
近日,阿里通义千问团队发布了Qwen2.5系列模型之后,在开源社区备受开发者推崇。很快,硅基流动SiliconCloud率先上线了语言模型Qwen2.5-7B/14B/32B/72B。
今天,SiliconCloud继续上线推理加速版的代码专项模型Qwen2.5-Coder-7B-Instruct以及数学专项模型Qwen2.5-Math-72B-Instruct。
相比前身CodeQwen1.5和Qwen2-Math,Qwen2.5-Coder-7B-Instruct在包含5.5T Token编程相关数据上进行了训练,在代码生成、代码推理、代码修复等任务上都有了显著提升,Qwen2.5-Math-72B-Instruct支持中文和英文,并整合了CoT等多种推理方法。
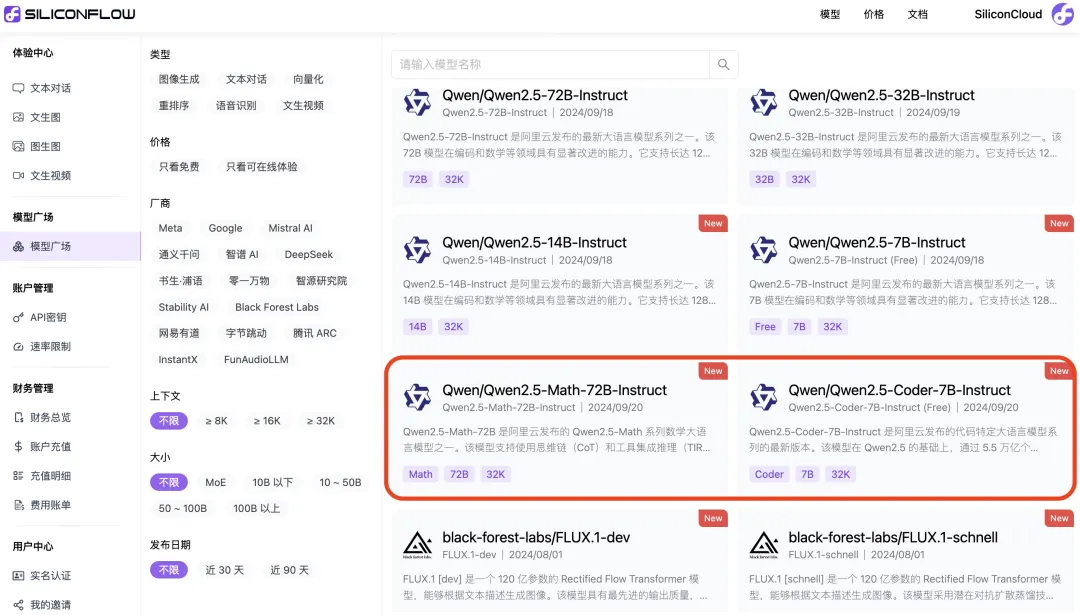
分别感受一下Qwen2.5-Coder-7B-Instruct、Qwen2.5-Math-72B-Instruct在SiliconCloud上推理加速后的效果。
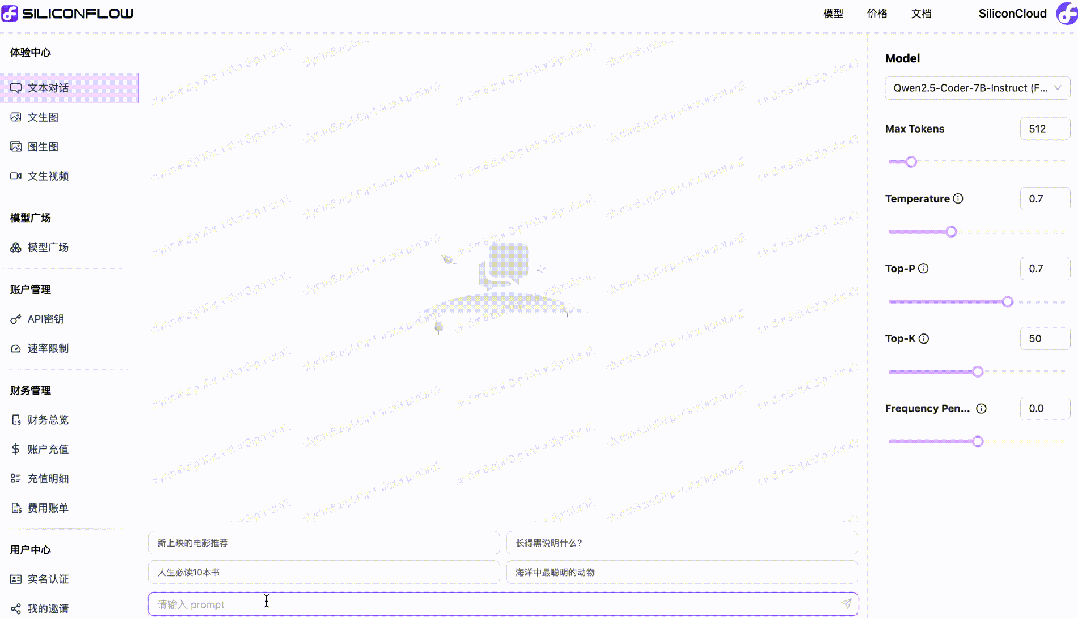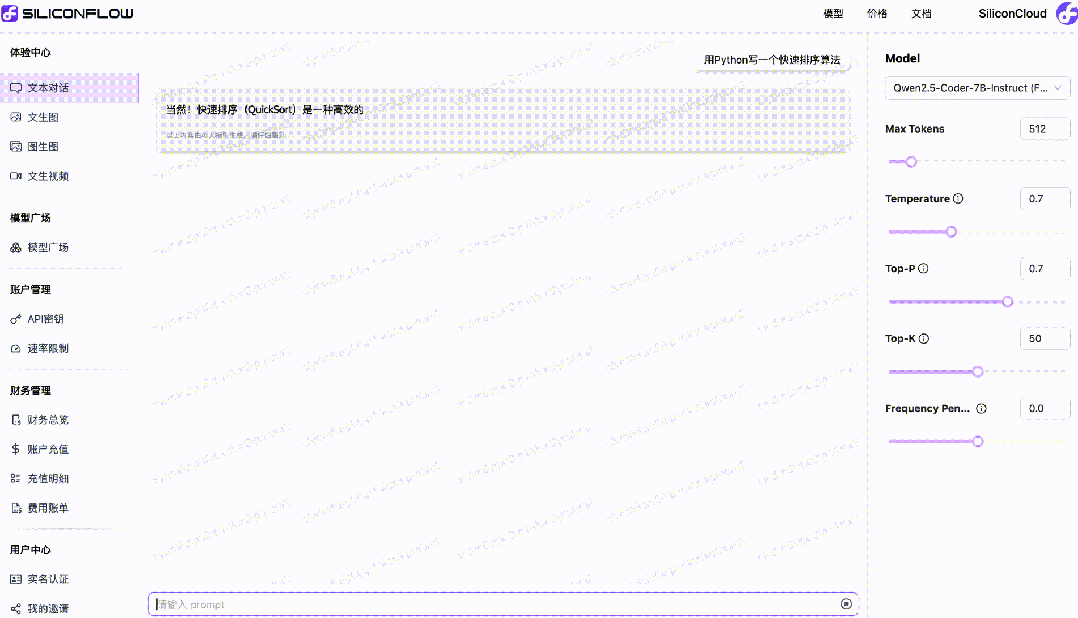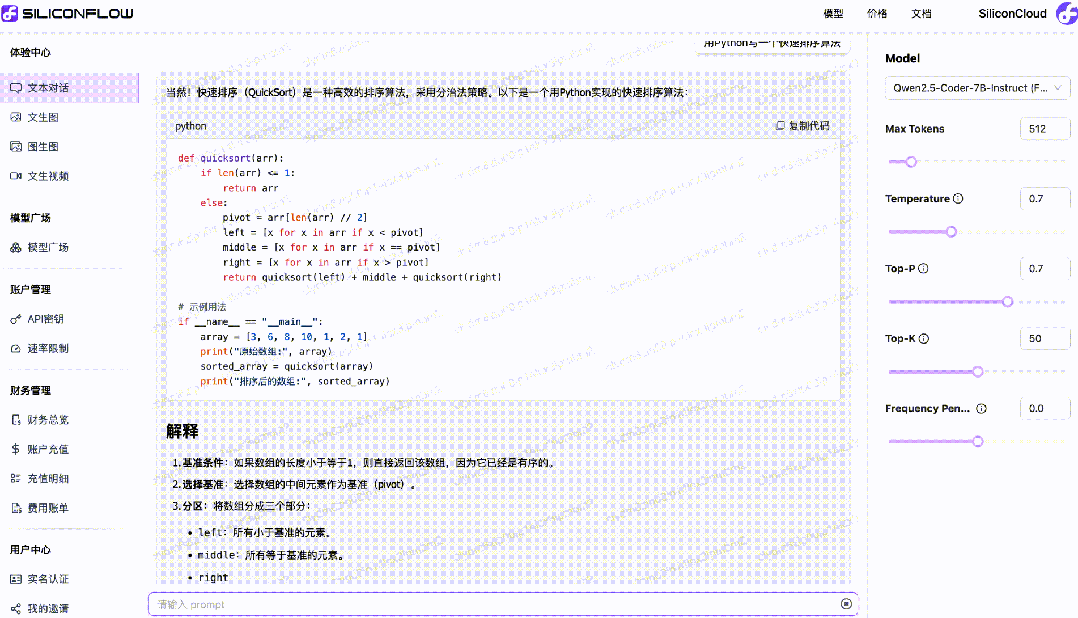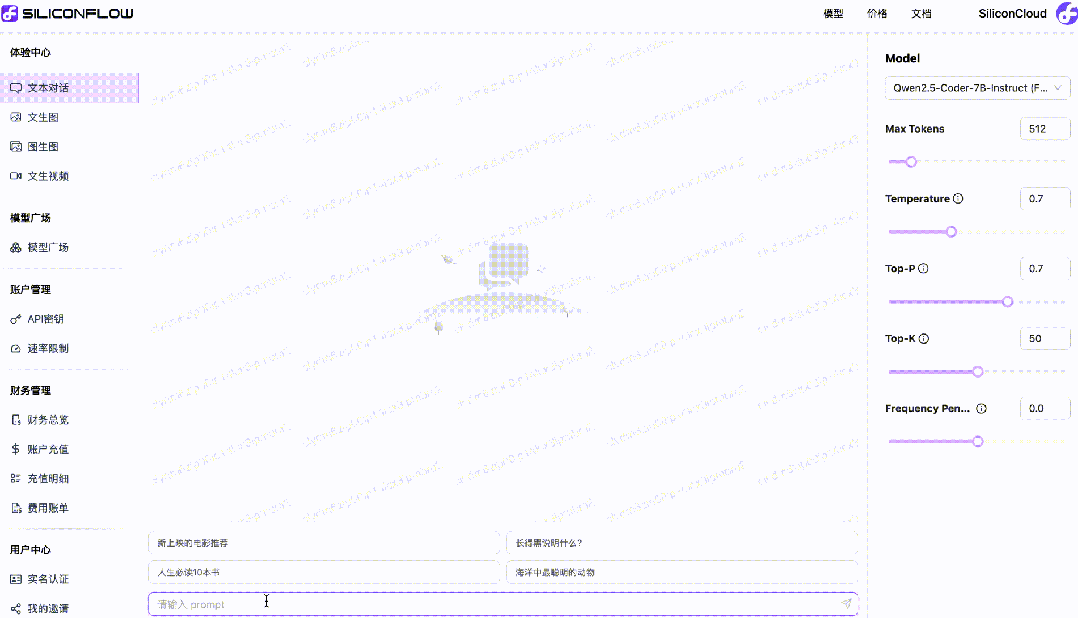

与其他各类开源大模型一样,开发者在本地运行Qwen2.5-Coder-7B-Instruct、Qwen2.5-Math-72B-Instruct模型有较高部署门槛与成本。现在,SiliconCloud上线这两大模型后,免去了开发者的部署门槛,并可轻松调用相应的API服务到实际应用中。
更重要的是,SiliconCloud平台上的Qwen2.5-7B、Qwen2.5-72B输出速度极快,能为你的生成式AI应用带来更高效的用户体验。
目前,Qwen2.5-Coder-7B-Instruct可免费使用,而Qwen2.5-Math-72B-Instruct与此前上线的Qwen2-Math-72B-Instruct保持一致,仅需¥4.13/1M token。
此外,平台还支持开发者自由对比体验各类大模型,最终为自己的生成式AI应用选择最佳实践。
模型评测表现及亮点
代码模型Qwen2.5-Coder-7B-Instruct
在多种编程语言和任务中,Qwen2.5-Coder-7B-Instruct的表现超过了众多大型语言模型,包括那些参数量大得多的模型,展现了其卓越的编程能力。
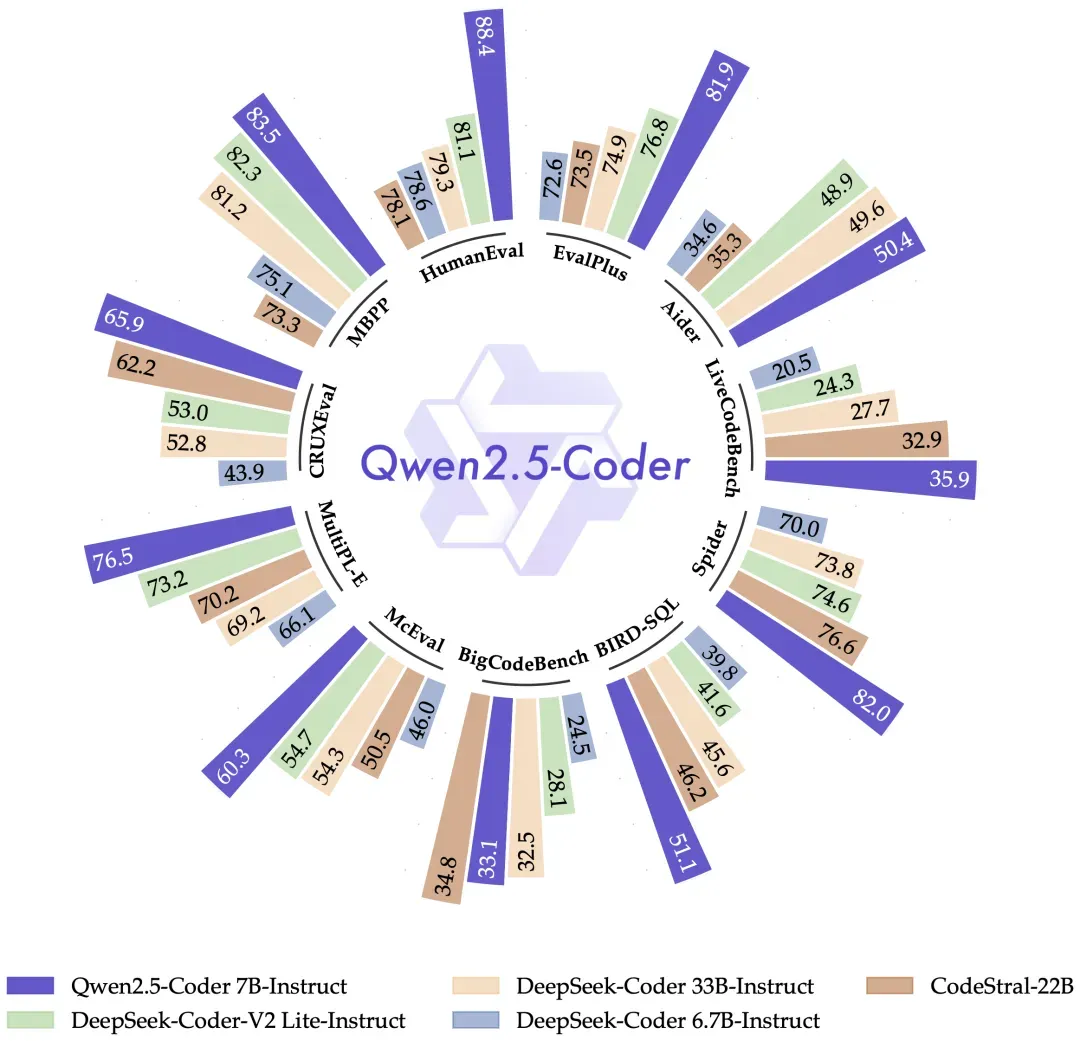
尤其是,Qwen2.5-Coder-7B-Instruct在以下四个方面表现非常突出:
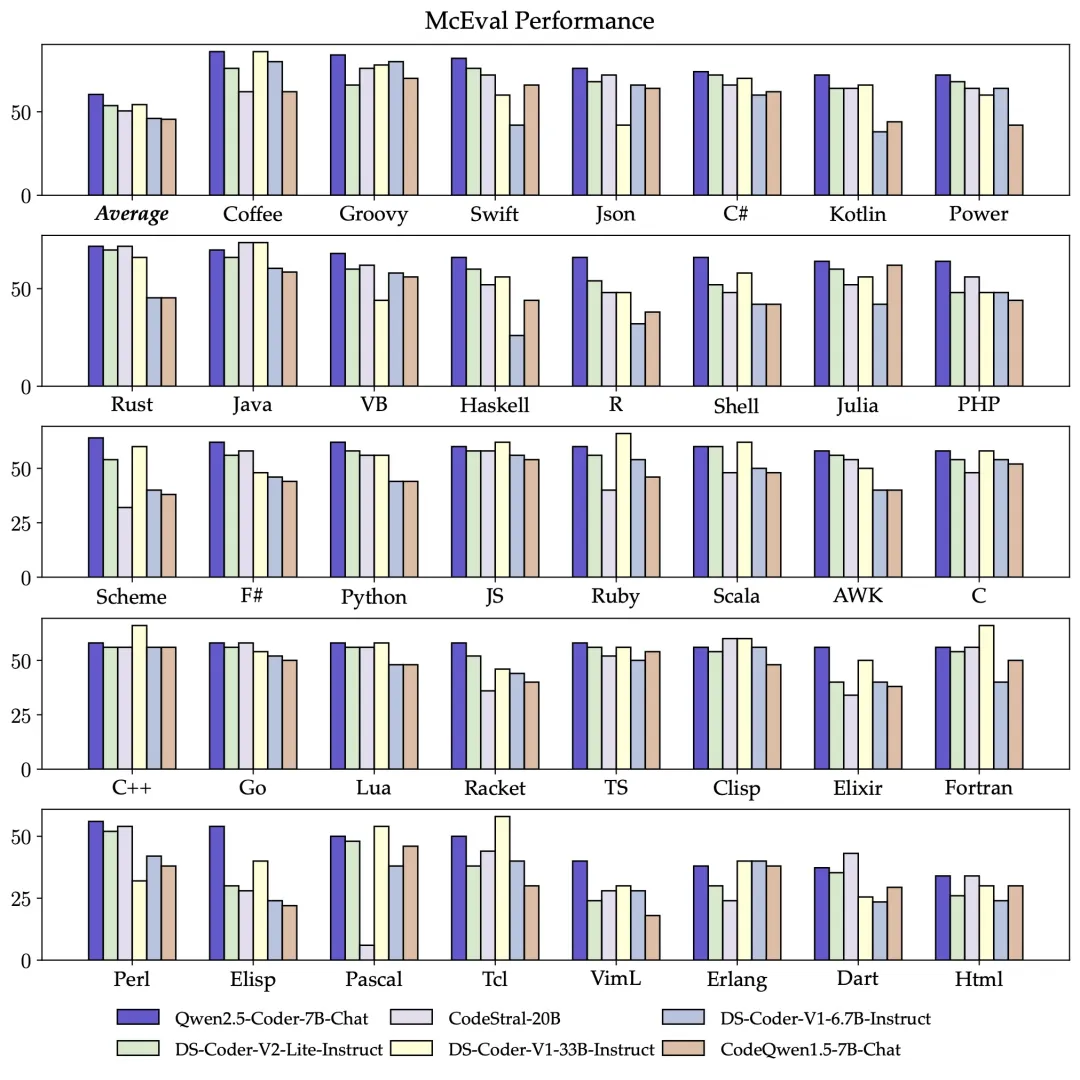
卓越的多编程语言能力:为了更广泛评估多编程语言能力,Qwen团队使用McEval在Qwen2.5-Coder-7B-Instruct上进行了更多的测试,共设计40多种编程语言。结果表明Qwen2.5-Coder-7B-Instruct在多种编程语言任务上表现非常出色,包括一些小众语言。
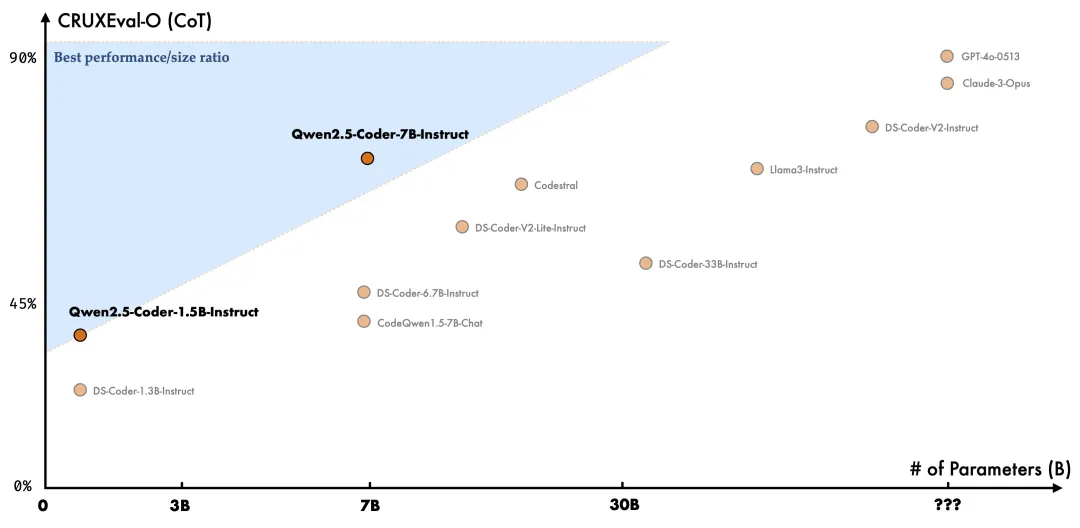
代码推理:Qwen团队认为,代码推理能力和通用推理能力密切相关,他们选择CRUXEval作为评估基准,结果表明,Qwen2.5-Coder-7B-Instruct在代码推理任务上表现非常出色。更有趣的是,随着代码推理能力的提升,模型的复杂指令遵循也得到了增强。
数学能力:数学和代码经常被一起讨论,数学是代码的基础学科,代码是数学的重要工具。Qwen团队发现,Qwen2.5-Coder-7B-Instruct在代码和数学任务上都表现出色,是一个名副其实的理科生。
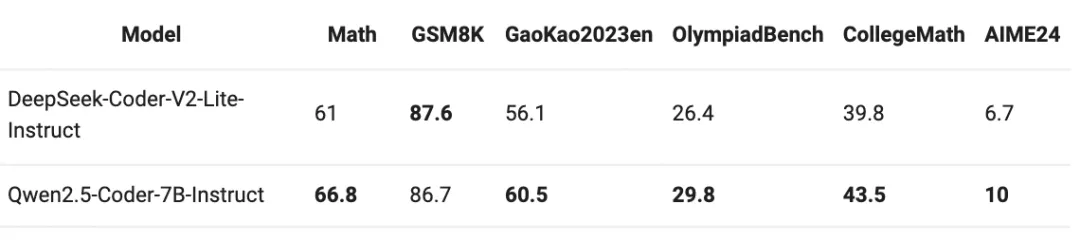
基础能力:Qwen2.5-Coder-7B-Instruct在通用能力上也保持了Qwen2.5的优势。
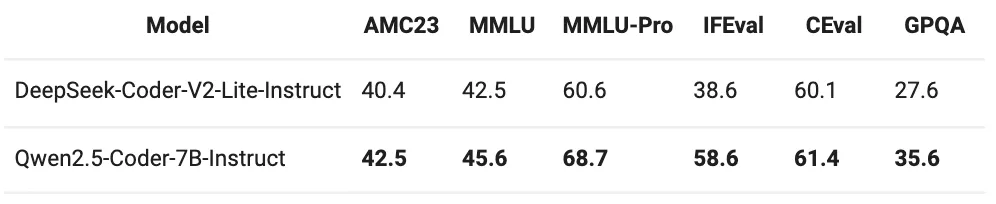
数学模型Qwen2.5-Math-72B-Instruct
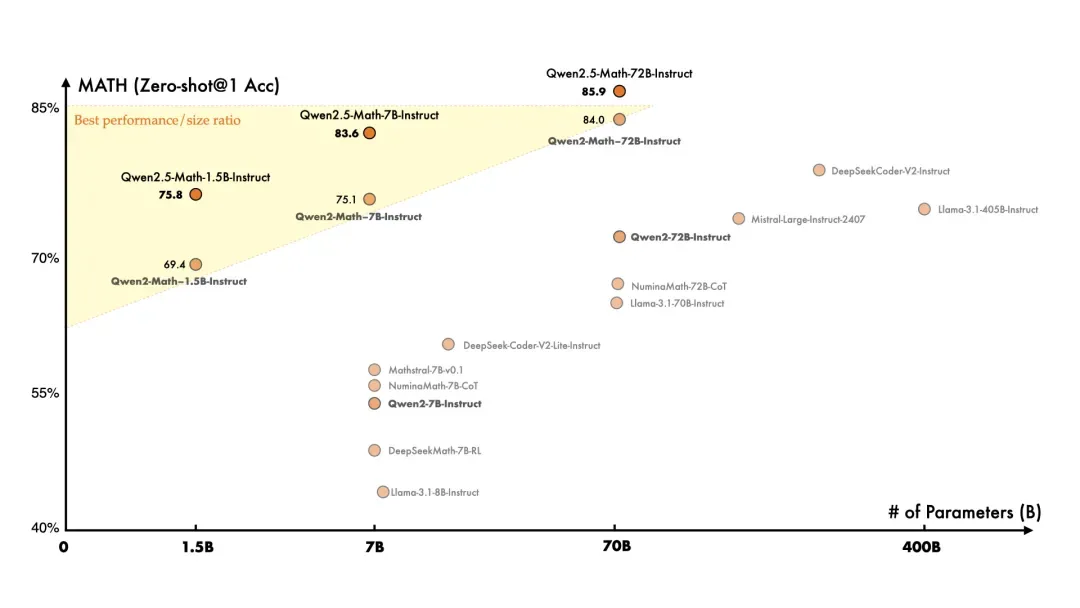
在数学专项模型方面,SiliconCloud此前上线了通义千问的首批模型Qwen2-Math-72B-Instruct,而这一次,Qwen2.5-Math-72B-Instruct在更大规模的数学相关数据上进行了预训练,包括由Qwen2-Math生成的合成数据。
此外,Qwen2.5-Math-72B-Instruct增加了对中文的支持,并通过赋予其进行CoT(Chain of Thought)、PoT(Program of Thought)和TIR(Tool-Integrated Reasoning)的能力来加强其推理能力。Qwen2.5-Math-72B-Instruct在中文和英文的数学解题能力上均实现了显著提升,整体性能超越了Qwen2-Math-72B-Instruct和GPT4-o。
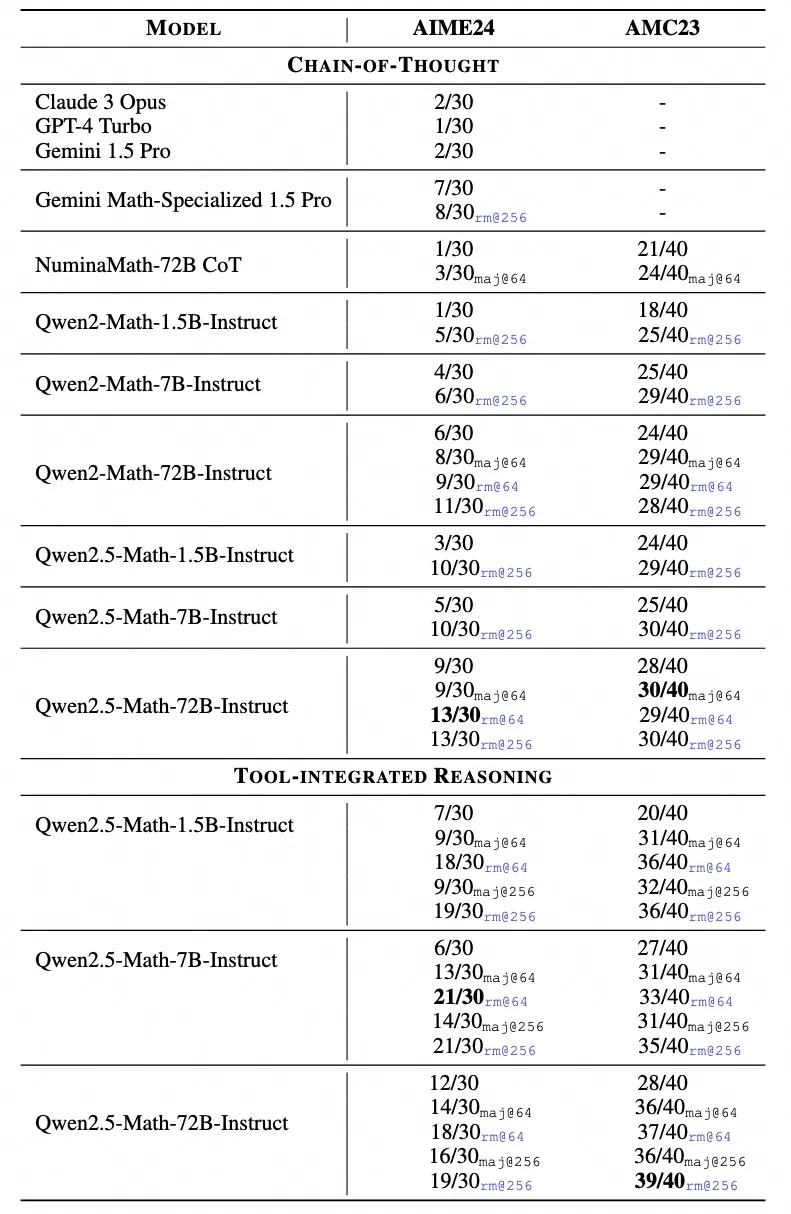
Qwen团队在英文和中文的数学基准上评估Qwen2.5-Math-Instruct-72B。除了广泛使用的基准测试(例如GSM8K和Math)之外,他们还涉及更多更具挑战性的考试,以全面评估Qwen2.5-Math-Instruct-72B的数学能力 ,例如 OlympiadBench、CollegeMath、GaoKao、AIME2024和AMC2023。对于中国数学基准测试,他们使用CMATH、Gaokao(中国大学入学考试 2024)和CN Middle School 24(中国高中入学考试2024)。
实验结果表明,Qwen2.5-Math-72B-Instruct模型在英文和中文上分别比上一代Qwen2-Math-72B-Instruct模型平均高出4.4分和6.1分,成为目前最好的开源数学模型。
Qwen2.5-Math-72B-Instruct的表现显著优于开源模型和领先的闭源模型(例如 GPT-4o、Gemini Math-Specialized 1.5 Pro)。在RM@8的TIR设置下,在MATH上取得了92.9的高分。

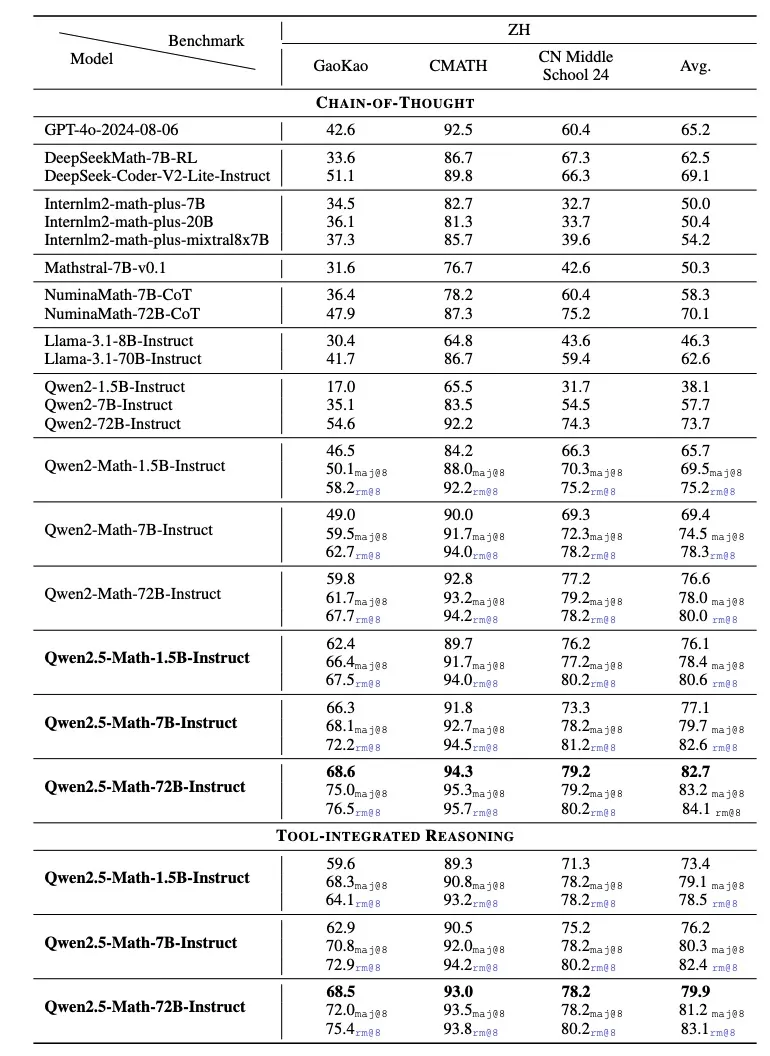
在 AIME 2024 和 AMC 2023 等更复杂的数学竞赛评估中,Qwen2.5-Math-72B-Instruct在各种设置中也表现良好,包括Greedy、Maj@64、RM@64和RM@256。
Qwen2.5-Math-72B-Instruct在TIR模式下几乎获得了满分,解决了几乎所有的问题。在极难的AIME 2024基准测试中,Claude3 Opus、GPT-4 TurboGemini 1.5 Pro 只能解决30道题中的1或2道题。相比之下,Qwen2.5-Math-72B-Instruct在贪婪解码CoT模式下解决了9道题,在TIR模式下解决了12道题。在RM的帮助下,Qwen2.5-Math-7B-Instruct甚至可以解决多达21道题,进一步展现了Qwen2.5-Math-Instruct出色的数学解题能力。
Token工厂SiliconCloud
Qwen2.5(7B)、Llama3.1(8B)等免费用
作为集合顶尖大模型的一站式云服务平台,SiliconCloud致力于为开发者提供更快、更便宜、更全面、体验更丝滑的模型API。
除了Qwen2.5-Coder-7B-Instruct、Qwen2.5-Math-72B-Instruct,SiliconCloud已上架包括Qwen2.5-7B/14B/32B/72B、Flux.1、DeepSeek-V2.5、InternLM2.5-20B-Chat、BCE、BGE、SenseVoice-Small、Llama-3.1、DeepSeek-Coder-V2、SD3 Medium、GLM-4-9B-Chat、InstantID在内的多种开源大语言模型、图片生成模型、代码生成模型、向量与重排序模型以及多模态大模型。
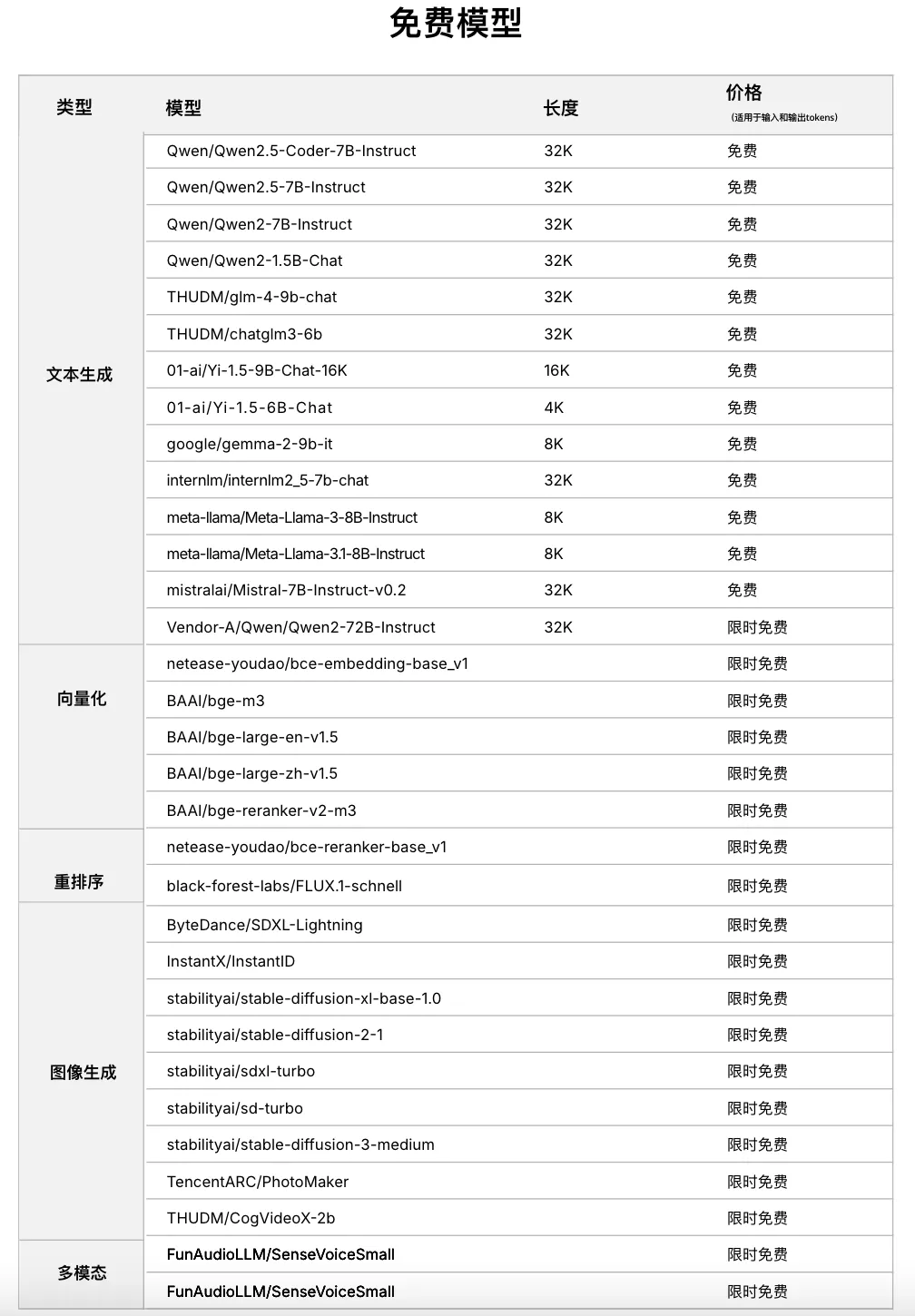
其中,Qwen2.5(7B)、Llama3.1(8B)等多个大模型API免费使用,让开发者与产品经理无需担心研发阶段和大规模推广所带来的算力成本,实现“Token 自由”。














暂无评论内容