚至在多个第三方基准测试中超越了 OpenAI 的 GPT-4o、Anthropic 的 Claude3.5Sonnet 和谷歌的 Gemini1.5。Molmo小型模型比其大型模型的性能高出 10 倍。虽然当前的多模态模型可以解释多模态数据并用自然语言表达,但它们的全部潜力尚未得到充分发挥。Molmo 则更胜一筹。通过学习指向其感知到的内容,Molmo 可以实现与物理和虚拟世界的丰富交互,为能够与其环境互动的下一代应用程序提供。
01 模型能力对比—该系统使用了近100万张经过精心挑选的图像进行训练,这比竞争对手通常使用的数十亿张要少得多。因为数据量较小,降低了计算需求,AI的错误率也更低。Molmo系列包括多种不同大小的模型。其中,MolmoE-1B是一个混合专家模型,具有10亿个活跃参数(总共70亿个)。Molmo-7B-O是最开放的70亿参数模型,而Molmo-7B-D则是一个演示模型。最高端的Molmo-72B是该系列中最先进的模型。 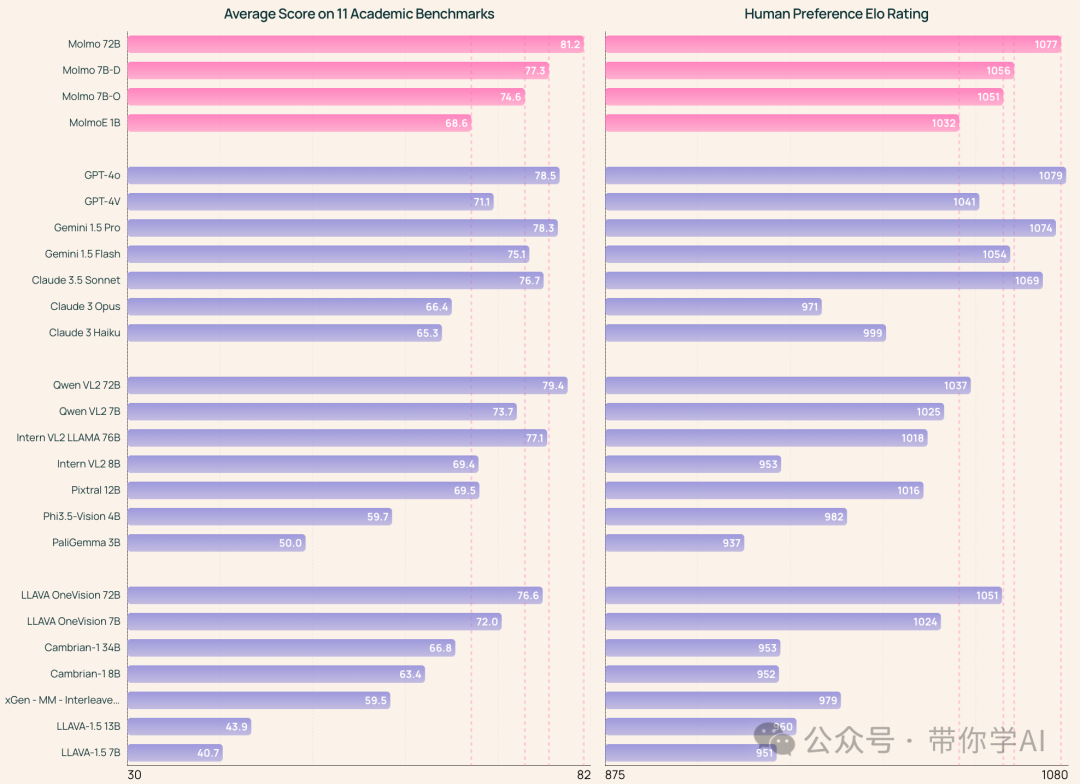 02 模型开放性对比—目前最先进的多模态模型仍然是私有的,而利用开放数据构建视觉语言模型(VLM)的研究进展缓慢。为了改变这一局面,Molmo的创新在于收集了一个全新的图像标题数据集,完全由人工注释者通过语音描述创建。此外,还引入了多样化的数据集组合,允许模型用自然语言和非语言提示进行互动。
02 模型开放性对比—目前最先进的多模态模型仍然是私有的,而利用开放数据构建视觉语言模型(VLM)的研究进展缓慢。为了改变这一局面,Molmo的创新在于收集了一个全新的图像标题数据集,完全由人工注释者通过语音描述创建。此外,还引入了多样化的数据集组合,允许模型用自然语言和非语言提示进行互动。 
Molmo系列不仅在开放性和数据质量上超越其他模型,性能也与GPT-4o、Claude 3.5等专有系统相当。未来,将发布所有模型的权重、代码和数据,让更多开发者和研究者能够使用。03 模型使用—逻辑理解能力:  数学能力(略差):
数学能力(略差):  图片表达能力:
图片表达能力:
 代码能力:
代码能力: 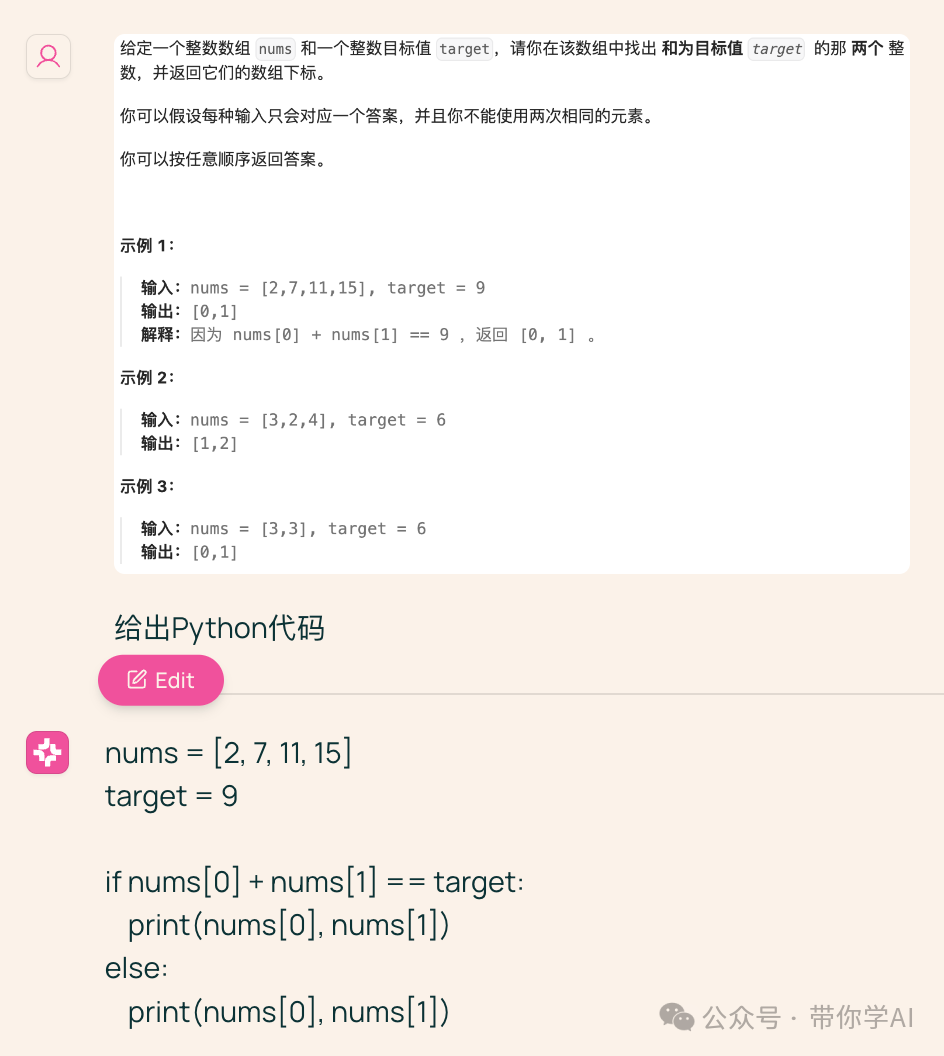 有一点小惊喜,Molmo在官网对国产阿里QwenVL2的评价。《总体而言,学术基准结果和人类评估结果非常吻合,但 Qwen VL2 除外,它在学术基准上表现强劲,但在人类评估中表现相对较差。》
有一点小惊喜,Molmo在官网对国产阿里QwenVL2的评价。《总体而言,学术基准结果和人类评估结果非常吻合,但 Qwen VL2 除外,它在学术基准上表现强劲,但在人类评估中表现相对较差。》














暂无评论内容