传说中的 Sora 公测还遥遥无期,「卷王」可灵又又又上新了。
要知道,自今年 6 月发布以来,仅三个月,可灵 AI 就迭代了 9 次。
这次它还直接把基座模型升级了,推出可灵 1.5 模型。
那么,这个新模型到底强在哪儿?
举个例子,我们输入同样的 Prompt:一位女生看到一封信后悲伤起来,不停地哭泣。
1.0 模型的效果是这样的:

1.5 模型的效果则是这样:
一言以蔽之,可灵 1.5 模型不仅显著提升画质,直出 1080p 视频,还让画面主体的动幅更大、质量更高,文本响应度也更强。
甚至官方还放出「豪言」,与可灵 1.0 模型相比,1.5 模型的内部评测整体效果提升 95%。
同时,可灵 AI 还在图生视频中引入了全新的「运动笔刷」功能,进一步提升对视频生成的精准控制能力。

别看可灵 AI 拿出了不少宝贝,但加量不加价,生成价格不变,一则高品质模式视频仍是 35 个灵感值。
国外网友已经玩疯了,甚至一度把服务器挤崩溃。

废话不多说,是骡子是马,现在咱就拉出来遛遛。
媲美电影大片的质感
此前的可灵 1.0 模型,在高品质模式下只能生成 720p 的视频,虽在众多视频生成模型中表现出色,但随着用户对 AI 技术的期望不断提升,这个清晰度已无法满足他们的高标准需求。
现在可灵 AI 新推出可灵 1.5 模型,支持高品质模式下,生成 1080p 高清视频。
例如,我们输入 Prompt:一只拟人化的橘猫,戴着黑框眼镜,圆脑袋大肚子,穿着白衬衫,坐在电脑桌前,表情疲惫想睡觉。
1.0 模型:

1.5 模型:
虽然二者均遵循了 Prompt 的要求,但从美感上来说,1.5 模型的橘猫倚在座位上眯着眼打盹,模样更憨态可掬,柔和的台灯光线洒在橘猫脸上,配色也更自然。
再来个科幻风格的。
Prompt:超现实,电影,宇航员驾驶着马车在荒凉的月球上前行,极致细节。
1.0 模型:

1.5 模型:
在可灵 1.0 模型中,两位宇航员乘坐的马车稍显简陋,只有一匹马、俩轮子,外加一块破布胡乱摆动。
而到了 1.5 模型,全副武装的宇航员端坐在车厢中,马蹄上裹着金属材质的护腿,散发着蓝色的幽光,无论是构图还是氛围感,都有科幻电影的感觉。
我们继续输入 Prompt:一只在指尖上行走的微型小斑马。
众所周知,手指扭曲向来是 AI 的通病之一,但在可灵 1.5 模型中,手部细节并未出现明显的 bug,同时还发挥想象力,展示出一位年轻女子注视迷你斑马的镜头,眼神流转甚是逼真
再比如 Prompt:一个小男孩正在街上滑滑板。
可灵 1.5 模型中,小男孩从站立滑行到缓慢俯身抓住滑板,整套动作行云流水,也比较符合物理世界的运动规律。
同时,男孩面部表情自然,丝毫没有崩坏,头发丝也清晰可见,对光影的处理更是到位,整个画面极具电影美感。
还有国外网友用可灵 1.5 模型生成了一段女孩站在废墟中的场景。
战争过后一片狼藉,小女孩无助地站在废墟之上,眉头紧锁,眼中流露出无尽的悲伤和恐惧,其真实性和细节处理得堪比实地拍摄。
动幅再大也不崩
目前,市面上大部分 AI 生成模型都有个毛病,要么是运动幅度小、流畅性不足,要么就是动幅太大,冒出诡异画面。
例如,骑摩托骑到天上去的大妈们:
此次可灵 1.5 模型把动态质量提升到一个新 level,可以让视频中的角色运动幅度更大、动作更合理,还能保持一致性。
Prompt:一个短发亚洲女孩儿,穿着米色宽松毛衣,浅棕色裤子,骑着一辆罗马假日的小摩托,摩托是蒂芙尼蓝的颜色,在罗马的街头,阳光明媚,完美构图,精美画面,细节刻画,电影镜头。
1.0 模型:
1.5 模型:
1.5 模型中女孩手握车把调整方向,头发也随之飘动,整体的运动幅度更大,电动车的运行轨迹也更合理。
Prompt:一只毛茸茸的黄色小猫正在玩一只小小的红色毛线团。
1.0 模型:

1.5 模型:
在这轮测试中,两个模型的表现各有千秋。
1.0 模型强调的是小猫咪撩拨拴在脖子上的红毛线,构图、配色颇具美感;1.5 模型则突出小猫抬起爪子玩线团,无论是小猫的动作还是毛线团的转动,其运动幅度都更大。
我们再来试一下图生视频功能。上传一张马斯克的图片,输入提示词:马斯克正在吃汉堡。

1.0 模型:

1.5 模型:
背靠有着众多吃播视频的快手,可灵 AI 在吃饭视频生成上可以说是无人能敌。在这一轮的 PK 中,两大模型的生成效果不相上下。
「硅谷钢铁侠」马斯克秒变吃货,他先是拿起汉堡看了一眼,然后张大嘴巴咬一口,咀嚼时下巴一上一下,两颊有节奏地颤动着,汉堡上也留下清晰的咬痕。
最让人惊喜的,还是猪八戒拿起筷子吃面条这段:

二师兄端着碗,提起筷,挑起一坨面条就歪着脑袋呼呼地往嘴里送。不得不说,猪八戒握筷子的姿势,简直比人类还有范,那面条的垂坠感表现得也相当细腻。
再复杂的镜头语言也能 get 到
除了画质更高、运动幅度更大外,可灵 1.5 模型还可以响应更复杂的文本描述要求,甚至还能「无中生有」。
例如,我们上传一张没有人物的牛肉面的图片,然后再配上 Prompt:镜头拉远,一个小女孩拿着筷子开始吃饭。

可灵 1.5 模型生成的视频中,随着镜头缓慢拉远,一双筷子入画,继而出现一个手握筷子、嗦着面条的小女孩。
而在 1.0 模型中,对于提示词的理解就稍微欠缺一些,画面中没有出现人物,只是出现了一双筷子慢慢夹起了碗中的牛肉。

我们还输入了一段如同小作文般的文本描述,既包括诸多场景细节,又有镜头景深的要求。
Prompt:一只花斑狗在浓密的花园中欢快地穿梭,仿佛在追逐着什么,它向前小跑着,眼睛睁得大大的,充满喜悦之情,在行走的过程中,它仔细地扫视着树枝、花朵和树叶,小径十分狭窄,花斑狗不得不在植物之间穿梭而行,画面是从地面角度拍摄的,紧跟花斑狗的步伐,提供了一个低矮而亲密的视角,画面色调温暖,颗粒感明显,给人一种电影般的视觉效果,树叶和植物上方洒落的阳光营造出温暖的对比效果,突出了花斑狗的毛发。画面清晰锐利,景深较浅。
可灵 1.5 模型生成效果如下:
它不仅准确理解了输入的指令,还生成与之匹配的视频内容,画面整体构图和光影表现也让视频颇具艺术感和观赏性。
再来一个镜头语言更复杂的 Prompt:灯塔周围的超快速无人机视角,悬崖,戏剧性,pov 镜头,电影。
1.0 模型:

1.5 模型:

「pov 镜头」、「超快速无人机视角」等镜头描述,无疑加大了 AI 理解难度,但两个模型均给出了超预期的画面。
1.5 模型生成的画面更稳,镜头由远及近慢慢推进,矗立在悬崖上的灯塔还射出一道白色的亮光。
而 1.0 模型的镜头转换则更加刺激,先是一顿旋转式俯拍,接着近距离环绕拍摄,完全契合了超快速无人机拍摄的文本描述。
一勾一画,指哪动哪
图生视频时,为了大幅提升创作者对运动效果的控制能力,可灵 AI 还带来了「运动笔刷」功能。
不过,该功能只能在可灵 1.0 模型中使用。
玩法也很简单。
比如,我们上传一张水母的图片,然后将图片中需要控制运动方向的部分勾勒出来,再画一个示意运动方向箭头,就可实现精准运动控制。
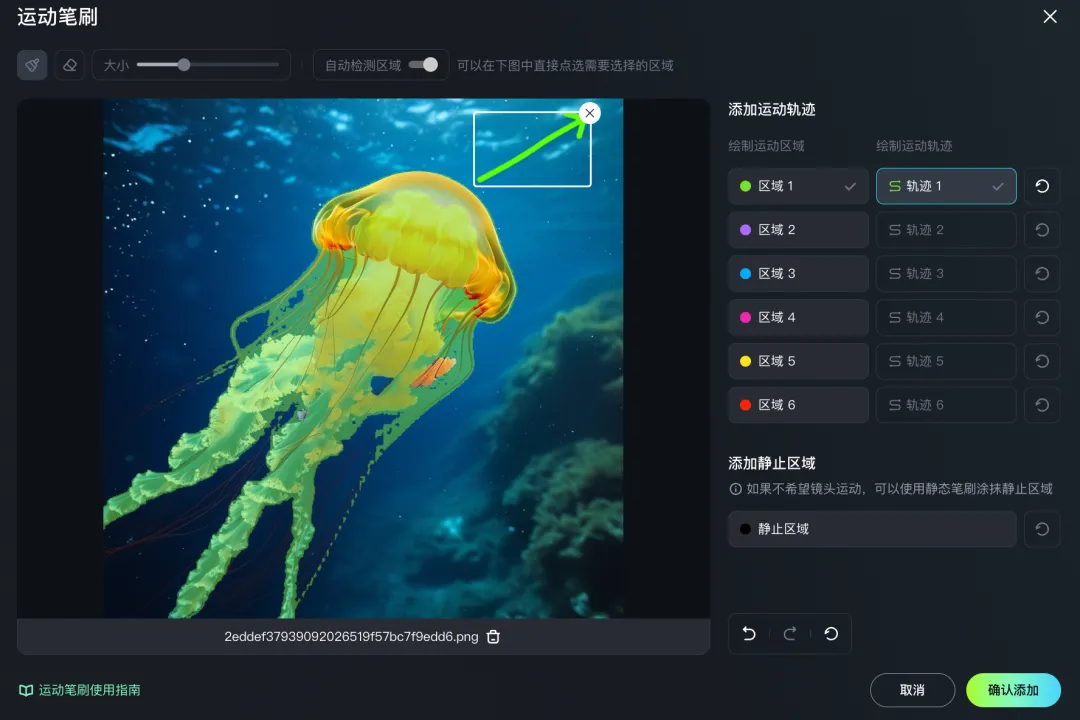
当然,我们也可以开启「自动检测区域」的按钮,让 AI 自动识别,还可以为某些元素额外指定静止区域,让视频内容有更好的运动控制及运动表现。
上效果:

值得注意的是,目前该功能可以为图中的 6 个元素指定运动轨迹。
比如让三只水母在海里朝着不同方向游动:
或者把一幅梵高风格的油画,各种涂抹标轨迹。
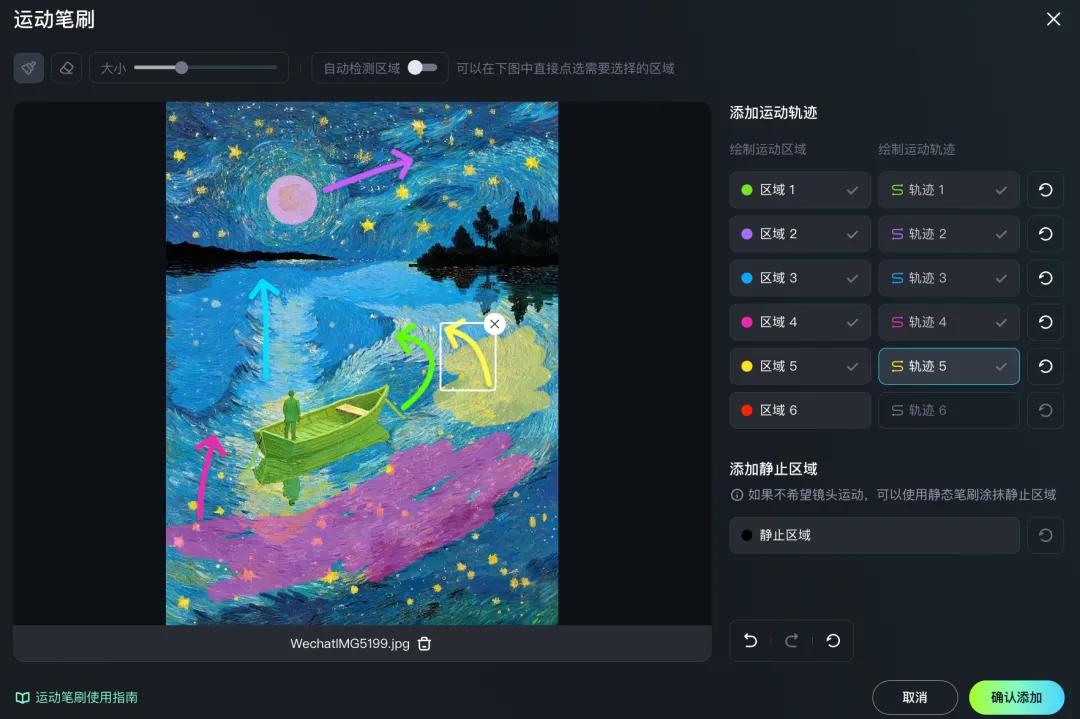
最终生成的视频竟有了一种 3D 效果:
此外,可灵 AI 还顺道升级了其他功能,比如可一次性生成最多 4 条视频;「图生视频」功能新增支持 10 秒时长、标准模式下支持增加尾帧;「AI 图片」支持画质增强等。
可灵 AI 的这些新功能一经推出,便吸引了全球网友前往「尝鲜」。不少网友体验后表示,这是迄今为止最好的视频生成模型,足以媲美专业电影制作的标准。
自今年 6 月份首次亮相以来,可灵 AI 已经进行了 9 次迭代升级,至今已服务超过 260 万用户,生成 5300 万张图片和 2700 万个视频,深受包括国内知名导演在内的创作者们的青睐。
为了进一步探索 AI 在电影制作中的潜力,快手还特别启动了「可灵 AI」导演共创计划。该计划汇聚了李少红、贾樟柯、叶锦添等 9 位杰出导演,他们将利用可灵 AI 的技术,创作 9 部 AIGC 电影短片,这不仅是技术与艺术的结合,也是对未来电影制作模式的一次大胆尝试。
由此可见,AI 对电影行业的重塑已不再是一个遥远的预言,而是正在发生的现实。AI「新影像」时代正呼啸而来。














暂无评论内容