阿里巴巴正在向全球开源社区提供其超过100个大型语言模型,这是其推动人工智能领域发展的重要举措之一。
阿里云智能首席技术官周靖人称这一行动是一个“重要的里程碑”,也是公司迄今为止规模最大的一次开源计划。根据阿里巴巴的介绍,这些新的开源模型隶属于阿里云的Qwen 2.5系列大型语言模型组合,涵盖了语言、音频和视觉等多种模态。
这一声明是在阿里云每年一度的三天活动(云栖大会)期间发布的,活动在中国杭州举行,期间阿里巴巴邀请了知名的AI初创公司创始人和科学家参加,其中包括美籍华裔计算机科学家、前推特董事会成员李飞飞。
阿里巴巴表示,自2023年4月Qwen模型发布以来,这些模型在开源平台如Hugging Face和ModelScope上的下载量已超过4000万次。
一、Qwen2.5系列大模型
Qwen2.5系列72B模型相比于Qwen2,在多个方面实现了显著的进步。首先,新模型在知识储备上有了明显的增加,其编程能力和数学推理能力也得到了显著的增强。除此之外,Qwen2.5在指令处理、生成长文本、理解和处理格式化数据(如表格)以及生成格式化输出(尤其是JSON格式)的表现上,也有了明显的提升和修改。
我们在阿里云官网上,搜索“通义千问-开源”,搜索出来28个结果,排在前列的就是在云栖大会上宣布的Qwen2.5系列。

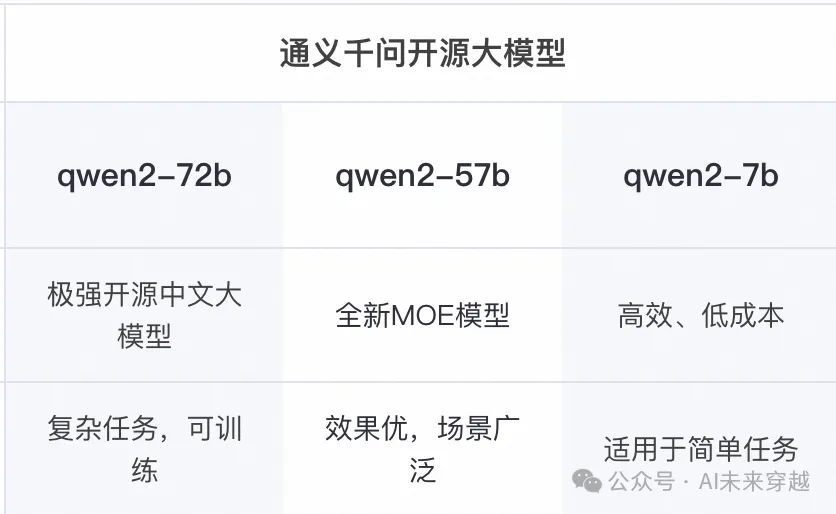
各个版本之间的区别,我们参考一下上个开源版本2.0之间的区别。
二、文生图片大模型
近日,由Stable Diffusion原班人马打造的开源文生图模型FLUX爆火起来,因为其逼近Midjourney的出色文生图片的质量,成为文生图领域的“开源王者”。阿里云百炼平台,在国内上线了首个FLUX中文优化版,目标是更好地理解和执行中文指令。开发者目前已经可以轻松在阿里云百炼上直接体验FLUX效果,并限时免费调用该模型。
FLUX.1采用了Stable Diffusion 3类似架构,但新引入了DoubleStreamBlock结构,达到了超越Stable Diffusion 3 甚至挑战Midjourney V6的生成质量。在对指令的精准遵循、文字生成能力、手部细节生成等方面,FLUX.1表现尤为突出,展现出在文生图领域的革新潜力。
下面是根据提示词“一个时间旅行者的图书馆,书籍打开时展现出不同历史事件的全息场景”生成的图片,看效果是非常ok的。

三、语音模型
通义千问Audio是阿里云研发的大规模音频语言模型,能够接受多种音频(包括说话人语音、自然声音、音乐、歌声)和文本作为输入,并输出文本。通义千问Audio不仅能对输入的音频进行转录,还具备更深层次的语义理解、情感分析、音频事件检测、语音聊天等能力。
建议优先使用开源版模型qwen2-audio-instruct,它是目前最新的模型,能力最强。同时,qwen2-audio-instruct还支持使用音频本身进行对话,适用于语音聊天场景。

四、文生视频Qwen2-VL
在多模态模型领域,语言视觉模型Qwen2-VL-72B已正式开源。Qwen2-VL具备识别不同分辨率和长宽比图片的能力,能够理解超过20分钟的长视频,并具备自主操作手机和机器人等设备的评估智能体功能。近期,权威视觉平台LMSYS Chatbot Arena Leaderboard发布了最新的模型性能评估结果,Qwen2-VL-72B被评为全球得分最高的大模型。
而通义万相AI生成视频功能也正式上线!阿里云栖大会上,CTO周靖人宣布,官网和App上都可以立刻试用了。
比起国外爆火的Sora、Gen-3 Alpha,通义万相是更能听懂中国话,更懂中国风的AI视频模型。它能够支持最长5秒视频生成,每秒30帧,分辨率为720P。更惊艳的是,它还能生成与画面匹配的音效。
这背后得到了阿里全自研的视觉大模型加持,并采用了业界领先的核心架构——Diffusion+Transformer。
目前开始接受开发者的试用申请。
五、通义千问-Math
Qwen-Math是基于Qwen 模型构建的专门用于数学解题的语言模型。我们在阿里云官网上搜索“通义千问-Math”,能够匹配到10个结果。

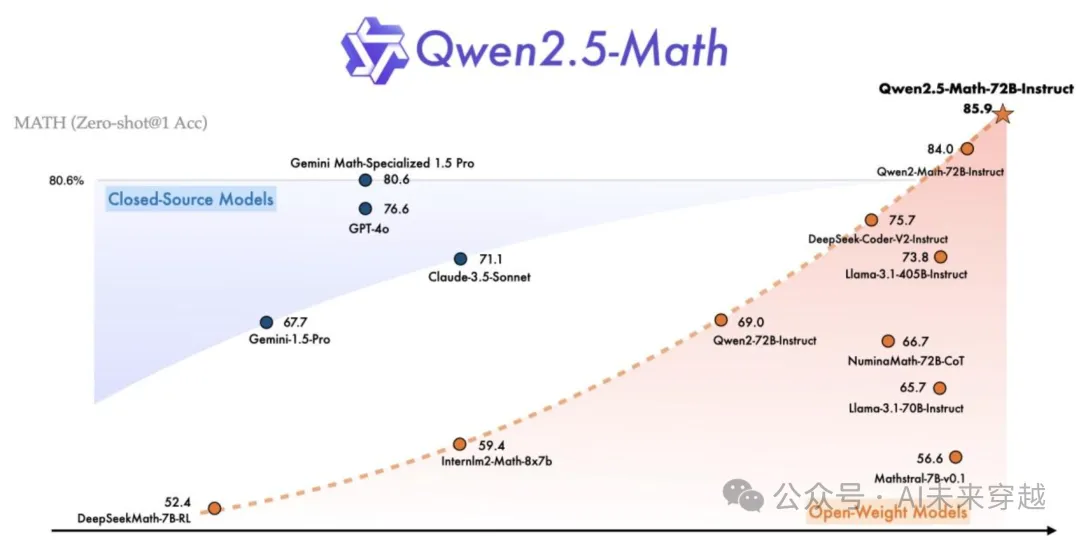
其中,最大尺寸模型Qwen2.5-Math-72B数学能力超过GPT-4o-2024-08-06。
不同math版本的区别如下,从token限制以及价格上看,区别并不是很大。
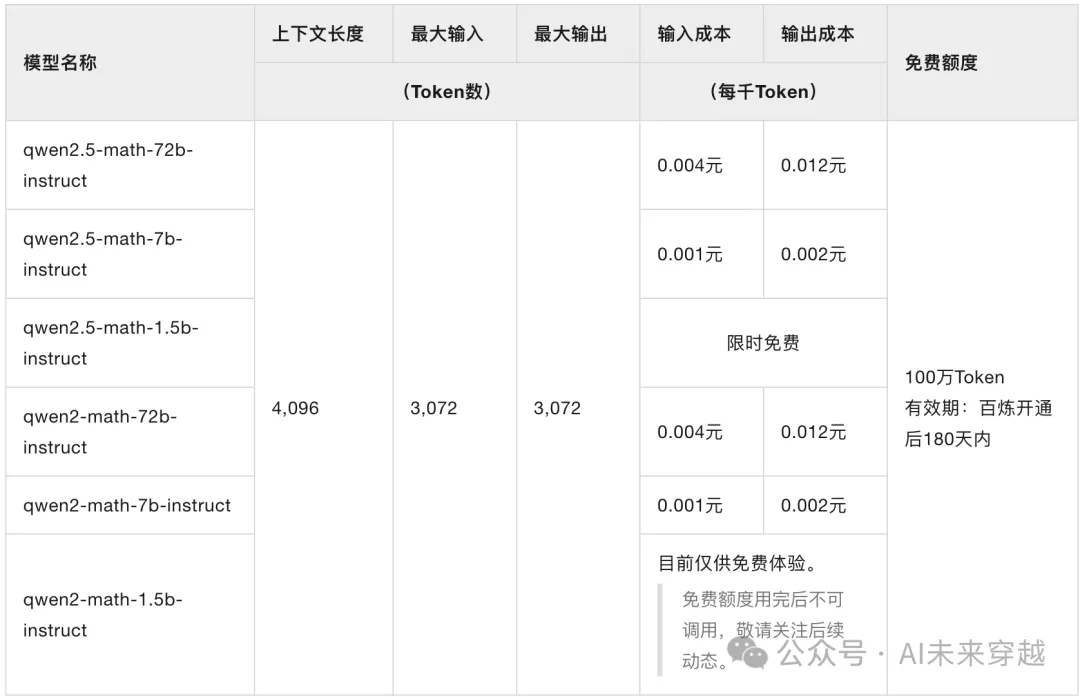
六、Qwen-Coder
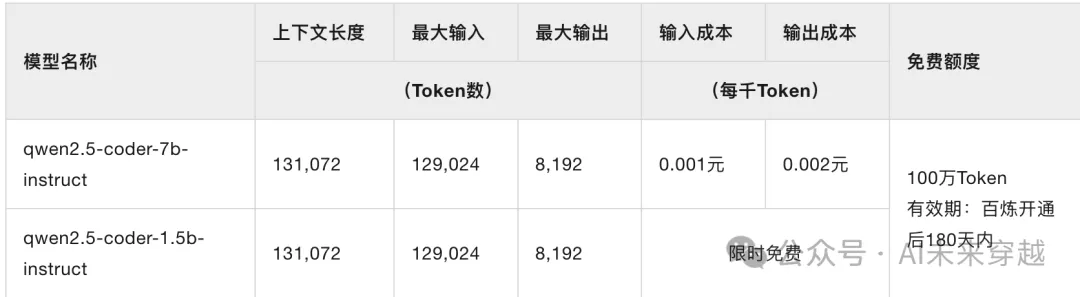
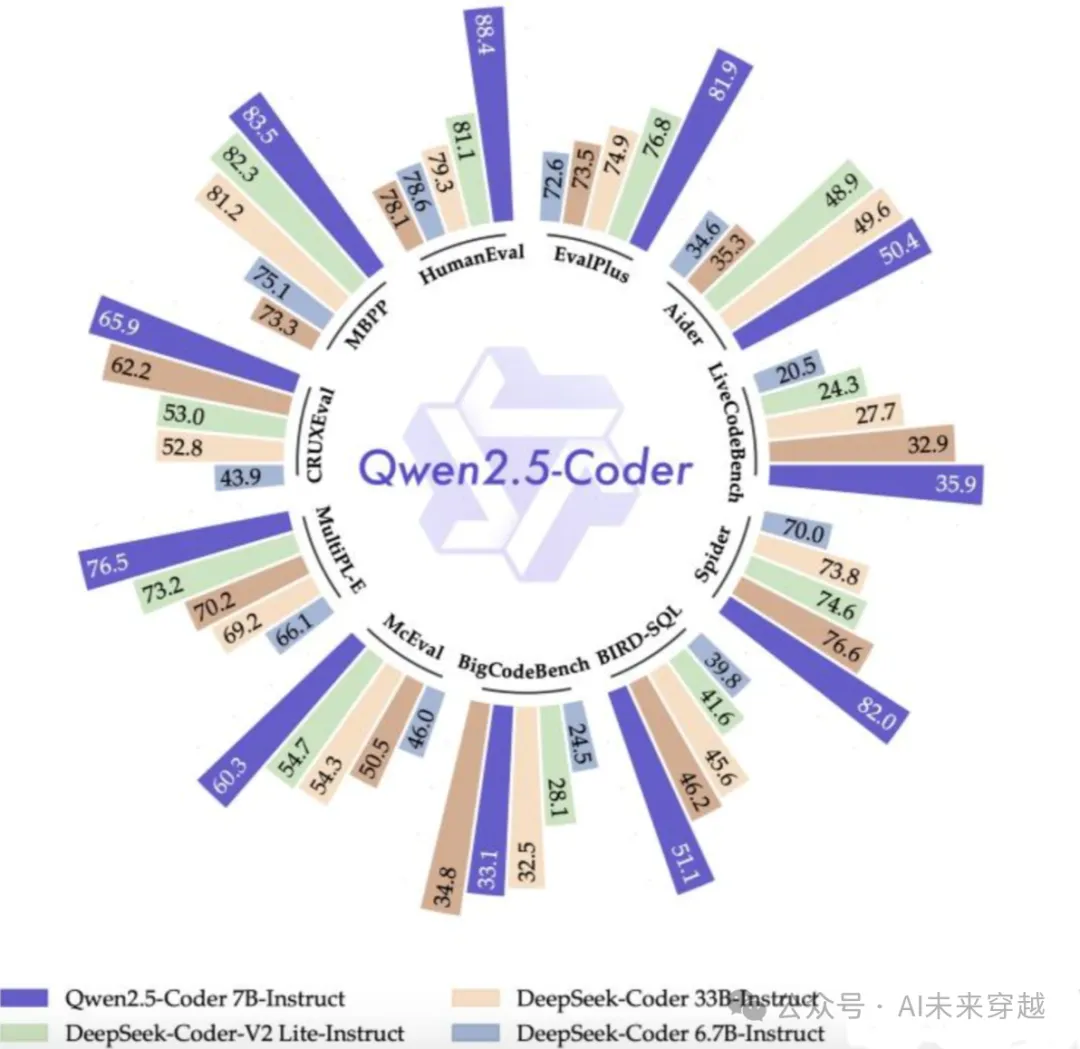
是基于通义千问的代码模型开源版。Qwen2.5-Coder-7B超过DeepSeek-Coder-V2和Codestral等代码模型。
总结
Qwen-2.5系列大模型的开源,极大地推动、丰富了国内大模型的研究和应用生态。对整个行业的意义巨大!
开源意味着全世界的任何人(包括研究人员、学者和公司)都可以使用这些模型来创建自己的生成式 AI 应用程序,而无需训练自己的系统,从而节省时间和成本。














暂无评论内容