本文目录
MiniMind项目介绍
项目开源的内容
目前MiniMind5个型号模型介绍
MiniMind模型结构介绍
基于常规LLAMA系列的大模型
基于MOE结构的大模型
快速上手体验
克隆项目代码
进行模型训练
模型推理测试
参考链接
MiniMind项目介绍
大语言模型(LLM)领域,如 GPT、LLaMA、GLM 等,虽然它们效果惊艳, 但动辄10 Bilion庞大的模型参数个人设备显存远不够训练,甚至推理困难。几乎所有人都不会只满足于用Lora等方案fine-tuing大模型学会一些新的指令, 这约等于在教牛顿玩21世纪的智能手机,然而,这远远脱离了学习物理本身的奥妙。此外,卖课付费订阅的营销号漏洞百出的一知半解讲解AI的教程遍地, 让理解LLM的优质内容雪上加霜,严重阻碍了学习者。

项目开源的内容
github社区大佬jingyaogong开源MiniMind项目;把上手LLM的门槛无限降低, 直接从0开始训练一个极其轻量的语言模型。项目包含:
- 公开MiniMind模型代码(包含Dense和MoE模型)、Pretrain、SFT指令微调、LoRA微调、DPO偏好优化的全过程代码、数据集和来源。
- 兼容transformers、accelerate、trl、peft等流行框架。
- 训练支持单机单卡、单机多卡训练。训练过程中支持在任意位置停止,及在任意位置继续训练。
- 在Ceval数据集上进行模型测试的代码。
- 实现Openai-Api基本的chat接口,便于集成到第三方ChatUI使用(FastGPT、Open-WebUI等)。希望此开源项目可以帮助LLM初学者快速入门!
目前MiniMind5个型号模型介绍
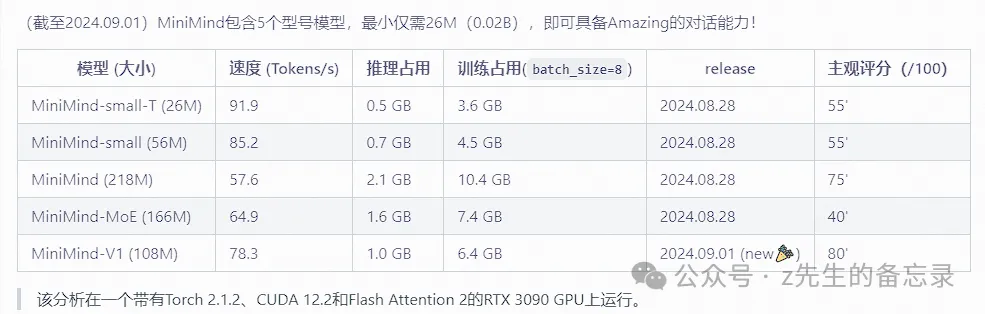
对应模型的参数信息如下:
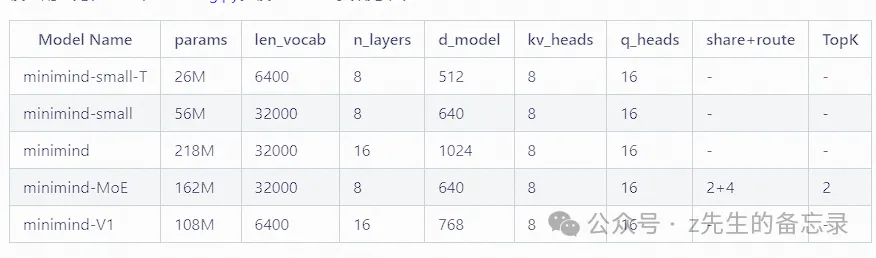
MiniMind模型结构介绍
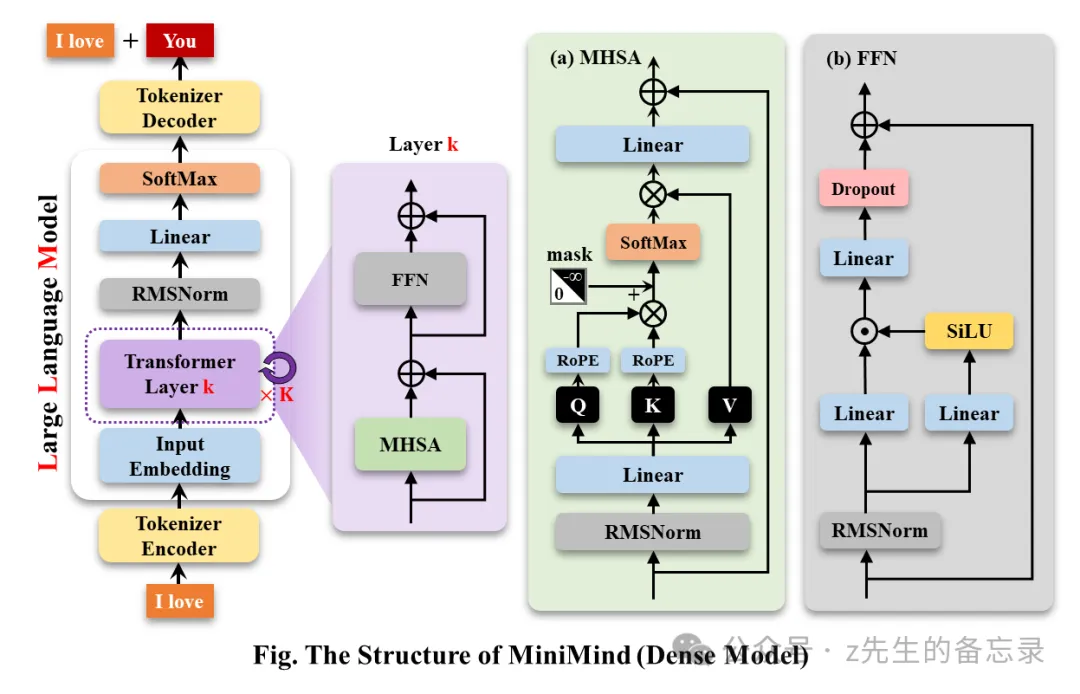
基于常规LLAMA系列的大模型
MiniMind的整体结构一致,只是在RoPE计算、推理函数和FFN层的代码上做了一些小调整;
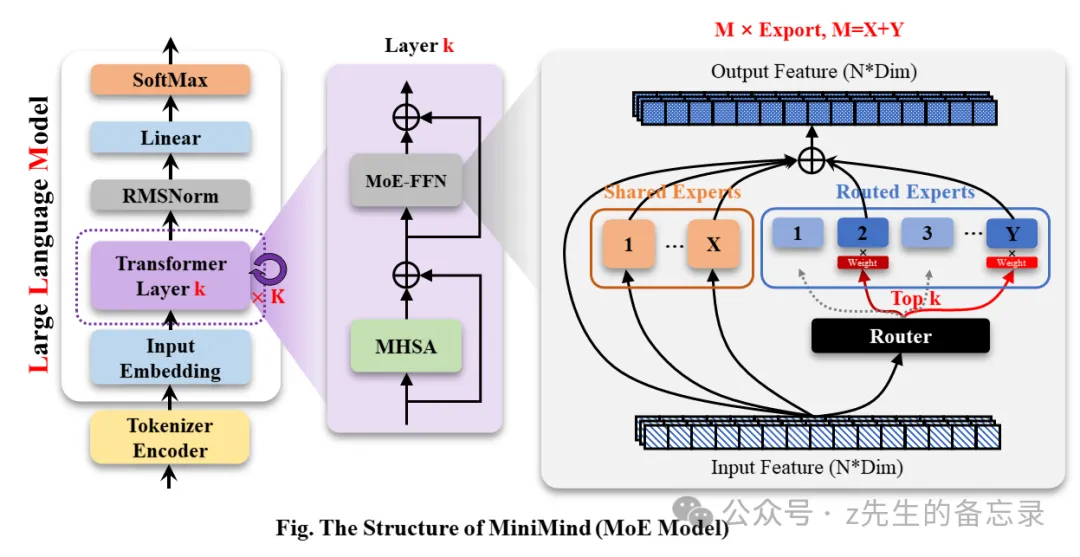
基于MOE结构的大模型
快速上手体验
克隆项目代码
git clone https://github.com/jingyaogong/minimind.git
进行模型训练
* 下载数据集下载地址放到./dataset目录下
* python data_process.py处理数据集,例如pretrain数据提前进行token-encoder、sft数据集抽离qa到csv文件。
* 在./model/LMConfig.py 中调整model的参数配置。
* python 1-pretrain.py 执行预训练。
* python 3-full_sft.py 执行指令微调。
* python 4-lora_sft.py 执行lora微调(非必须)。
* python 5-dpo_train.py 执行DPO人类偏好强化学习对齐(非必须)。
模型推理测试
【训练完成的模型权重】下载权重到./out/目录下
out
├── multi_chat
│ ├── full_sft_1024.pth
│ ├── full_sft_512.pth
│ ├── full_sft_640_moe.pth
│ └── full_sft_640.pth
├── single_chat
│ ├── full_sft_1024.pth
│ ├── full_sft_512.pth
│ ├── full_sft_640_moe.pth
│ └── full_sft_640.pth
├── full_sft_1024.pth
├── full_sft_512.pth
├── full_sft_640_moe.pth
├── full_sft_640.pth
├── pretrain_1024.pth
├── pretrain_640_moe.pth
├── pretrain_640.pth
python 0-eval_pretrain.py测试预训练模型的接龙效果
python 2-eval.py测试模型的对话效果
这是测试模型的对话效果展示:

#【Tip】预训练和全参微调pretrain和full_sft均支持DDP多卡加速
# 单机N卡启动训练
torchrun –nproc_per_node N 1-pretrain.py
torchrun –nproc_per_node N 3-full_sft.py














暂无评论内容