
最近在OpenAI o1发布以后,OpenAI的研究科学家Hyung Won Chung 放出了去年他在 在MIT的一次演讲,当时他正在思考范式的转变
这次演讲的标题定为“别教,要激励”。我们无法枚举我们希望从通用人工智能 (AGI) 系统中获得的每一项技能,因为它们太多了。在Chung看来,唯一可行的方法是激励模型,从而使通用技能涌现出来

Chung大佬认为,与其手把手教AI各种技能,不如给它设定一个目标,然后“诱惑”它自己去学习。他以OpenAI最新发布的模型o1为例,认为这代表了一种全新的AI训练范式

(什么是“激励式”训练?)
Chung大佬的核心观点是:想让AI掌握所有技能是不可能的,我们应该激励它自己去学习通用技能。 他用“预测下一个词元(next token prediction)” 作为例子,认为这是一种弱激励结构,可以让模型通过学习少量通用技能来解决海量任务,而不是一个个单独处理。
举个栗子🌰:
如果你只想解决几十个任务,那分别识别每个任务的模式可能是最简单的。但如果你要解决数万亿个任务,那学习可泛化的技能,例如语言理解和推理,可能就更轻松了。
Chung大佬还玩了个梗,把那句老话“授人以鱼,不如授人以渔” 进化成了 “让人尝到鱼的美味,并让他感到饥饿”。这样他就会自己去学习捕鱼,并在过程中掌握其他技能,例如耐心、阅读天气、了解鱼类等等,其中一些技能是通用的,可以应用于其他任务。
(慢就是快?)
你可能会觉得,用激励的方式来教AI,比直接教要慢得多。对于人类来说确实如此,但对于机器来说,我们可以通过增加算力来缩短时间。实际上,这种‘看似更慢’的激励式学习方法,反而因为它更具可扩展性,使得我们能够投入更多的算力进行训练,最终获得更强大的AI能力
(通用 vs. 专用?)
这还对“通才”和“专才”的权衡产生了有趣的影响。对于人类来说,这种权衡是存在的,因为专注于某个领域的时间,就无法用于发展通用技能。但对于机器来说,情况就不同了。有些模型可以享受比其他模型多10000倍的算力!
Chung大佬又举了个例子,就像《龙珠》里的“精神时光屋”,在里面训练一年,外面才过一天,相当于时间被放大了365倍。对于机器来说,这个倍数还要高得多。所以,一个拥有更多算力的强通用模型,往往在特定领域的表现比专精模型还要出色
(Chung大佬的呼吁)
Chung大佬希望他的演讲能激发大家对高层次思考的兴趣,这将有助于建立更好的视角,从而找到更有影响力的AI问题。
(彩蛋)
Chung大佬还提到,OpenAI的成功秘诀之一,就是始终坚持“以算力为中心”的理念。他们拥有海量的算力,并不断探索如何更好地利用它,这正是他们领先业界的重要原因。
以下是演讲全文:
Hyung Won Chung 在 MIT EI 研讨会上的演讲:别教,要激励

谢谢!很高兴回来。今天我演讲的主题是“别教,要激励”。我的研究方向是开发通用人工智能,而不是专门的人工智能。在做这项工作时,我们不可能列举所有想教给模型的东西,因为技能太多了,我们甚至都不知道全部的技能。所以在我看来,通往通用人工智能的唯一可行方法是,弱激励模型,让模型自己去探索学习
在我们深入演讲细节之前,我先分享一下今天演讲的目标,这与大多数技术演讲的目标略有不同,因为我不会分享具体的技术内容,比如我最新的论文或实验结果。相反,我想分享一下我如何思考 AI,以 AI 为例。你可能想知道为什么。在我看来,我们这些技术人员过于专注于解决问题本身,在我看来,我们应该把更多的注意力放在寻找好的问题上来解决。在我职业生涯中见过的最好的研究人员,并不一定是技术最强的,他们当然很强,但这并不是他们的决定性特征。相反,他们知道如何找到最有影响力的问题来解决,我认为这来自于拥有一个很好的视角。我认为拥有良好视角的重要性被低估了,我想利用这个机会来分享我的视角。我并不是说我有一个很好的视角,我的希望是,通过分享我的视角,能激发你们中的一些人对这类话题的兴趣。作为一个社区,我们会更多地讨论这个问题,从而更好地找到更好的问题来解决。
所以,让我们开始吧!本次演讲的简要提纲是:首先,我们将分享我的视角,我所说的一切都将基于“规模化”,我稍后将定义我理解的“规模化”是什么。但我们将用非常通用的 AI 研究来发展这个视角,然后我们会将其专门化到我正在研究的语言模型上,这就是总体的视角。让我们从我在整个 AI 领域知道的最重要的数据点开始。
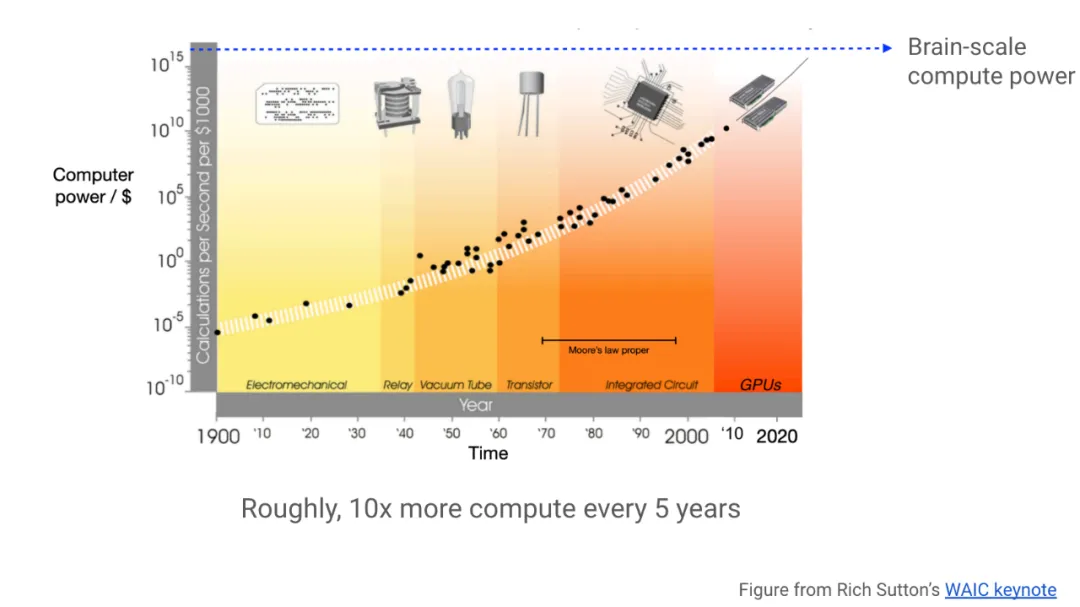
这是 Rich Sutton 去年在主题演讲中提到的内容。横轴是时间,大约从 1900 年到 2020 年,纵轴是计算能力,如果你支付 1000 美元,你将获得每秒的计算次数,这是对数刻度。所以我们看到的是,在 100 多年的时间里,特定美元金额的计算能力呈指数级增长。换句话说,计算成本呈指数级下降,我不知道还有其他任何趋势像这一趋势一样强劲和持久。每当我看到这样一个不可思议的趋势,远远超出我的直觉时,我都会想到两件事:首先,我不应该与之竞争;其次,我想尽可能地在职业生涯和生活的各个方面利用它。
所以我们看到硬件呈指数级爆发式增长,所以我们作为软件和算法开发者中的一部分人,应该迎头赶上。特别是,我们需要更具可扩展性的方法,以便更好地利用日益丰富的计算资源。
更笼统地说,AI 研究人员的工作是教机器如何思考。一种非常常见但很遗憾的方法是,我们教机器我们如何思考,但我们真的知道我们是如何思考的吗?在非常低的层面上,我们并不知道。所以在这种方法中,我们正在教授我们不完全理解的东西,用有限的数学语言,这种方法通常会对问题施加一种结构,当我们进一步扩展时,这种结构通常会成为瓶颈。
Rich Sutton 的另一个教训总结了这种现象,他说,过去 70 年来,AI 的进步基本上可以归结为开发越来越通用的方法,减少结构,并添加更多数据和计算。换句话说,就是扩大规模。这是一个非常强烈的声明,因为我们已经看到了许多不同类型的进步,但所有这些进步都可以概括成这个非常强烈的声明,我完全同意这一点。事实上,我认为这是 AI 领域最重要的文章之一,我多次回顾这篇文章,所以我强烈推荐它,如果你还没有看过的话。
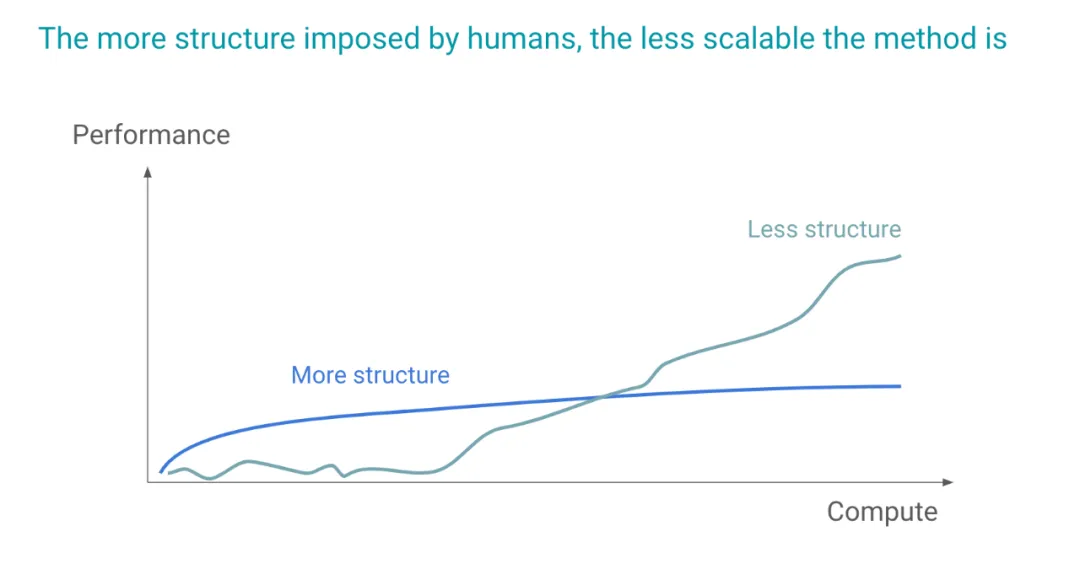
这是我对同一想法的图形化描述。横轴是计算量,你可以将其视为计算量或数据量,或者数据量。纵轴是性能,你可以将其视为某种智能指标,这只是一个示意图。我们可以想到两种方法,一种结构更多,一种结构更少。我们反复看到的是,结构更多的方法通常启动得更快,因为结构本身就是一种捷径,这种方法在遇到瓶颈之前都运行良好,但它并没有真正扩展。相反,结构较少的方法通常一开始看起来不起作用,因为我们给了模型太多的自由度,它不知道如何利用这些自由度,直到我们提供了足够的数据、计算量和良好的算法来利用这些自由度。在某个时候,它会变得越来越好,我们称之为更具可扩展性的解决方案。
一个具体的例子是,当我们使用像 SVM 这样的经典机器学习算法时,可以将其与深度学习进行比较,它更像是一个结构更强的版本。特别是像核方法之类的东西,其结构旨在学习我们应该在数据中加入什么样的表示,而深度学习,我们让模型根据给定的问题学习表示。这种方法一开始不起作用,但最终因为它更具可扩展性而胜出。在深度学习中,我们看到了很多这种层次结构,一种是更具可扩展性的深度学习方法,另一种则不是。
让我们来做一些发人深省的观察:人类研究人员提出的巧妙结构,通常会在扩展时成为瓶颈;从长远来看,好的东西在短期内几乎必然看起来很糟糕。因为我们正在做基于学习的方法,我们试图给机器尽可能多的自由,所以从长远来看会胜出的东西,在短期内看起来会很糟糕。所以这与其他科学领域有着截然不同的动态,计算机变得越来越便宜,速度也比我们成为更好的研究人员的速度要快。所以我们不应该与之竞争,相反,应该给机器更多的自由度,让它们选择如何学习。这可能与人类认为的人类智能不同,但我认为人类智能不是任何形式的上限,我们最终关心的是智能及其创造的价值,所以我们不应该规定它应该是什么样子。
也许这个观察结果对你来说很明显,但至少很多人觉得它并不明显。我想谈谈一个很少被谈及的原因,那就是研究人员想要添加建模思想,因为这在学术上更令人满意,有些人认为仅仅扩大规模是不科学的,甚至没有意义。我经常听到这样一句话:“这只是无聊的工程”。我想问这些人一个问题:我们为什么要研究 AI?我们为什么要为此开发任何技术?我认为最终目标是创造造福人类的价值,这比任何科学家的自我意识都重要。所以我们真的应该专注于最大化 AI 创造的价值,最大限度地减少负面影响,而不管哪个学科实现了这个目标,也不管我研究了 10 年的东西现在是不是最具可扩展性的。我必须真正诚实地面对我真正追求的东西,那就是创造价值。如果不是最具可扩展性的方法,不能以最好的方式利用计算资源,我应该重新思考和学习。我认为这就是我一直以来采取的方法,包括我的研究课题一直在变化,但在更好地利用计算资源这一主题上,它并没有改变。所以,我一直在用一种比较宽泛的方式谈论“规模化”,我想更精确地定义我所说的“规模化”是什么意思,因为它与常用的定义略有不同,常用的定义是:用更多的机器做同样的事情。我认为这是对的,但没那么有趣。我的版本包括:首先,确定阻碍进一步规模化的建模假设或归纳偏置;其次,用更具可扩展性的方法替换它。
如果我们考虑前面提到的 SVM 与深度学习的例子,我认为这是一种规模化,因为我们想投入更多的计算资源,而 SVM 正好是瓶颈,我们发现数据表示是瓶颈,并用学习表示来代替它,我认为这就是我理解的规模化,我认为这是一种更有趣的规模化类型,有很多这样的例子。在我个人看来,OpenAI 相对于其他地方做得非常好的一点是,那里的研究人员真的很遵循这种理念,无论是有意识的还是无意识的,这正是我们正在做的事情。我们有这么多可用的或即将可用的计算资源,问题是如何投入它们?实际上,如果你仔细想想,这很难。如果我给你 1000 亿美元的计算资源,你能现在就正确地使用它吗?我不认为有人真的知道如何做到这一点,所以我们真的在寻找一种方法来投入越来越多的计算资源,这就是研究人员的工作。
所以这就是我的视角,我接下来要谈的一切都将基于这种规模化和“惨痛教训”。所以让我们来谈谈语言模型,我把它写成大型语言模型(LLMs),因为它是一个常见的缩写,但我认为这两个“L”都没有什么意义。“大型”是一个非常主观的词,今天的“大型”模型在几年后,甚至明年就会变成“小型”模型。另一个“L”,语言,我将谈谈为什么我认为它不是一个好词。
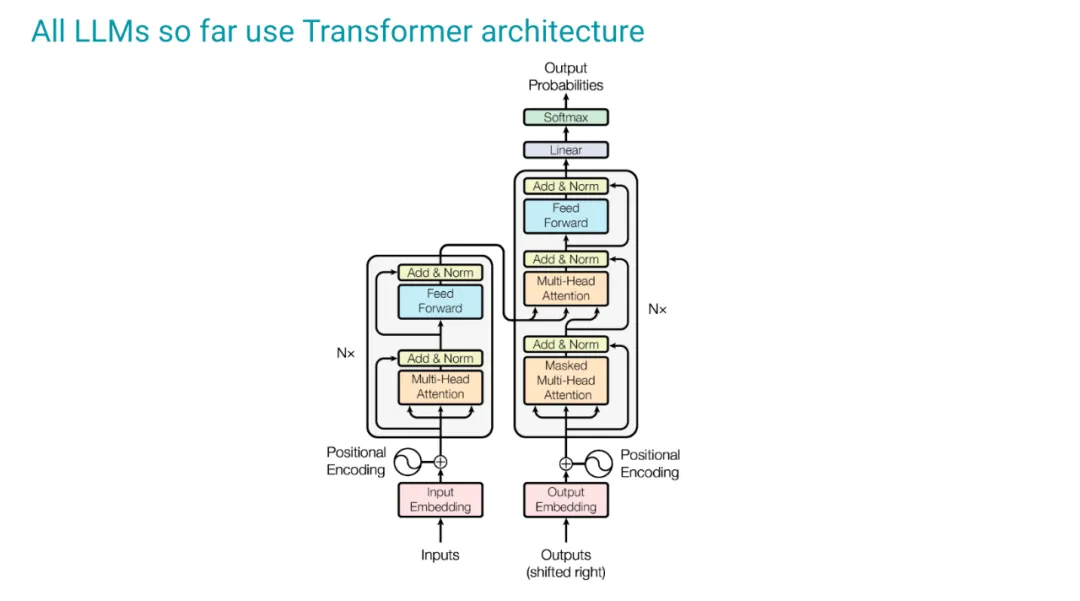
到目前为止,所有 LLM 都使用 Transformer 架构,我们不必深入研究细节,我们将采用一个非常功能性的视角,并将 Transformer 视为一个序列到序列的映射,它只是一堆模块的输入。输入是一个向量序列,每个向量的大小为 d,总共有 n 个向量,输出也是一样,至少在训练期间是这样的。交互是由一堆模块完成的。
因为我们的受众可能比较多样化,所以我只是想让大家达成共识,对下一个词元预测过程做一个速成课程,并探讨一下这个过程的一些含义。所以我们从序列模型开始,我们可以想到的一个特定序列是一个句子,它是一个词语序列。第一步是将其标记化,为什么要这样做呢?因为我们需要在计算机中表示这些词语,这需要某种编码机制。在这里,我们通常使用这种整数映射,我们定义一个有限的整数集,比如在这个特定的例子中是 30000,我认为。每个词语或词元都被映射到一个整数,这个整数在训练过程中会发生变化。所以现在我们有了一个整数序列,而不是字符串序列。我们现在可以进行嵌入,这不是必须的,但这是一种更常见的做法。现在,序列中每个元素(在本例中是一个词元)的整数表示都被表示为一个大小为 d 的向量。

现在让我们从基本原理来思考我们想从序列模型中得到什么。序列模型是一个模型,它对序列中元素之间的交互进行建模。因此,Transformer 是一种特殊的序列建模方式,其中交互被建模为一堆点积。所以我们取两个元素的向量表示,计算它们的点积,如果点积很高,我们就认为这两个元素在语义上是相关的,比点积低的另一对元素更相关。我们并没有真正规定语义上的含义,我们可以尝试去理解它,但我认为这并不容易,或者说没有意义。所以在进行一堆点积之后,我们得到了相同大小的向量表示,但现在每个向量都知道了其他向量存在,并希望以某种方式衡量它们之间的相关性,并对正在发生的事情有深刻的理解。
这个过程的最后一步是取损失函数,我们需要一个标量,因为我们想使用基于梯度的优化方法。这样我们就得到了一个标量,现在计算这个标量相对于模型中所有参数的梯度,然后使用某种梯度下降方法进行更新,这是一步。尽可能多地重复这个步骤,这就是训练过程。
接下来,让我们来谈谈从向量表示到单个标量的过程,这个标量是优化目标函数,在本例中,大多数大规模训练现在都使用某种形式的下一个词元预测,所以我认为值得更详细地研究它。

我把这句话(Many words don’t map to one token:indivisible)放回这张幻灯片中。所以我们正在做的事情本质上是,给定前面的许多词元,尝试预测下一个词元。正如我提到的,这种编码机制,我们从一个有限的词汇表开始,比如说有 10 万个条目。模型输出的是这些条目上的概率分布,所以这里的数字加起来应该是 1。我们希望模型能够学习到这种结构,使得下一个词元(单词)获得比其他词元更高的概率,比如“intelligence many intelligence” 就没有意义。在那之后,我们再次这样做,给定“many words”,尝试预测下一个词元,也就是“done”,以此类推,直到结束。所以这就是这个过程,你一直做到最后。
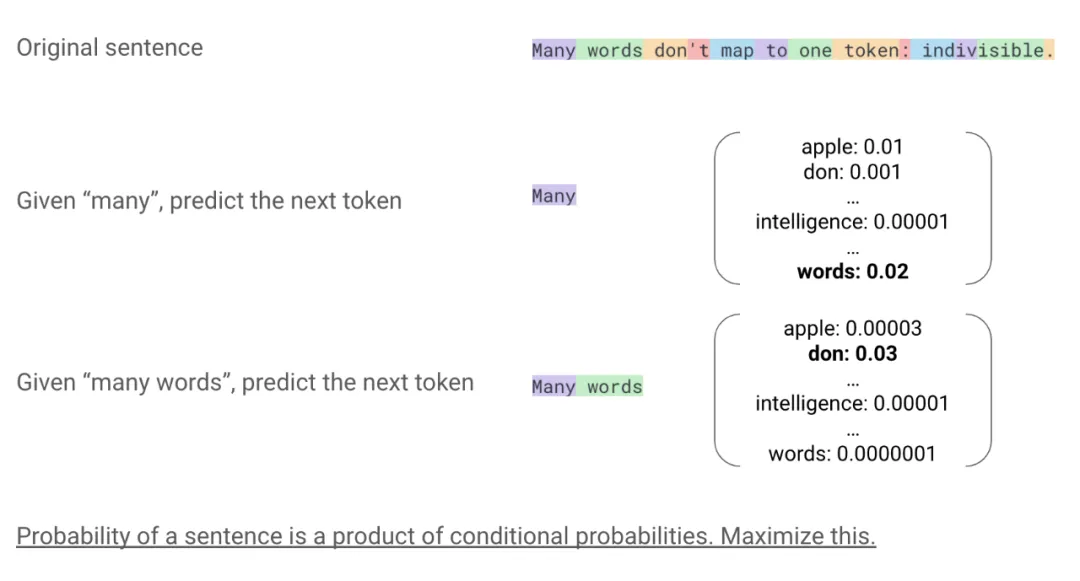
这表示条件概率,我们给定所有先前的词元,尝试预测下一个词元。对于有统计学背景的人来说,一个等价的,也许更自然的方式是,我们将这些条件概率相乘,得到整个序列的概率,这就是我们要最大化的,这就是最大似然框架。但我认为将其视为多任务学习更直观,每个任务都是在给定之前所有内容的情况下预测下一个词元,至关重要的是,每个预测的权重相同,我们不会区分哪个词元是什么。
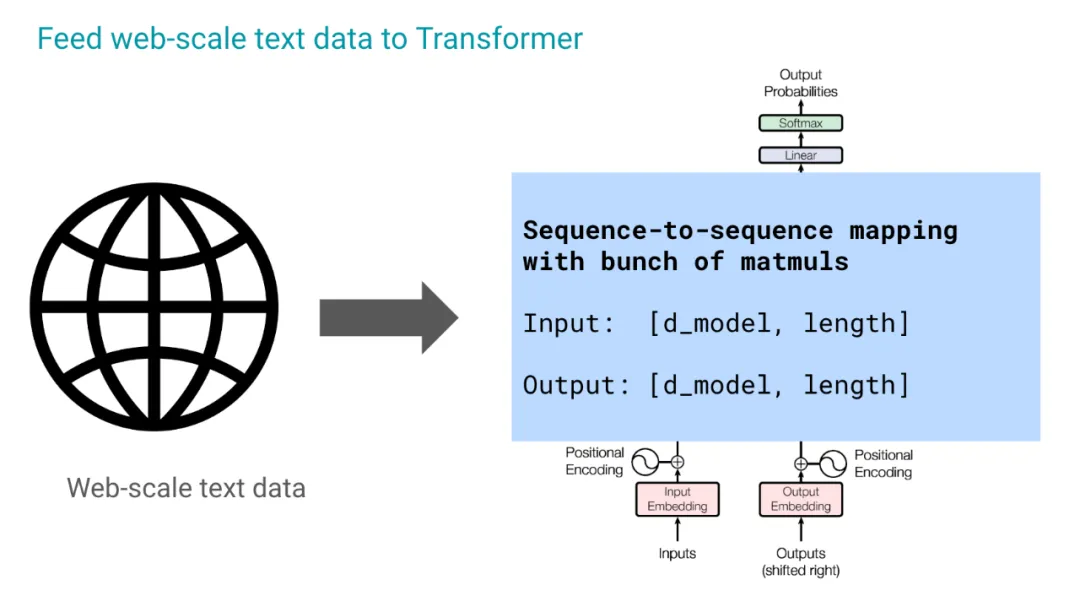
在工业规模下,我们只是在网络规模的文本数据中这样做,将其输入到 Transformer 中,这就是魔法发生的地方。
那么会发生什么样的魔法呢?
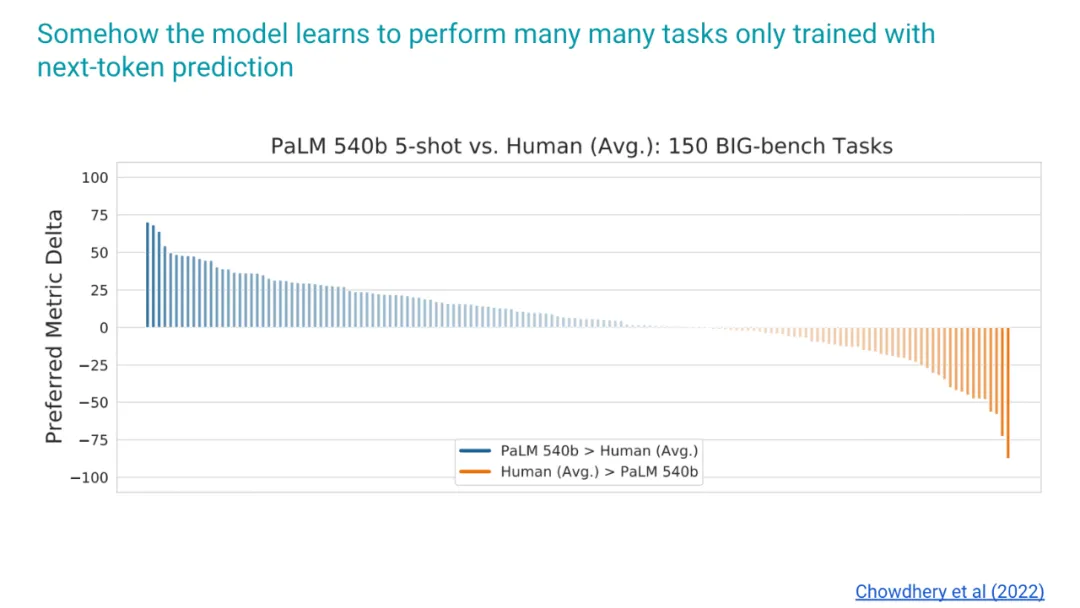
这是一篇来自 PaLM 论文的内容,当我们在 Google 工作时。我选择这篇论文的原因是,现在人们通常不会报告仅预训练的结果,所以如果你想了解下一个词元预测本身的性能,我们不得不回到这篇旧论文。细节并不重要,这是一些 BigBench 任务,我们展示的是,仅仅通过预测下一个词元,实际上已经比许多人类的平均表现要好了。我不知道,但对我来说,仅仅做下一个词元预测就能在这么多不同的事情上做得更好,这简直就是魔法,我仍然觉得这非常令人惊讶。
我认为我们不应该认为这是理所当然的,所以让我们对下一个词元预测做一些观察。我们没有直接教授任何语言学概念,比如下一个词元是动词,下一个词元是什么,我们不做任何这样的事情。但不知何故,仅仅通过预测下一个词元,语言就出现了,就像一个副产品,我认为这几乎是做这种测试的副产品,语言是习得的。我甚至会更进一步说,教授语言的最佳方式是不教授语言,因为我们不想在机器学习语言的过程中加入任何结构,所以这是一个非常有趣的副产品,这就是为什么我认为“语言模型”中的“L”有点用词不当,因为我们没有教授任何语言。语言模型是关于学习一些世界知识,语言只是其中一种表现形式。
所以另一个有趣的事情是,模型可以做一些推理、数学和编码,所有这些事情,即使我们没有专门教授它。所以我想我认识的所有研究人员,基本上都对为什么这种方法效果这么好有一些假设,我不认为有任何共识,为什么这种方法这么好。我确实有我自己的版本,这对我思考我的研究项目很有帮助,所以我想分享一下。我的版本是,这是一种大规模的隐式多任务学习,隐式的意思是我们没有直接指定我们要让模型做什么多任务,它们只是由我们使用的各种语料所施加的。
所以,让我们来思考一下,我们现在认为语言模型做得很好是理所当然的,但思考一下模型在训练过程中经历的痛苦,这可能是有用的。所以让我试着说明一下预测下一个词元是什么感觉,在这里我将展示一个句子,下划线部分是我试图预测的内容。在这样做的时候,让我们尽可能少地付出努力,尽可能地走捷径。所以如果我想预测“the terrible movie was really”,然后尝试预测“boring”,我可能会走捷径,说“terrible”是负面的东西,所以它会是负面的东西,然后是“movie”,所以也许我可以用模式匹配来得到“boring”这个词。现在我再给你一个句子,“after the earning call the share price of Google went up by 5% from, ending in 1050”。这里因为我想尽可能少地付出努力,我想我能不能重复利用我从第一个例子中学到的技能来做这件事?答案是不能,因为这是不相关的,我必须学习某种新的技能,也就是数学。第三个例子,它是一种完全不同的语言,所以我不能重复利用这些技能,因为我需要学习新的语言,这是我学到的第三个技能。第四个,“the first law of theer dyamics”,这是我最喜欢的课题,过去是,被称为能量守恒。现在为了预测这一点,我们需要知道,我们不能重复利用上面的任何东西,必须学习一项新的技能,那就是科学知识,以此类推。当我们在网络规模上做这件事时,我们谈论的是数十亿甚至数万亿个句子,因为每个句子包含多个下一个词元,大概有数千个,我们谈论的是数万亿种可以像这样构建的任务类型。如果你试图解决这个问题,在某种程度上,即使对于大型模型来说,这也是难以解决的,这看起来不像是一件可以解决的事情。我认为如果我们真的想以尽可能少的努力来做到这一点,也许更不可避免的是思考,我可以学习哪些通用技能,并将其应用于尽可能多的任务类型?这可能是更容易的途径。现在,如果我们给模型足够的负担,给它数万亿种任务类型,我认为这是我对多任务学习假设的一种非常模糊的思考方式,超过一定的规模,这样做更容易。
我所说的通用技能是什么呢?首先,这些是文本数据,所以理解语言可能是我想学习的东西,即使我们没有教授任何关于语言的知识。所以可能有数百种语言被输入到模型中,所以学习所有这些语言可能非常有用,至少可以理解它们的语法结构。其次,在那之后,我想理解语言,这样我就可以,这几乎适用于大多数句子的下一个词元预测。第三,也许更像是推理,将我正在编造的概念组合起来,但我认为如果我正在做这项任务,我可能会想到这些,在某种程度上,这就是给模型的压力。
所以,至关重要的是,我们没有直接教授任何这些通用技能,它们只是被这个学习目标和数据所激励,这些能力就出现了。出现的能力通常更通用,可能是因为它是由发展通用技能的需要驱动的。所以你可能会想,这种弱激励模型需要更多的计算资源,因此这是一个低效的过程。我想这样思考,它能够添加更多的计算资源,我们将来会有更多的计算资源,这是一种更具可扩展性的训练策略,我认为这就是为什么它做得这么好的原因。
也许让我们把这个假设概括一下,对于给定的数据集和学习目标,有一个显式学习信号和一组诱导激励。所以对于下一个词元预测,显式信号是预测下一个词元,因为这是给定的任务。诱导激励是学习通用技能,这样它就可以尽可能多地完成任务,比如理解语言、推理等等。
还有什么其他的例子呢?以下棋为例,在游戏结束时获得 0 或 1 的奖励。如果你想想 AlphaGo Zero 这样的东西,显式信号是赢得比赛,我们除此之外什么也没教。所以在这种情况下,诱导激励是学习什么是好的棋步,模型甚至可能不会考虑什么是好的,以及好的概念,但这就是它必须知道的激励,某种程度上,才能赢得比赛。如果在下棋中,环境非常狭窄,这可能无关紧要,但如果我们使用这种过程,它学到的东西,赢得比赛可能很重要,但在这个环境中什么是好的的通用概念,是非常通用的东西,我认为我们应该越来越关心这一点。
第三个例子可能与现在更相关,我认为幻觉是语言模型尚未解决的核心问题之一。所以这里有一个例子,我从 John 的演讲中得到的,并根据我的目的进行了改编。假设我们正在做简单的问答,模型在回答简单问题时出现了幻觉,我们可以定义这样的奖励结构:如果答案是正确的且没有hedge,则奖励为 1;如果答案是正确的,但模型说“我不太确定,但可能是这样”,则奖励为 0.5;如果模型说“我不知道”,这是一个重要的答案类别,则奖励为 0;如果答案是hedge但错误的,则奖励为 -2;如果模型非常自信地给出了错误的答案,则奖励为 -4。在这种结构中,显式信号是什么?是正确回答问题,这是显式信号。但是,如果我们用数万亿个问题来做这件事,会诱导出什么呢?模型需要知道它不知道什么,让我解释一下这是什么意思。所以这里,如果我给你 100 个问题,你知道其中 50 个问题的答案,你可以记住,好的,这个问题我不知道答案,等等。但如果我给你数万亿个问题,那么思考起来更容易的是,与其跟踪这数万亿个问题中哪些我知道哪些我不知道,不如思考知道某事意味着什么,不知道某事意味着什么的通用概念,这种能力可能是从这种诱导激励结构中产生的东西,我认为这是解决幻觉问题的唯一根本方法。
也许只是给你一个关于这个过程的粗略类比,我们有句老话,“授人以鱼,不如授人以渔”。所以你可以把第一个想成是硬编码,第二个是直接教授一项技能。那么,针对这个问题,基于激励的方法是什么呢?是让人尝到鱼的美味,并让他感到饥饿。然后,如果这个人有能力,他就会出去学习很多技能,包括钓鱼。在这个过程中,诱导激励是他会学习其他一些东西,比如耐心,学习天气,了解这种鱼喜欢什么诱饵,等等。这些技能中的一些可能是更通用的,比如耐心就是一项非常通用的技能。所以这就是我对此句老话的粗略类比。

看着这个,你可能会想,这效率很低,你为什么要这样做呢?在实现目标和花费时间之间存在一种权衡,更笼统地说,我们考虑的是在这种情况下存在的一种权衡,当存在权衡时,我们考虑的是一种稀缺资源,在这种情况下,它是完成这项工作所需的时间。所以如果我们把它画在横轴上,表示每种方法完成工作所需的时间,激励他学习这门技能,抱歉,钓鱼技能本身需要更多的时间。但这种限制是针对人类的,对于机器来说,当我们考虑权衡时,我们谈论的稀缺资源不是时间,是时间,但越来越多的是所需的计算资源,我们可以避免这种情况。这有一些非常丰富的含义,其中之一是,我经常听到有人说,我们有一个小的专家模型,可能比一些通用的“大型”模型要好。当我听到这句话时,这里隐藏的假设是,小型专家模型可以在狭窄的领域中获胜,因为在成为专家和通才之间存在某种权衡。我认为这是我们作为人类产生的偏见,为什么呢?因为同样是权衡,我们想考虑稀缺资源,那就是时间。大多数人都在几乎相同的时间预算下运作,比如你可能会少睡一个小时或多睡一个小时,但大致上每天 16 或 17 个小时,这就是给人类的时间。正因为如此,没有花在成为通才上的时间,就是花在成为专家上的时间,反之亦然,所以这就是权衡。
但对于机器来说,根本不是这样的,一个模型可以享受比其他模型多得多的计算资源。所以如果你喜欢《龙珠》,里面有一个精神时光屋,你在里面训练一年,外面才过一天。所以在这种情况下,能够使用这种东西的人,比其他人多了 365 倍的时间。但当我们谈论机器时,乘数不仅仅是 365,它要高得多,我认为这就是现在的情况。所以我不认为这种权衡根本存在,如果说有什么区别的话,那就是通才实际上更擅长处理特定的事情。
你可能会想,这种激励结构,这是一个非常古老的想法,如果说有什么区别的话,整个人类文明可能是由激励驱动的,甚至进化也可以被认为是一种生存的激励结构。那么,为什么我要谈论这个古老的想法?为什么它现在变得重要了呢?这是我需要提到的。让我从这一点开始,再多的香蕉也无法激励猴子进行数学推理。所以即使奖励是无限的,激励结构是完美的,这也不会奏效,这是不可能的。这意味着,对于给定的问题,需要某种阈值智能才能与激励结构一起工作。目前,像 GPT-4 这样的模型已经跨过了许多任务的阈值,所以我认为现在考虑基于激励的结构来教模型我们关心的事情,绝对是有意义的。
这就引出了一个概念,这种激励结构取决于模型大小或模型规模,出现的能力取决于模型大小,这是一个有趣的参数。如果模型太小,模型可能会放弃发展这些通用技能,而只是满足于在训练过程中损失较高,使用简单的启发式方法。
所以这就是关于激励结构的部分,我一直都在用一种比较宽泛的方式谈论能力的涌现,我想谈谈这个。特别是,我们谈论的是当我们扩大规模时,一些能力会涌现出来,这需要我们有正确的视角。在这个领域,我们有一些讨论,关于涌现能力是海市蜃楼,或者涌现能力不会发生,诸如此类。我不认为细节很重要,让我告诉你一种思考它的方式。我制作了一个最小的 Transformer 模型,模型维度是 1,只有两层,最小的 Transformer 模型。然后选择一个 GPT-4 可以完成的任务,比如数学,然后用这个模型来解决它,它不会奏效。但 GPT-4 可以完成,所以这里存在某种拐点。对于任何问题,你都可以找到一个最小的模型,它无法完成这个任务。如果当前的模型可以完成,对我来说,这就是涌现。所以我认为很容易证明它确实发生了,如果它没有发生,那么它可能对我来说不够有趣。
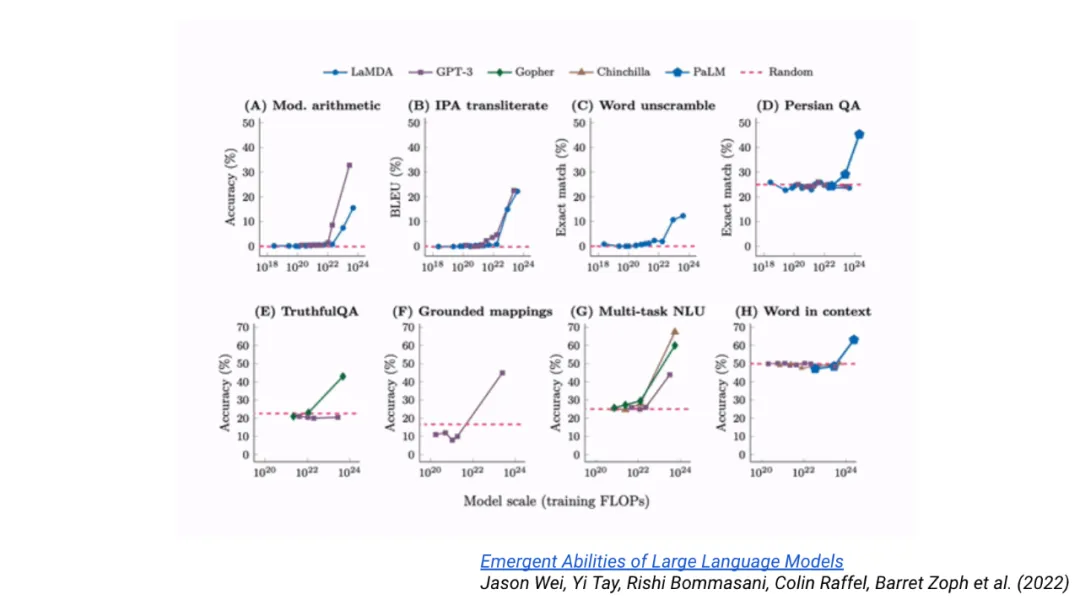
这就是我的意思,横轴是某种规模,然后它不起作用,然后在某个时候,它突然涌现出来。并不是对所有事情都适用,但对于许多有趣的事情,比如推理,这是我们反复看到的模式。
第一个视角是,我们真的需要思考这种视角,也就是“还”。因为现在不起作用的东西,并不意味着以后就不会起作用。所以我们应该做的,不是说这个想法行不通,而是说这个想法现在还行不通,这对人类来说真的不自然。我认为这是因为我们在这个环境中运作的方式存在巨大的偏见,我们所处的环境的基本公理不会经常改变,这就像物理学。所以如果你现在做热力学实验,你得到了结果,三年后再做同样的实验,结果可能还是一样的。事实上,300 年后可能还是一样的,我们已经习惯了这种环境。因为我们所处的基本公理是物理学,而对于语言模型,与公理等价的概念是什么呢?它更像是最有能力的模型。
所以在 2020 年,当 GPT-3 出现时,它成为了研究人员建立关于如何利用这种技术的直觉的公理。GPT-4 去年出现了,它改变了很多东西,许多建立在旧模型之上的东西都不再适用。这几乎就像每隔几年,我们就搬到不同的星球,物理学的理解也发生了变化,这就需要一种不断地去学习的过程。建立在这些不正确公理之上的直觉和想法现在必须被摒弃,但我认为这种情况并不经常发生。
这对新人来说是一个有趣的动态,在这个领域,我经常看到,没有太多研究经验的本科生进来,一年后他们就写出了改变整个领域发展轨迹的论文。如果你想想理论数学或物理学,我认为这是不可能的,除非你回到高斯时代之类的。所以这是一个非常有趣的动态,如果你没有太多的知识,你可能会认为自己没有太多的包袱需要去学习,你更灵活,至少我就是这样想的。OpenAI 的很多人不是传统的机器学习博士,他们更像是,当他们看到证据发生变化时,我们总是会采用新的范式,所以我认为这真的是一个非常重要的动态,我想指出来。
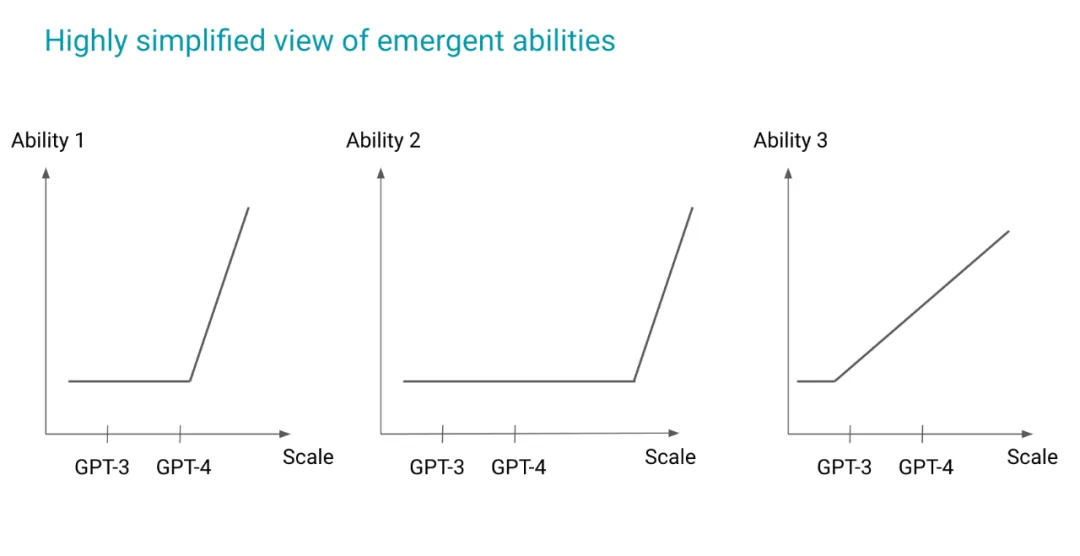
我如何思考这个问题呢?再说一遍,最后一个示意图,然后我们可以总结一下。这是涌现能力,如果我们把横轴想成某种规模,纵轴想成能力,我放了两个不同大小的模型,3 和 4,这没关系。我们先来看能力 1,对于能力 1,GPT-3 和 4 都在拐点之前,所以这是不可能的。但只要比 GPT-4 好一点点的模型,就可能看到一些生命迹象。能力 2 需要更长的时间,能力 3 即使是 GPT-3 也能够做到,例如这可能是情感分析之类的事情。
所以我的意思是,每当我们看到这种能力时,因为我们没有任何关于涌现能力的理论,所以无法知道我正在研究哪种能力。但至少有这样一幅视觉图像,我可以利用它来让自己做好准备,作为一个务实的人,我不想研究像能力 2 这样的东西,我想研究能力 1,并为下一个模型做好准备,思考为什么这不起作用,我可以把更多的计算资源放在哪里,才能看到生命迹象,也许少一些。这种渐进式的东西并没有什么错,但如果我正在研究小型模型已经可以做的事情,我需要知道它的改进空间是有限的。
让我用一些总结来结束这次演讲,我们已经谈到了最重要的潜在驱动力,那就是计算成本呈指数级下降,AI 研究人员的工作是认识到这一点,而不是与之竞争,而是通过设计更具可扩展性的方法来利用它。当前一代的语言模型依赖于下一个词元的预测,这可以被认为是一种弱激励结构,它需要学习通用技能,以便处理数万亿种任务类型。更笼统地说,我们应该开始思考,下一个词元预测已经很棒了,但它不是唯一的方法,我们真的应该为模型考虑激励结构,这是一种我们应该真正参与的新学习范式。涌现能力会发生,这是语言模型的独特之处之一,所以我们需要有一些正确的视角,比如去学习那些基于过时公理的东西。
就是这样,谢谢!














暂无评论内容