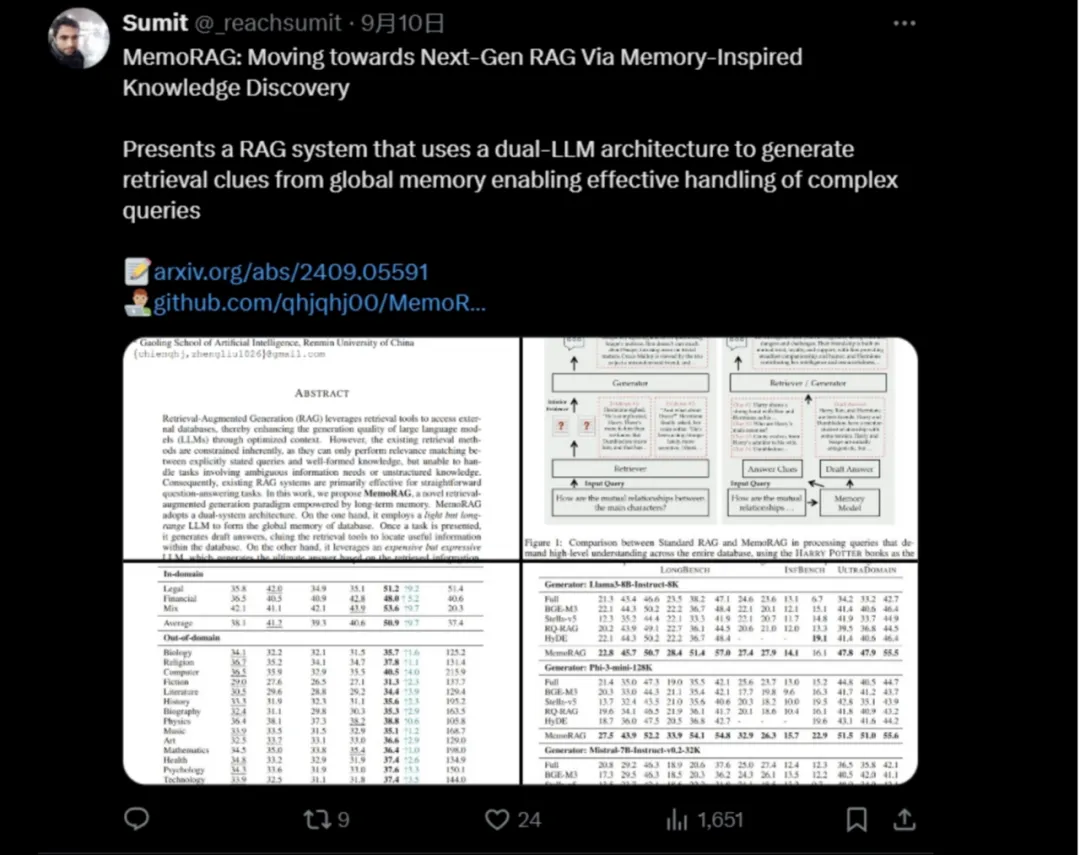
近日,北京智源人工智能研究院与中国人民大学高瓴人工智能学院联合推出基于长期记忆的下一代检索增强大模型框架MemoRAG,旨在推动RAG技术从仅能处理简单QA任务向应对复杂一般性任务拓展。MemoRAG提出“基于记忆的线索生成——基于线索指引的信息获取——基于检索片段的内容生成”这一全新的RAG模式,实现了复杂场景条件下(尤其是“模糊查询表述”、“高度非结构化知识”)的精准信息获取。在这一全新模式下,MemoRAG对于司法、医疗、教育、代码等现实场景中的领域知识密集型任务的处理展示出了极高潜力。
MemoRAG的技术报告已在ArXiv公开,代码也已开源,通过简单的配置即可试用:
技术报告:https://arxiv.org/pdf/2409.05591
Repo:https://github.com/qhjqhj00/MemoRAG

MemoRAG一经发布,便获得了社区的广泛关注以及用户在社交媒体的转发讨论。

滑动查看更多图片
1
什么是RAG?
检索增强生成(Retrieval-Augmented Generation,RAG),因其能够有效解决大语言模型(LLM)面临的多个问题,得到广泛应用。例如,LLM生成虚假信息(Hallucination)或使用过时内容(Out-dated knowledge)。此外,LLM因上下文窗口长度的限制,在处理大量数据时效率较低,而RAG通过引入专门的检索工具,从海量数据库中获取有用知识,使LLM基于更可靠的知识背景生成准确的回答。
绝大多数经典RAG系统中,检索器依赖于用户查询(Query)和候选文本(Candidate Passages)之间的语义匹配来决定返回的内容。这要求用户查询必须包含明确的查询意图,否则检索器难以在查询与目标文本之间建立有效的语义联系。因此,当前RAG系统主要应用于查询意图明确、具体的问答任务。
然而,在实际场景中,用户的查询需求往往更复杂且隐晦,基于“语义匹配”的检索器难以准确找到回答问题所需的文本片段。
例如,用户想围绕小说《天龙八部》提问,对于查询“逍遥派的人物关系怎么样?”,经典RAG系统很难给出准确的答案。原因在于“人物关系”这一概念通常不会在小说原文中显式呈现,而是需要对全篇内容进行全局理解,才能推导出正确的结论。经典RAG系统返回的文本片段往往只包含“逍遥派”相关的部分信息,基于这些片段得到的答案通常是局部推断的,无法反映小说中人物关系的整体发展脉络。
2
什么是MemoRAG?
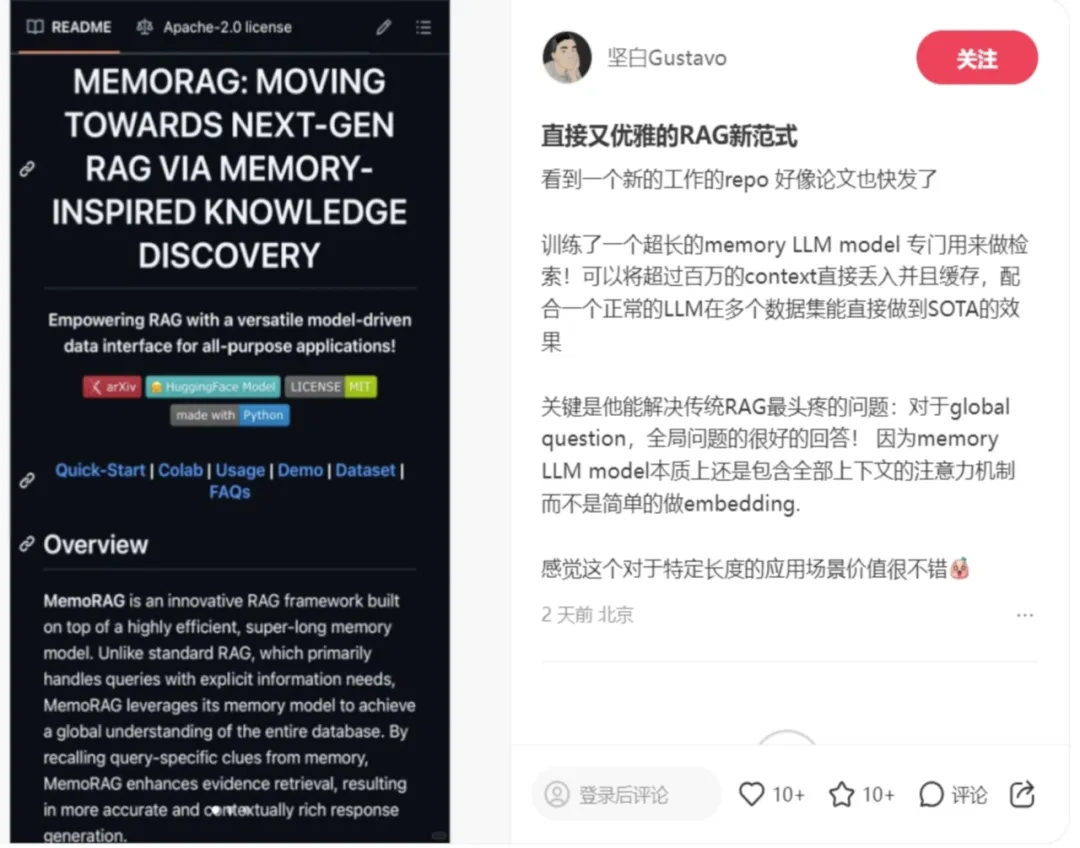
为了让RAG系统适应多样化的任务需求并提升其对外部数据的全局信息理解能力,我们在经典RAG系统之上构建了全局信息记忆功能。具体来说,MemoRAG采用了一种Dual-System架构。首先,MemoRAG 使用一个轻量且高效处理超长文本的LLM作为全局记忆模块,同时采用一个表达能力更强的LLM来生成最终答案。与经典RAG系统相比,MemoRAG 会对数据库进行全局记忆。在接收用户查询后,MemoRAG先基于记忆生成模糊答案和答案线索,然后通过检索器补充答案细节,最终生成完整答案。
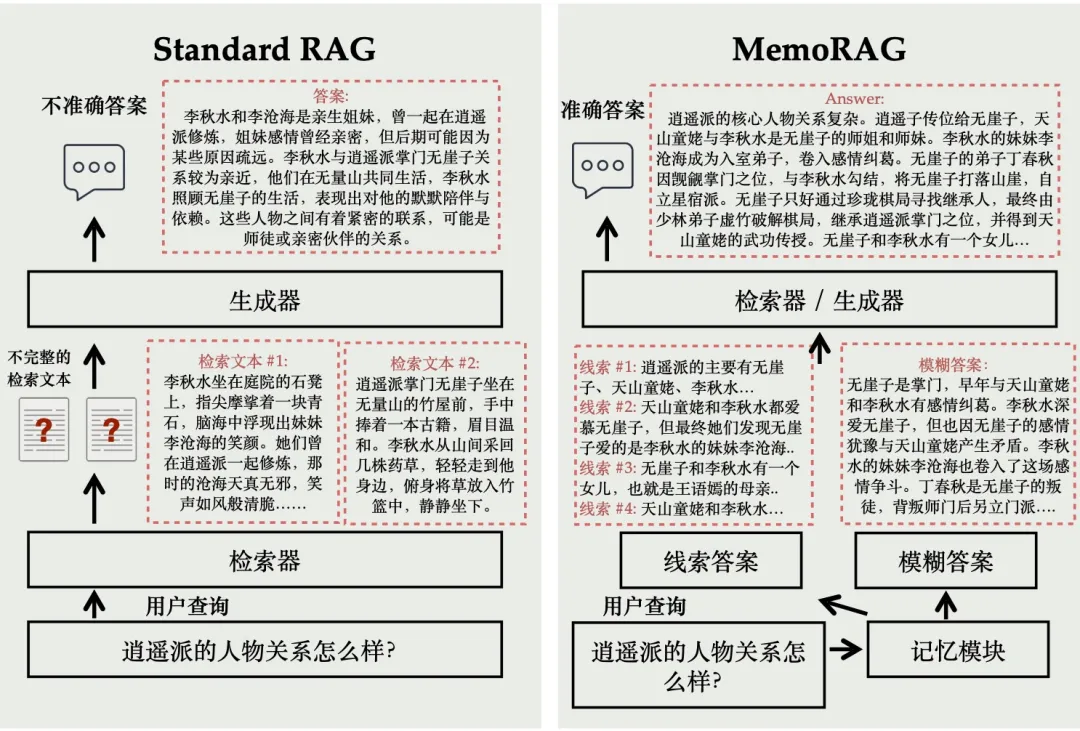
以上图为例,对于《天龙八部》小说中的人物关系问题,MemoRAG 会先对小说全文形成全局记忆。当接收到查询“逍遥派的人物关系怎么样?”时,MemoRAG 的记忆模块能够回忆出一个模糊答案,尽管缺乏细节,但能大致回应问题。同时,MemoRAG 回忆出多个相关答案线索,并借助这些线索补充答案细节,最后基于准确的原文生成完整的回答。MemoRAG 的技术细节可参考技术报告。
MemoRAG 的设计灵感来自于人类的记忆机制。人读完《天龙八部》这部小说时,尽管能大致记住全书情节和人物关系,但难以准确记忆所有细节。面对“逍遥派的人物关系怎么样?”这样的提问,可能只能提供模糊的答案,但可以快速通过翻阅找到细节,从而归纳出完整答案。MemoRAG的“记忆-回忆-检索-生成”正是对人类记忆机制的仿生模拟!
3
MemoRAG技术亮点
· 全局记忆:MemoRAG 具备强大的全局记忆能力,能够在单个上下文中处理多达100万词的数据。这种能力让它能够对海量数据集进行全面的理解,为复杂任务提供强大的支持。
· 可优化且灵活:MemoRAG 拥有极强的适应性,只需经过数小时的额外训练,就能轻松应对新的任务挑战,并在短时间内实现性能的最佳化,帮助用户高效完成各类任务。
· 上下文线索:MemoRAG 可以从全局记忆中生成精准的上下文线索,将原始输入与答案紧密相连。这不仅提升了问题解答的准确性,还能从复杂的数据中挖掘出深层次的洞见。
· 高效缓存:MemoRAG 通过支持分块、索引和编码缓存,显著提升了上下文加载速度,最高可加速30倍。这大幅缩短了处理时间,确保在资源有限的情况下依然可以快速响应。
· 上下文复用:MemoRAG 在处理超长上下文时,采用了一次编码、多次使用的高效策略。只需编码一次,即可在多次任务中重复使用同一数据,大幅提升需要频繁访问相同数据的任务效率,节省时间与计算资源。
4
开源模型
目前,MemoRAG 项目已开源了两种记忆模型,分别是:
基于 Qwen2-7B-inst 的模型:
https://huggingface.co/TommyChien/memorag-qwen2-7b-inst
基于 Mistral-7B-inst 的模型:
https://huggingface.co/TommyChien/memorag-mistral-7b-inst
MemoRAG项目将持续迭代记忆模型,重点优化模型轻量化、长文本编码效率及记忆机制的可用性。
此外,项目中使用的 UltraDomain 数据集已开源:
https://huggingface.co/datasets/TommyChien/UltraDomain
5
MemoRAG使用指南
5.1 环境配置
安装依赖:
pip install torch==2.3.1 conda install -c pytorch -c nvidia faiss-gpu=1.8.0
安装MemoRAG:
pip install memorag
MemoRAG提供Notebook对所有功能进行示范:
https://github.com/qhjqhj00/MemoRAG/blob/main/examples/example.ipynb
5.2 用法
MemoRAG支持直接用 HuggingFace模型初始化。通过该MemoRAG.memorize()方法,记忆模型可以在较长的输入上下文中构建全局记忆。
· TommyChien/memorag-qwen2-7b-inst可以处理最多400K个token的上下文,
· TommyChien/memorag-mistral-7b-inst可以管理最多128K个token的上下文。
· 通过调整参数beacon_ratio,可以扩展模型处理更长上下文的能力。例如,设置beacon_ratio=16,TommyChien/memorag-qwen2-7b-inst可以处理最多一百万个token 。
from memorag import MemoRAG
#Initialize MemoRAG pipelinepipe = MemoRAG( mem_model_name_or_path=”TommyChien/memorag-mistral-7b-inst”, ret_model_name_or_path=”BAAI/bge-m3″, gen_model_name_or_path=”mistralai/Mistral-7B-Instruct-v0.2″, #Optional: if not specify, use memery model as the generator cache_dir=”path_to_model_cache”, #Optional: specify local model cache directory access_token=”hugging_face_access_token”, #Optional: Hugging Face access token beacon_ratio=4 ) context = open(“examples/harry_potter.txt”).read( ) query = “How many times is the Chamber of Secrets opened in the book?”
#Memorize the context and save to cachepipe.memorize(context, save_dir=”cache/harry_potter/”, print_stats=True)
#Generate response using the memorized contextres=pipe(context=context,query=query,task_type=”memorag”, max_new_tokens=256) print(f”MemoRAG generated answer: \n{res}”)
运行上述代码时,编码后的键值 (KV) 缓存、Faiss 索引和分块段落都存储在指定的中目录中。之后,如果再次使用相同的上下文,则可以快速从磁盘加载数据:
pipe.load(“cache/harry_potter/”, print_stats=True)
通常,加载缓存权重非常高效。例如,使用内存模型对200K长文本上下文进行编码、分块和索引大约需要35秒,但从缓存文件加载时只需1.5秒。
5.3 摘要任务
要执行摘要任务,使用以下脚本:
res = pipe(context=context, task_type=”summarize”, max_new_tokens=512) print(f”MemoRAG summary of the full book:\n {res}”)
同时,MemoRAG也支持使用商用API作为生成模型,具体参考以下代码:
from memorag import Agent, MemoRAG
#API configurationapi_dict = { “endpoint”: “”, “api_version”: “2024-02-15-preview”, “api_key”: “” } model = “gpt-35-turbo-16k” source = “azure”
#Initialize Agent with the APIagent = Agent(model, source, api_dict) print(agent.generate(“hi!”)) #Test the API
#Initialize MemoRAG pipeline with a customized generator modelpipe = MemoRAG( mem_model_name_or_path=”TommyChien/memorag-qwen2-7b-inst”, ret_model_name_or_path=”BAAI/bge-m3″, cache_dir=”path_to_model_cache”, #Optional: specify local model cache directory customized_gen_model=agent, )
更多详细的应用,请参考MemoRAG的项目主页。
6
实验结果
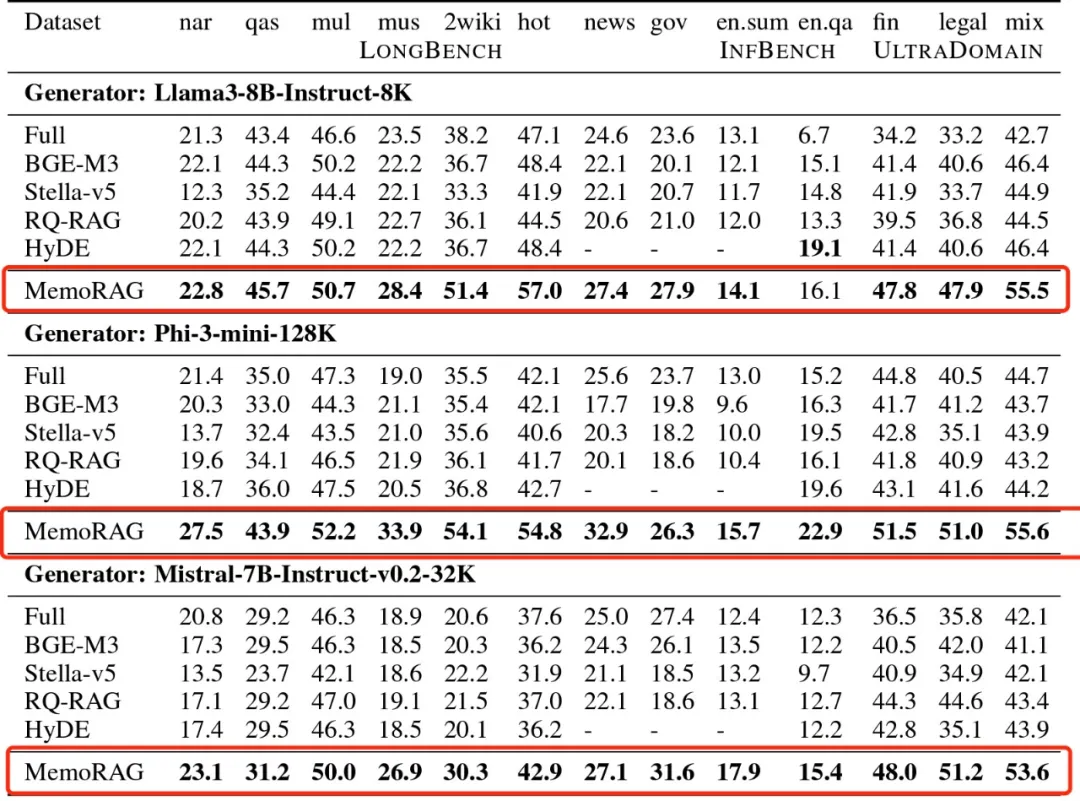
在三个基准上测试了MemoRAG,使用了三种不同的模型作为生成器(Llama3-8B-Instruct-8K、Phi-3-mini-128K、Mistral-7B-Instruct-v0.2-32K),实验结果显示MemoRAG在不同的任务场景下,任务效果都超越了基线模型。更多的实验细节,请参考技术报告。
7
小结
MemoRAG 是一个基于高效、超长记忆模型的创新型 RAG(Retrieval-Augmented Generation)框架,旨在推动 RAG 系统在更广泛的应用场景中落地。目前,MemoRAG 在多个基准测试(Benchmark)上的实验结果均优于基线模型,并且支持通过项目代码快速部署使用。然而,MemoRAG 项目仍处于初期阶段,欢迎社区用户提供更多使用反馈。智源将持续优化 MemoRAG 的可用性,重点提升模型的轻量化、记忆机制的多样性以及其在中文语料中的表现。














暂无评论内容