最近在reddit论坛中,有网友向Claude 提供了 OpenAI 发布的信息(包括系统信息、博客文章、GPT o1作者之一Noam Brown 等人的推文、ARC竞赛团队的测试评论)以及与 o1 模型相关的在线讨论(Reddit、YouTube 视频),最终通过逆向工程的方法推测出了OpenAI o1可能的架构流程:
Noam Brown是德扑AI之父,毕业于卡内基梅隆大学,他于2023年7月从Meta离职后加入OpenAI,在OpenAI担任研究科学家,是GPT o1的主要作者之一。

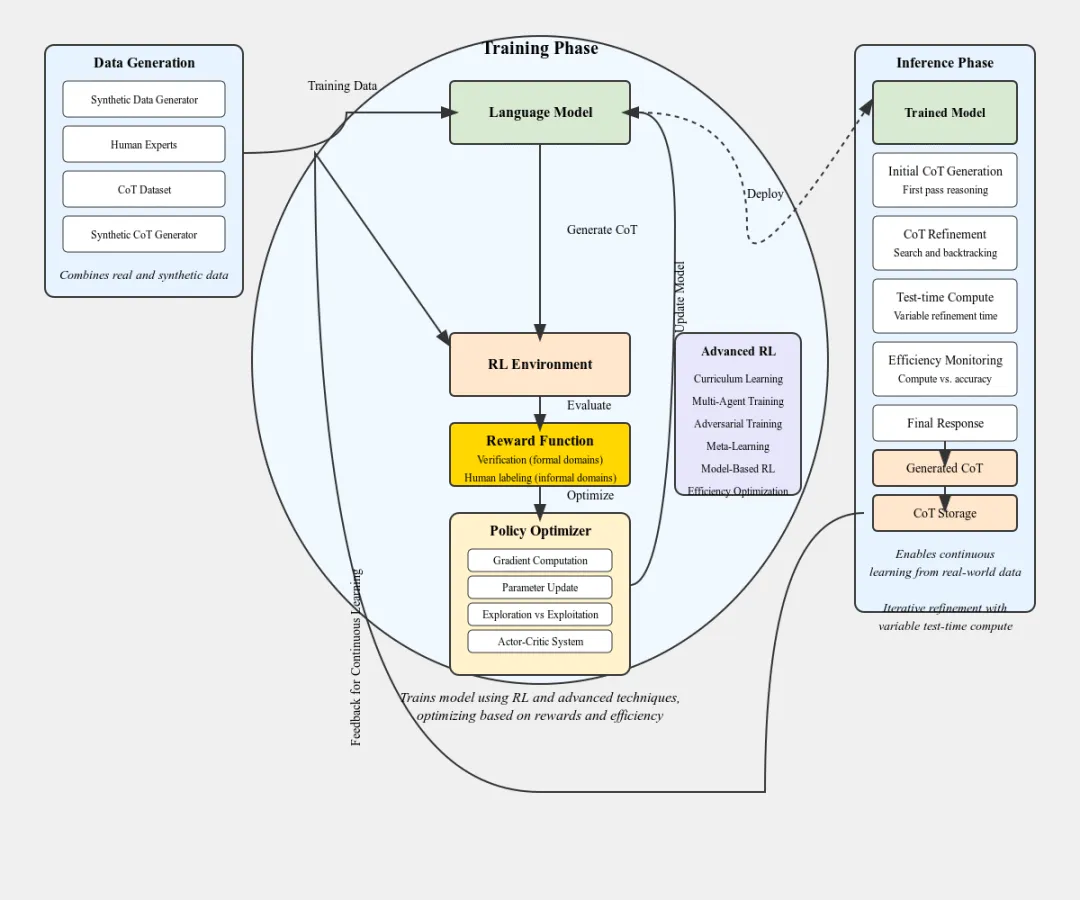
下面是关于这张架构图的详细说明,主要包括四个阶段:
1、数据生成(Data Generation)
数据生成模块负责创建用于训练的数据,包括:
- 合成数据生成器(Synthetic Data Generator)
- 人类专家(Human Experts)
- CoT数据库(CoT Dataset,链式思维数据库)
- 现实世界和沙盒数据(Combined real and sandbox data)
这些数据被汇集起来,形成训练数据,用于后续模型的训练阶段。
2、训练阶段(Training Phase)
训练阶段主要由以下几个模块组成:
语言模型(Language Model),这是核心的AI模型,负责处理和理解语言数据。
RL环境(RL Environment),强化学习环境用于模型优化。
奖励函数(Reward Function),包括验证(Verification)和人类反馈(Human labeling),用来指导模型学习。
策略优化器(Policy Optimizer),包括梯度压缩、Panzar系统、探索与利用等,用于优化模型策略。在这个阶段,模型通过强化学习和高级技术进行训练,不断优化性能和效率。
3、推理阶段(Inference Phase)推理阶段只要包括:
训练好的模型(Trained Model),这个阶段已经是通过强化学习和高级技术优化后的模型。
多任务生成(Multi-tasking Generation),处理多个任务的能力。
最终响应(Final Response),生成最终的输出结果。
CoT生成和微调(Generated CoT and Refinement),根据链式思维生成并微调结果。
效率监控(Efficiency Monitoring):实时监控模型的性能。
4、关键注释
大规模CoT存储进入RL环境是作者自己的假设,作者认为OpenAI可能会使用从现实世界中生成的大量链式思维来进一步调整和优化RL模型。举例说明:假设你是一名研究员,想要构建一个能够进行多任务处理的AI系统。
我们可以通过参考这个o1架构按照上面三个模块进行以下工作:
- 首先,收集并生成各种类型的数据,包括合成数据、人类专家提供的数据以及现实世界的数据。
- 接着,利用这些数据训练你的语言模型,并在强化学习环境中进行优化,通过奖励函数和策略优化器不断提升模型性能。
- 最后,将训练好的模型部署到推理阶段,使其能够处理多任务并生成最终响应,同时监控其效率并进行必要的微调。这种架构不仅适用于语言处理,还可以扩展到其他领域,如图像识别、游戏开发等,通过不断优化强化学习过程,使得AI系统更加智能高效。














暂无评论内容