Mini-Omni 是一种新型的多模态大模型,它的特别之处在于能够实现语音的实时输入和输出。传统的语音处理模型通常依赖文本转语音 (TTS) 系统,也就是说,它们先生成一段文本,再把文本转换为语音,导致对话时常有延迟。而 Mini-Omni 则跳过了这一步,直接处理语音输入并生成语音输出,完全避免了这种延迟。
这个模型专为语音对话设计,最大的亮点是它能够“边说边思考”。也就是说,在模型开始说话时,它还在继续思考和处理信息,不需要等所有计算结束后才给出答案。因此,它可以在你提问时开始给出部分回应,并在后台继续处理更复杂的内容,直到答案更加完整。Mini-Omni 能够实时理解并回应语音对话,确保流畅的互动体验。这个特性特别适合需要即时反馈的应用场景,比如语音助手、聊天机器人或智能客服系统。
01 主要特点—1. 实时语音交互延迟问题:传统模型需先生成文本再转语音,导致明显延迟,影响体验。Mini-Omni 采用并行生成技术,减少响应时间。它实现了真正的实时语音交互。2. 融合语音与文本推理能力:多数模型擅长文本推理,但语音推理较弱。Mini-Omni 创新架构提升了语音处理能力。它在保留文本推理优势的同时,增强了语音生成。3. 降低模型复杂度与资源需求:“Any Model Can Talk”方法简化了语音集成,减少训练数据和调整需求。Mini-Omni 让其他模型快速具备语音能力。资源和时间消耗因此大幅降低。4.批量推理:该模型包括“音频到文本”和“音频到音频”批量推理方法,以进一步提升性能。
02 技术原理—Mini-Omni 模型的基础是 Qwen2-0.5B,一种拥有 24 层结构和 896 内部维度的转换器模型。为了能更好地处理语音输入,它结合了 Whisper-small 编码器。这种特别的组合让 Mini-Omni 能够把实时语音处理融入到语言理解和生成中。
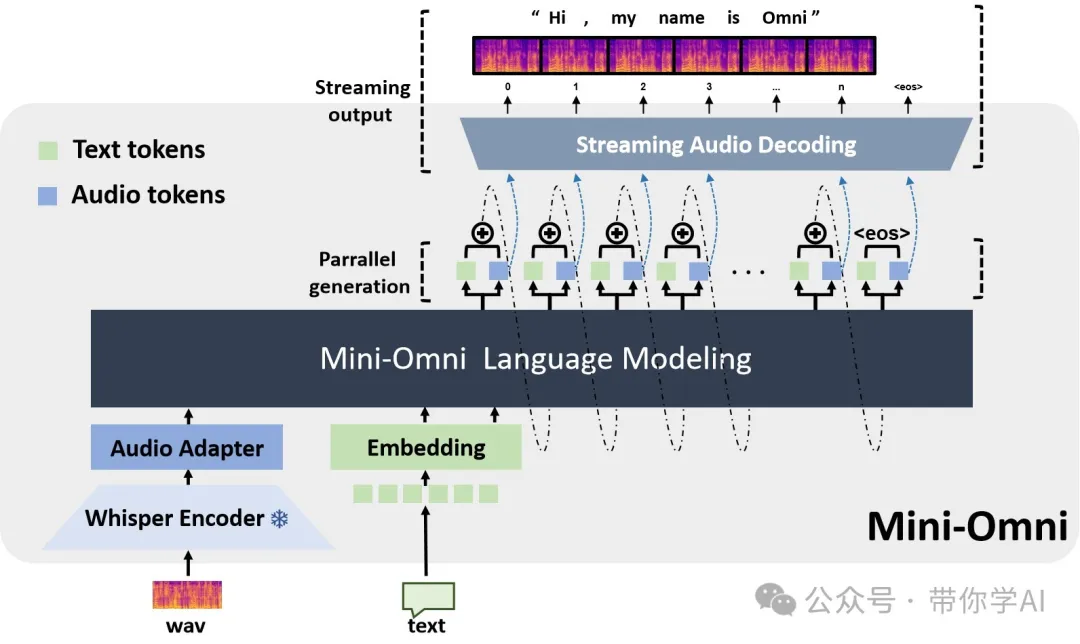
模型在生成语音时,先生成文本 token,再逐步生成音频 token。具体来说,模型会在生成第一层文本 token 后,启动一个名为 SNAC 的音频编码器,同时开始生成音频 token。这个并行处理方式使得 Mini-Omni 能在短时间内生成高质量的音频,保证流畅的对话体验。
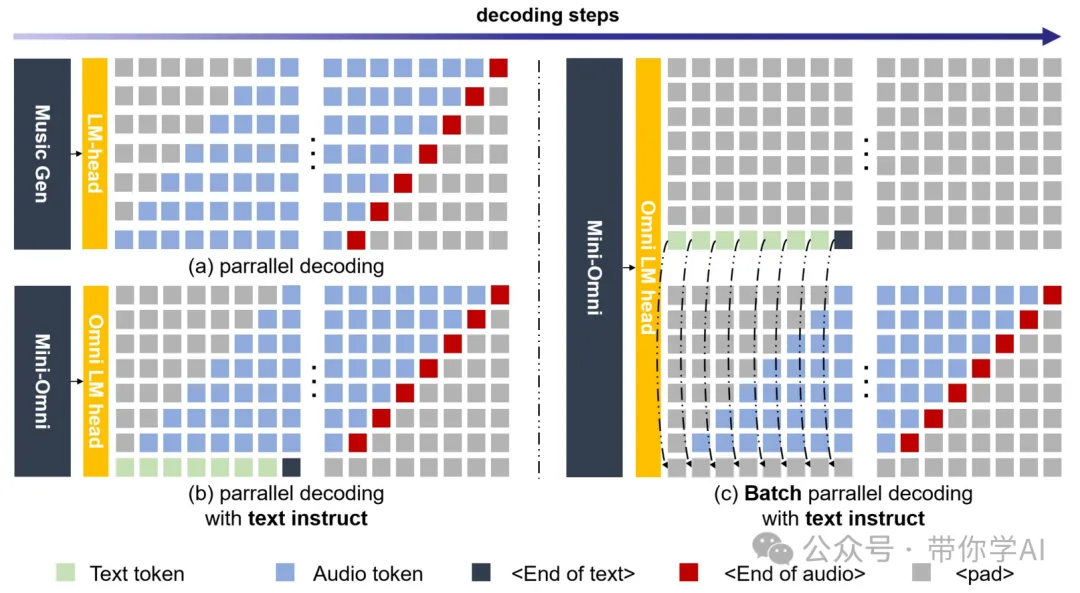
Mini-Omni 还采用了批量并行处理来提高处理文本和音频的效率。模型可以同时生成多段文本和对应的音频,提升准确性和效率。在推理过程中,模型不仅生成文本,还根据文本生成音频,利用两条并行生成路径:一条生成文本,一条生成音频。文本内容嵌入到音频生成中,提升音频生成的推理能力。














暂无评论内容