今天,我们完成了 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2 两个模型的合并,正式发布 DeepSeek-V2.5。DeepSeek-V2.5 不仅保留了原有 Chat 模型的通用对话能力和 Coder 模型的强大代码处理能力,还更好地对齐了人类偏好。此外,DeepSeek-V2.5 在写作任务、指令跟随等多个方面也实现了大幅提升。DeepSeek-V2.5 现已在网页端及 API 全面上线,API 接口向前兼容,用户通过deepseek-coder 或 deepseek-chat 均可以访问新的模型。同时,Function Calling、FIM 补全、Json Output 等功能保持不变。All-in-One 的 DeepSeek-V2.5 将为用户带来更简洁、智能、高效的使用体验。
 升级历史
升级历史
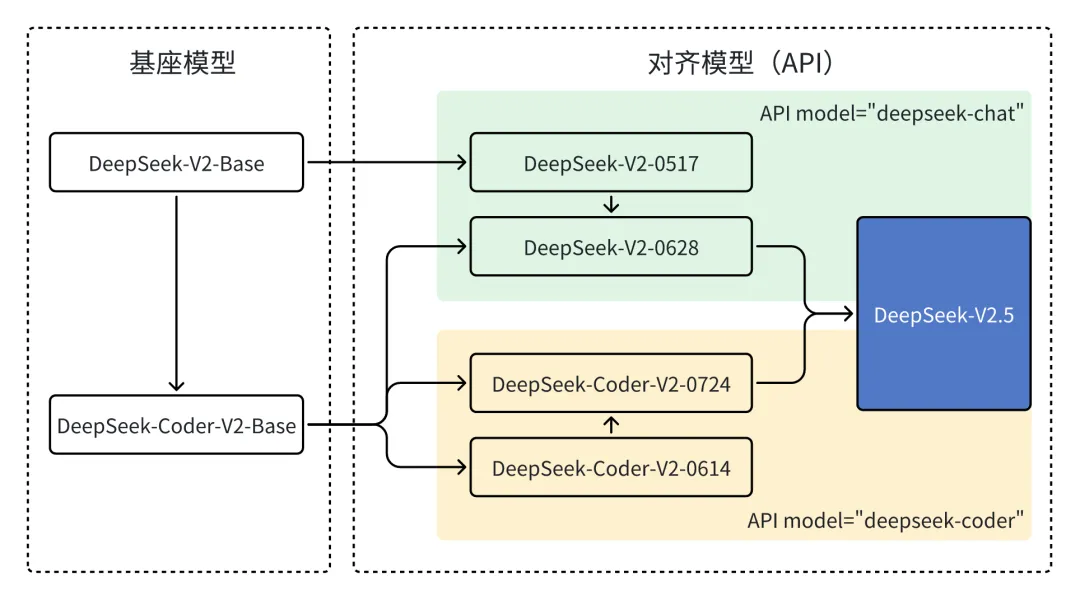
DeepSeek 一直专注于模型的改进和优化。在 6 月份,我们对 DeepSeek-V2-Chat 进行了重大升级,用 Coder V2 的 Base 模型替换原有的 Chat 的 Base 模型,显著提升了其代码生成和推理能力,并发布了 DeepSeek-V2-Chat-0628 版本。紧接着,DeepSeek-Coder-V2 在原有 Base 模型的基础上,通过对齐优化,大大提升通用能力后推出了 DeepSeek-Coder-V2 0724 版本。最终,我们成功将 Chat 和 Coder 两个模型合并,推出了全新的DeepSeek-V2.5 版本。
 由于本次模型版本变动较大,如出现某些场景效果变差,建议重新调整 System Prompt 和 Temperature,以获得最佳性能。
由于本次模型版本变动较大,如出现某些场景效果变差,建议重新调整 System Prompt 和 Temperature,以获得最佳性能。
 通用能力
通用能力
- 通用能力测评
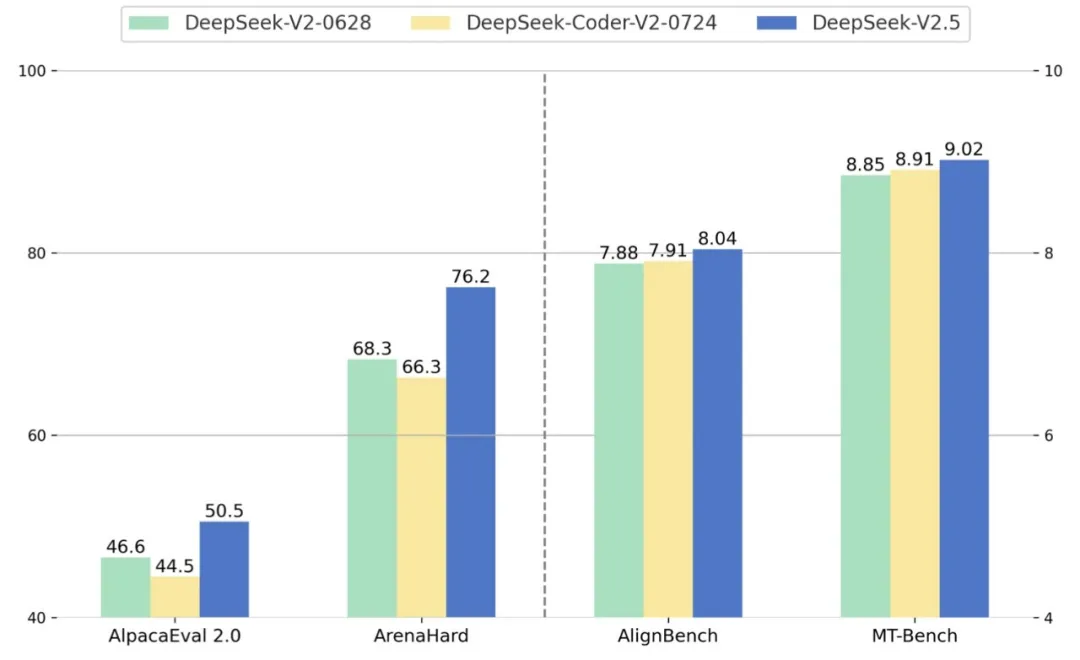
首先,我们使用业界通用的测试集对 DeepSeek-V2.5 的能力进行测评,在中文和英文四个测试集上,DeepSeek-V2.5 均优于之前的 DeepSeek-V2-0628 以及 DeepSeek-Coder-V2-0724。
在我们内部的中文评测中,和 GPT-4o mini、ChatGPT-4o-latest 的对战胜率(裁判为 GPT-4o)相较于 DeepSeek-V2-0628 均有明显提升。此测评中涵盖创作、问答等通用能力,用户使用体验将得到提升:
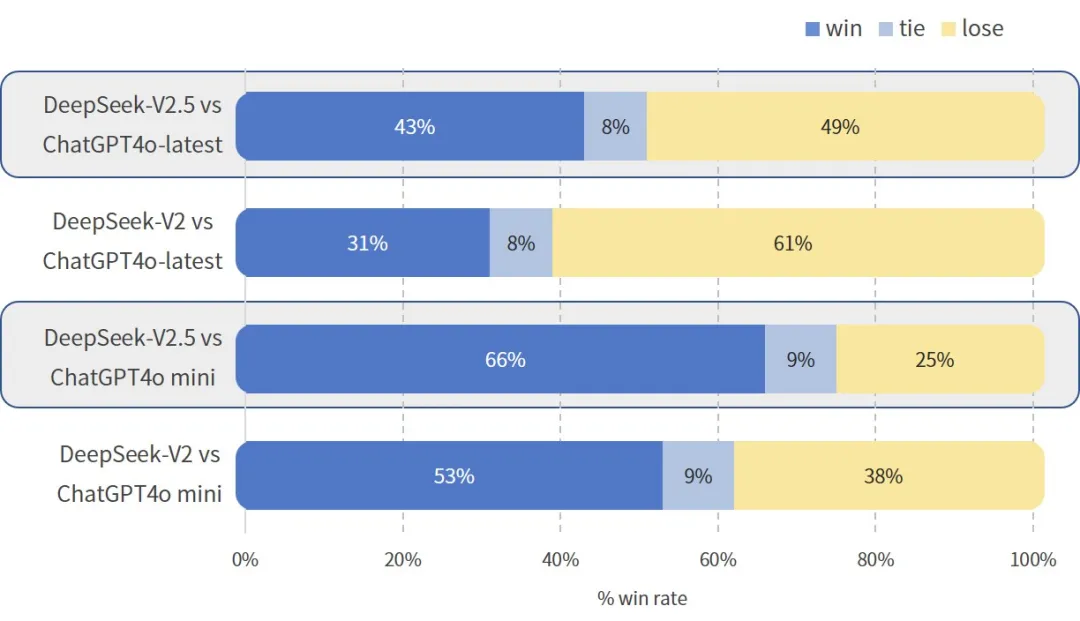
DeepSeek-v2.5 Preference Evaluation
- 安全能力测评
Safety 和 Helpful 之间的权衡是我们在迭代开发中一直重点关注的问题。在 DeepSeek-V2.5 版本中,我们对于模型安全问题的边界做了更加清晰的划分,在强化模型对于各种越狱攻击的安全性的同时,减少了安全策略过度泛化到正常问题中去的倾向。
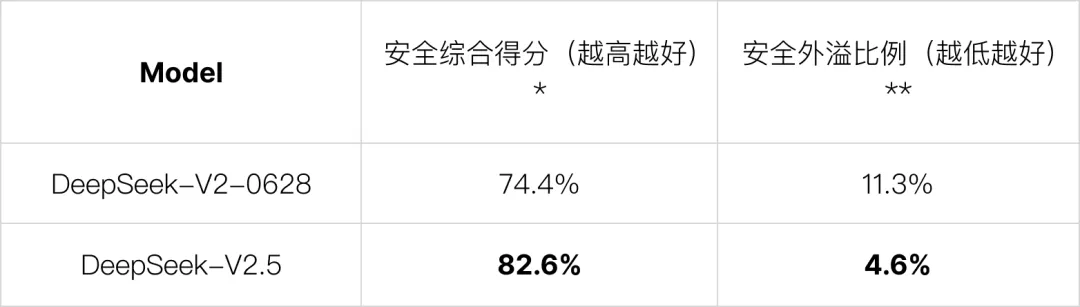
*基于内部测试集合的得分,分数越高代表模型的整体安全性越高
**基于内部测试集合的得分,比例越低代表模型的安全策略对于正常问题的影响越小
 代码能力
代码能力
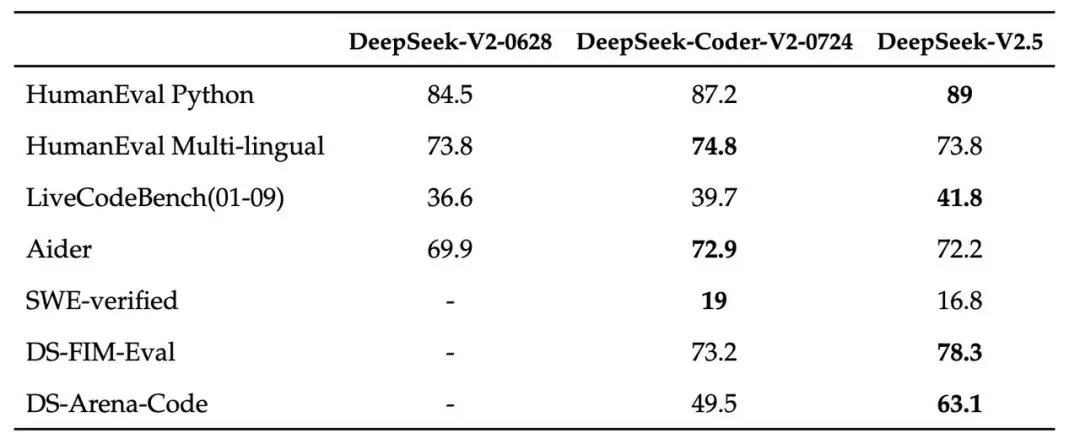
在代码方面,DeepSeek-V2.5 保留了 DeepSeek-Coder-V2-0724 强大的代码能力。在 HumanEval Python 和LiveCodeBench(2024 年 1 月 – 2024 年 9 月)测试中,DeepSeek-V2.5 显示了较为显著的改进。在 HumanEval Multilingual 和 Aider 测试中,DeepSeek-Coder-V2-0724 略胜一筹。在 SWE-verified 测试中,两个版本的表现都较低,表明在此方面仍需进一步优化。另外,在FIM补全任务上,内部评测集DS-FIM-Eval的评分提升了 5.1%,可以带来更好的插件补全体验。另外,DeepSeek-V2.5对代码常见场景进行了优化,以提升实际使用的表现。在内部的主观评测 DS-Arena-Code 中,DeepSeek-V2.5 对战竞品的胜率(GPT-4o 为裁判)取得了显著提升。
模型开源
一如既往,秉持着持久开源的精神,DeepSeek-V2.5 现已开源到了 HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V2.5















暂无评论内容