QWen2_VL多模态大模型介绍

千问团队在开源Qwen2_math(阿里重磅开源Qwen2_Math! 实操利用onnxocr+Qwen2_Math打造【AI数学老师助手】来给小孩辅导数学作业!)、Qwen2_Audio(Qwen2_Audio语音大模型来啦!语音内容分析、情绪分析、语言翻译轻松拿捏!手把手带你实操部署让其扮演翻译官、情绪安抚师~)垂直领域大模型之后,在8月底又重磅开源Qwen2-VL 多模态大模型。Qwen2-VL 基于 Qwen2 打造,相比 Qwen-VL,它具有以下特点:
读懂不同分辨率和不同长宽比的图片:Qwen2-VL 在 MathVista、DocVQA、RealWorldQA、MTVQA 等视觉理解基准测试中取得了全球领先的表现。
理解20分钟以上的长视频:Qwen2-VL 可理解长视频,并将其用于基于视频的问答、对话和内容创作等应用中。
能够操作手机和机器人的视觉智能体:借助复杂推理和决策的能力,Qwen2-VL 可集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作。
多语言支持:为了服务全球用户,除英语和中文外,Qwen2-VL 现在还支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
QWen2_VL模型架构
整体上千问团队仍然延续了 Qwen-VL 中 ViT 加 Qwen2 的串联结构,在三个不同尺度的模型上,采用 600M 规模大小的 ViT,并且支持图像和视频统一输入。为了让模型更清楚地感知视觉信息和理解视频,我们还进行了以下升级:
Qwen2-VL 在架构上的一大改进是实现了对原生动态分辨率的全面支持。与上一代模型相比,Qwen2-VL 能够处理任意分辨率的图像输入,不同大小图片被转换为动态数量的 tokens,最小只占 4 个 tokens。这种设计不仅确保了模型输入与图像原始信息之间的高度一致性,更是模拟了人类视觉感知的自然方式,赋予模型处理任意尺寸图像的强大能力,使其在图像处理领域展现出更加灵活和高效的表现。
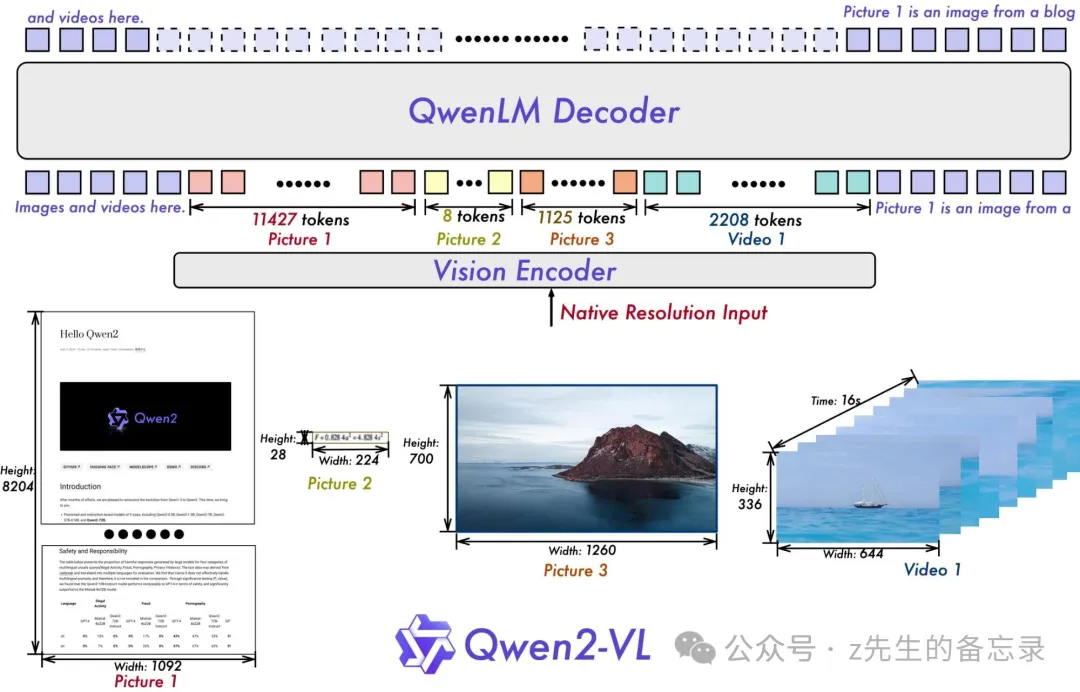
Qwen2-VL 在架构上的另一重要创新则是多模态旋转位置嵌入(M-ROPE)。传统的旋转位置嵌入只能捕捉一维序列的位置信息,而 M-ROPE 通过将原始旋转嵌入分解为代表时间、高度和宽度的三个部分,使得大规模语言模型能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息。这一创新赋予了语言模型强大的多模态处理和推理能力,能够更好地理解和建模复杂的多模态数据。

QWen2_VL性能介绍
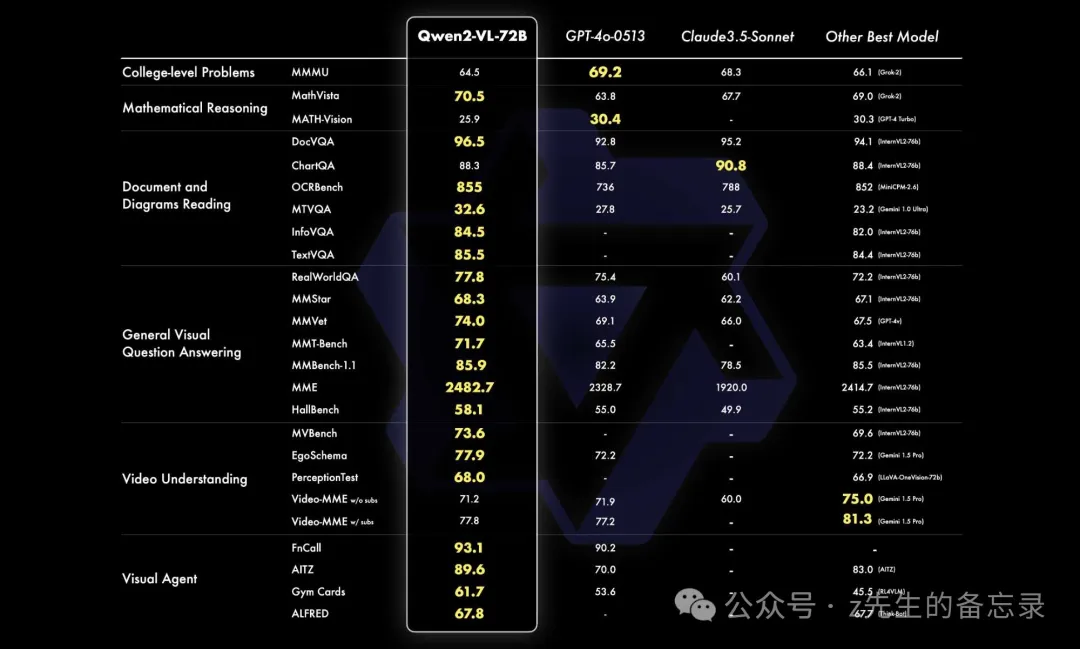
千问团队从六个方面来评估我们模型的视觉能力,包括综合的大学题目、数学能力、文档表格多语言文字图像的理解、通用场景下的问答、视频理解、Agent 能力。整体来看, 72B 规模的模型在大部分的指标上都达到了最优,甚至超过了 GPT-4o 和 Claude3.5-Sonnet 等闭源模型,特别是在文档理解方面优势明显,仅在对综合的大学题目上和 GPT-4o 还有差距。同时 Qwen2-VL 72B 也刷新了开源多模态模型的最好表现。
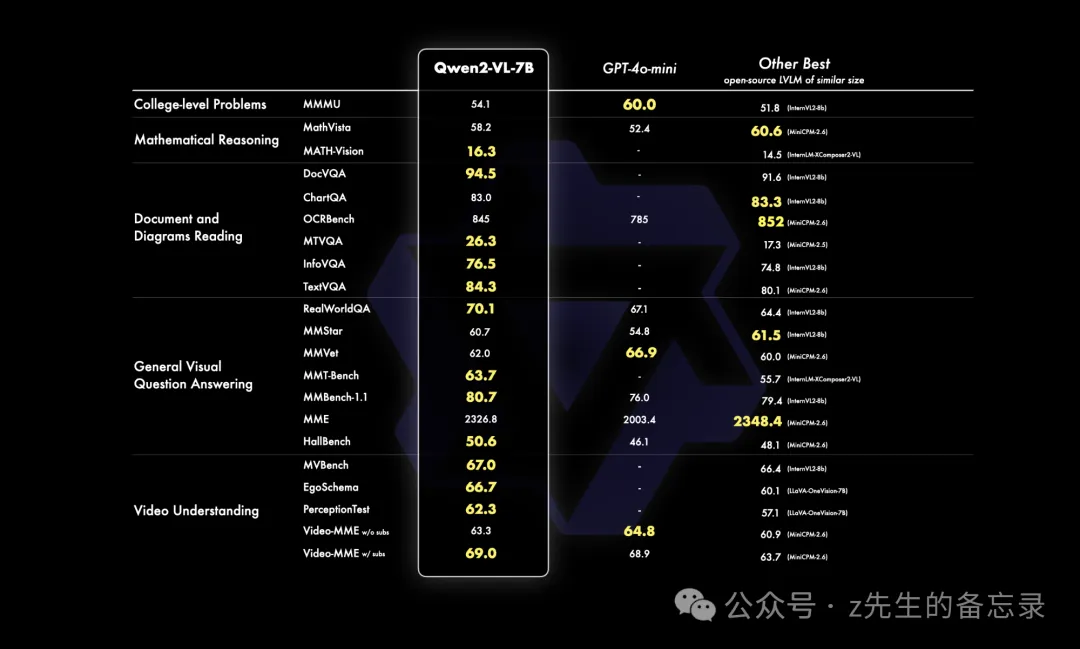
在 7B 规模上,我们同样支持图像、多图、视频的输入,在更经济的规模上也实现了有竞争力的性能表现,特别是像 DocVQA 之类的文档理解能力和 MTVQA 考察的图片中多语言文字理解能力都处于 SOTA 水平。
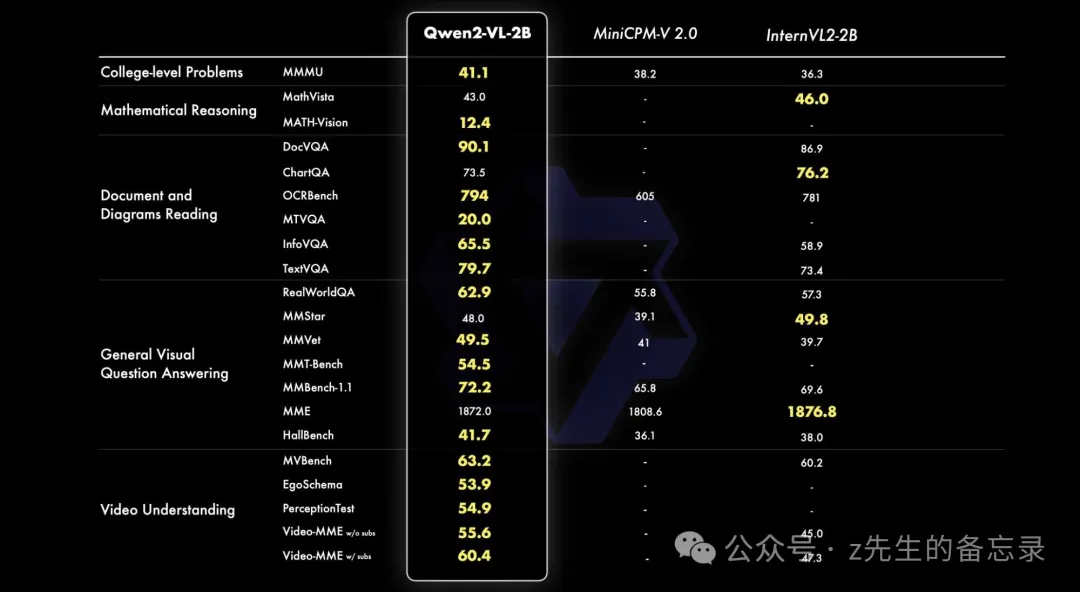
千问团队还提供了一个更小的 2B 规模的模型,以此支持移动端的丰富应用。它具备完整图像视频多语言的理解能力,性能强劲,特别在视频文档和通用场景问答相较同规模模型优势明显。
这效果看着牛逼呀,之前也给大家分享MiniCPM_v_2.6多模态大模型,想找几个真实的案例来实测一下,看看谁更强?
实战部署QWen2_VL_7B多模态大模型
由于我没得显卡,只能白嫖kaggle平台的P100 16G显卡,具体可参考文章:免费GPU资源大放送!深度学习、大模型/AIGC必备白嫖神器,让你轻松开启AI之旅!,因此不能以半精度float16加载QWen2_VL_7B多模态大模型,显存会爆;决定采用int4量化的方式来加载QWen2_VL_7B_Instruct大模型。
以int4量化加载QWen2_VL_7B_Instruct大模型
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor, BitsAndBytesConfig
model_name= “Qwen/Qwen2-VL-7B-Instruct”
processor = AutoProcessor.from_pretrained(model_name)
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True, #QLoRA 设计的 Double Quantization
bnb_4bit_quant_type=”nf4″, #QLoRA 设计的 Normal Float 4 量化数据类型
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
model = Qwen2VLForConditionalGeneration.from_pretrained(model_name,
quantization_config=bnb_config,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval()
model
模型的网络结构如下:

进行效果推理
测试图片

进行推理
%%time
clean_memory()
import requests
from PIL import Image as PImage# Image
image = PImage.open(“7d43642c-85c6-4183-a527-b8042cd4eda8.png”)
conversation = [
{
“role”: “user”,
“content”: [
{
“type”: “image”,
},
{“type”: “text”, “text”: “描述图片中的内容.”},
],
}
]
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(
text=[text_prompt], images=[image], padding=True, return_tensors=”pt”
)
inputs = inputs.to(“cuda”)
# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
output_text = processor.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
print(output_text)
模型输出的结果:

我去这个输出的是什么??感觉中毒了,可能是通过int4量化导致QWen2_VL_7B_Instruct大模型的性能大幅度下降,通过代码来推理可能无法实现评测。于是我在魔塔社区找到官方的部署的在线推理:https://www.modelscope.cn/studios/qwen/Qwen2-7B-VL-demo。界面如下
效果篇: Qwen2-VL-7B-Instruct VS MiniCPM-V-2.6效果对比
之前给大家介绍过【国内版GPT4V来啦】面壁智能开源最强端侧多模态大模型MiniCPM-V2.6;支持图片、视频理解,实操各类复杂表格轻松识别!; 我就很好奇2个多模态大模型谁更强?于是我找了几个案例来测试了一把,仅供参考~
模型来源:
- Qwen2-VL-7B-Instruct模型: https://www.modelscope.cn/studios/qwen/Qwen2-7B-VL-demo
- MiniCPM-V-2.6-int4模型: https://hf-mirror.com/openbmb/MiniCPM-V-2_6-int4
案例一: 识别图片中的计算题并计算结果(Qwen2-VL 优于 MiniCPM-V-2.6-int4)
Qwen2-VL-7B-Instruct的运行结果
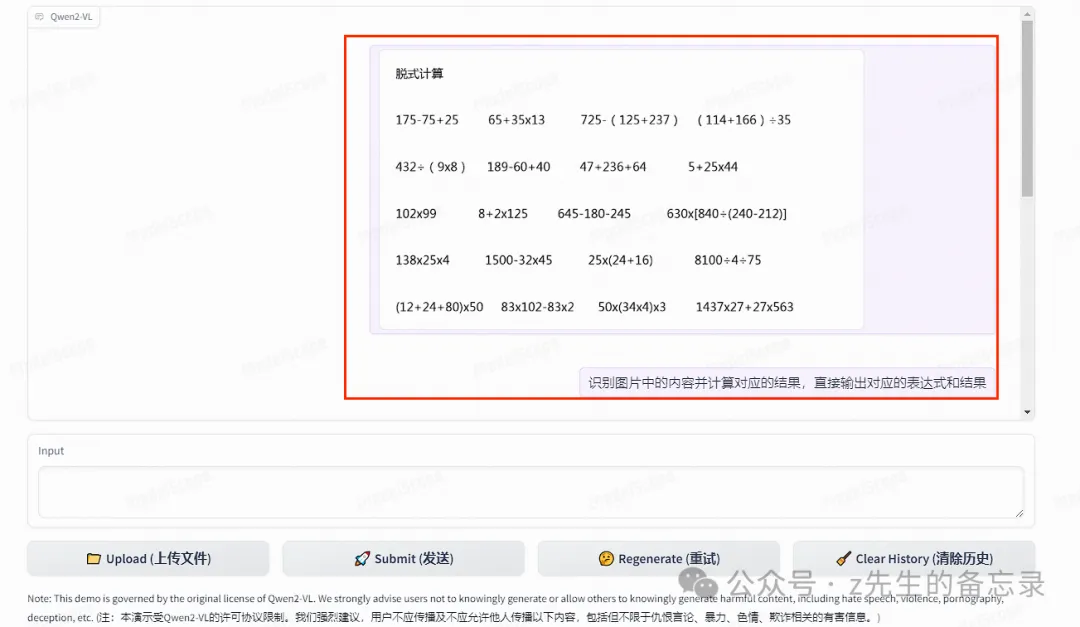
完整的输出结果:
175-75+25 =100+25 =125
65+35×13 =65+455 =520
725-( 125+237 ) =725-362 =363
( 114+166 )÷35 =280÷35 =8
432÷( 9×8 ) =432÷72 =6
189-60+40 =129+40 =169
47+236+64 =283+64 =347
5+25×44 =5+1100 =1105
102×99 =10102
8+2×125 =8+250 =258
645-180-245 =465-245 =220
630x[840÷(240-212)] =630x[840÷28] =630×30 =18900
138x25x4 =138×100 =13800
1500-32×45 =1500-1440 =60
25x(24+16) =25×40 =1000
8100÷4÷75 =2025÷75 =27
(12+24+80)x50 =116×50 =5800
83×102-83×2 =83x(102-2) =83×100 =8300
50x(34×4)x3 =50x136x3 =50×408 =20400
1437×27+27×563 =27x(1437+563) =27×2000 =54000
其中102×99 =10102 计算错误,计算错了1道题,对了19道。
MiniCPM-V-2.6-int4的运行结果
其中第7题、第9题、第13题、第20题错了,对了16道。
Qwen2_VL_7B_Instruct大模型的性能是大于MiniCPM-V-2.6-int4模型的性能的。
案例二: 识别图片中的内容以json格式输出(Qwen2-VL 等于 MiniCPM-V-2.6-int4)
测试图片

Qwen2-VL-7B-Instruct的运行结果

。
MiniCPM-V-2.6-int4的运行结果
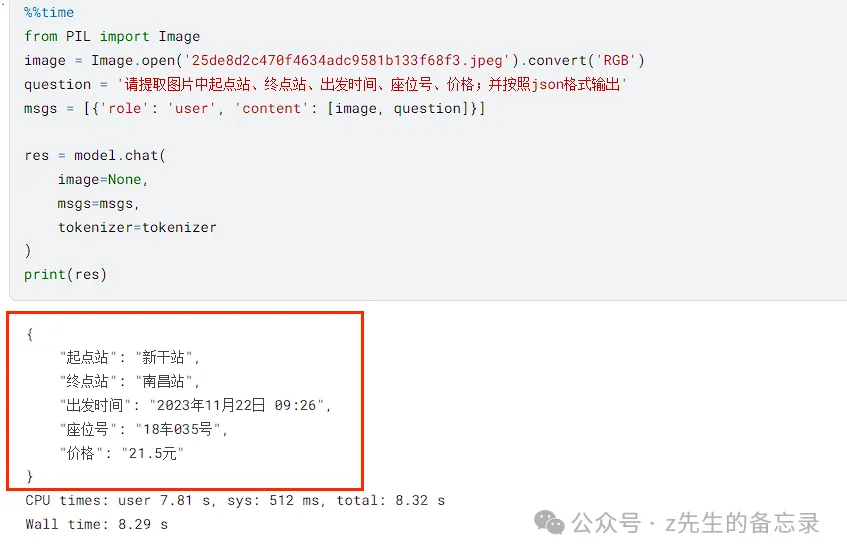
输出的结果都是对的。
案例三: 识别复杂式中国表格类图片对应的内容(Qwen2-VL 小于 MiniCPM-V-2.6-int4)
测试表格图片
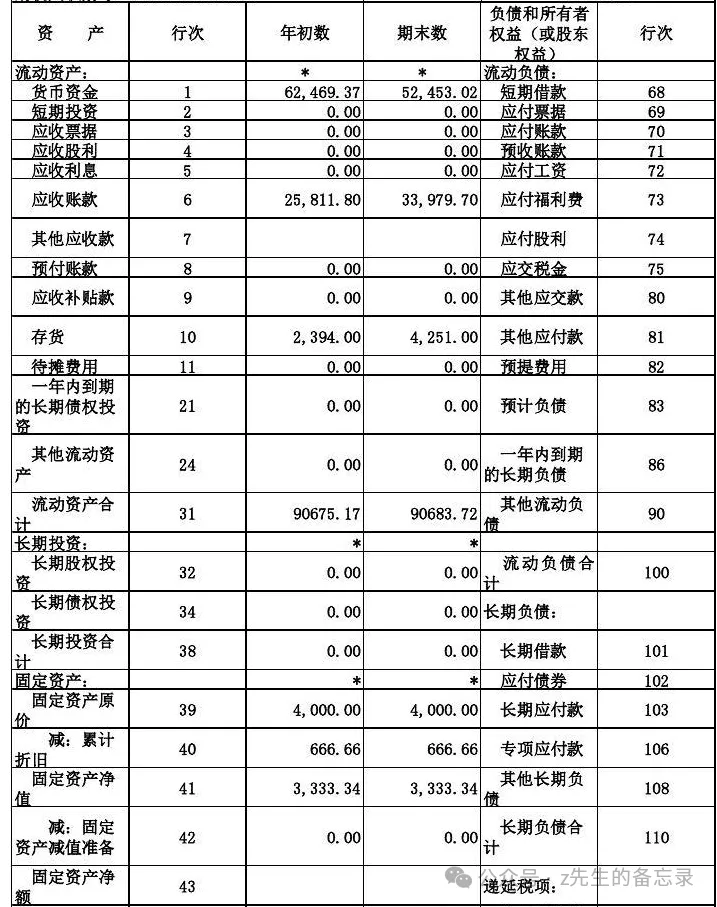
Qwen2-VL-7B-Instruct的运行结果
完整的输出:
[{“流动资产”: [
{
“货币资金”: [
{
“行次”: 1,
“年初数”: “62,469.37”,
“期末数”: “52,453.02”
}
]
},
{
“短期投资”: [
{
“行次”: 2,
“年初数”: “0.00”,
“期末数”: “0.00”
}
]
},
{
“应收票据”: [
{
“行次”: 3,
“年初数”: “0.00”,
“期末数”: “0.00”
}
]
},
{
“应收账款”: [
{
“行次”: 6,
“年初数”: “25,811.80”,
“期末数”: “33,979.70”
}
]
},
{
“存货”: [
{
“行次”: 10,
“年初数”: “2,394.00”,
“期末数”: “4,251.00”
}
]
},
{
“待摊费用”: [
{
“行次”: 11,
“年初数”: “0.00”,
“期末数”: “0.00”
}
]
},
{
“一年内到期的长期债权投资”: [
{
“行次”: 21,
“年初数”: “0.00”,
“期末数”: “0.00”
}
]
},
{
“其他流动资产”: [
{
“行次”: 24,
“年初数”: “0.00”,
“期末数”: “0.00”
}
]
}
]
}
]
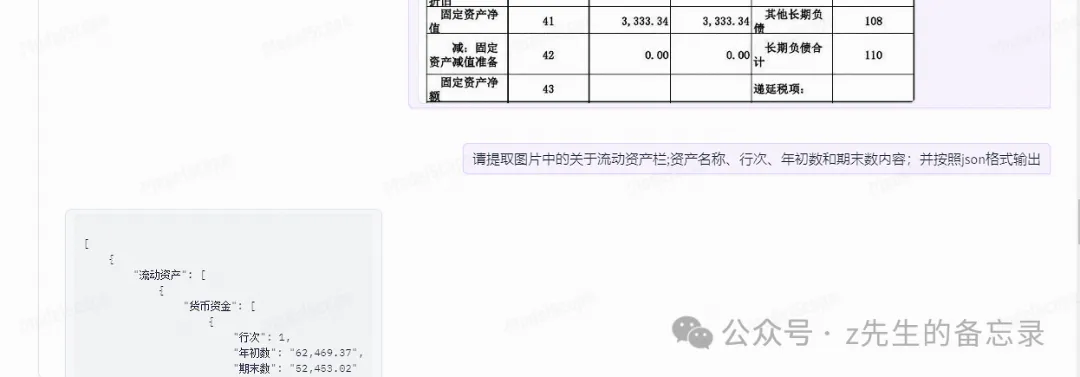
MiniCPM-V-2.6-int4的运行结果
输出完全的结果:
{
“流动资产”: [
{
“名称”: “货币资金”,
“行次”: 1,
“年初数”: “62,469.37”,
“期末数”: “52,453.02”
},
{
“名称”: “短期投资”,
“行次”: 2,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “应收票据”,
“行次”: 3,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “应收股利”,
“行次”: 4,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “应收利息”,
“行次”: 5,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “应收账款”,
“行次”: 6,
“年初数”: “25,811.80”,
“期末数”: “33,979.70”
},
{
“名称”: “其他应收款”,
“行次”: 7,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “预付账款”,
“行次”: 8,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “应收补贴款”,
“行次”: 9,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “存货”,
“行次”: 10,
“年初数”: “2,394.00”,
“期末数”: “4,251.00”
},
{
“名称”: “待摊费用”,
“行次”: 11,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “一年内到期的长期债权投资”,
“行次”: 21,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “其他流动资产”,
“行次”: 24,
“年初数”: “0.00”,
“期末数”: “0.00”
},
{
“名称”: “流动资产合计”,
“行次”: 31,
“年初数”: “90675.17”,
“期末数”: “90683.72”
}
]
}
CPU times: user 50.2 s, sys: 383 ms, total: 50.6 s
Wall time: 50.5 s
可以看出MiniCPM-V-2.6-int4输出的结果完全正确,而Qwen2-VL输出有漏的。
案例四: 识别复杂式表格类图片转为markdown语法(Qwen2-VL 小于 MiniCPM-V-2.6-int4)
测试图片
Qwen2-VL-7B-Instruct的运行结果
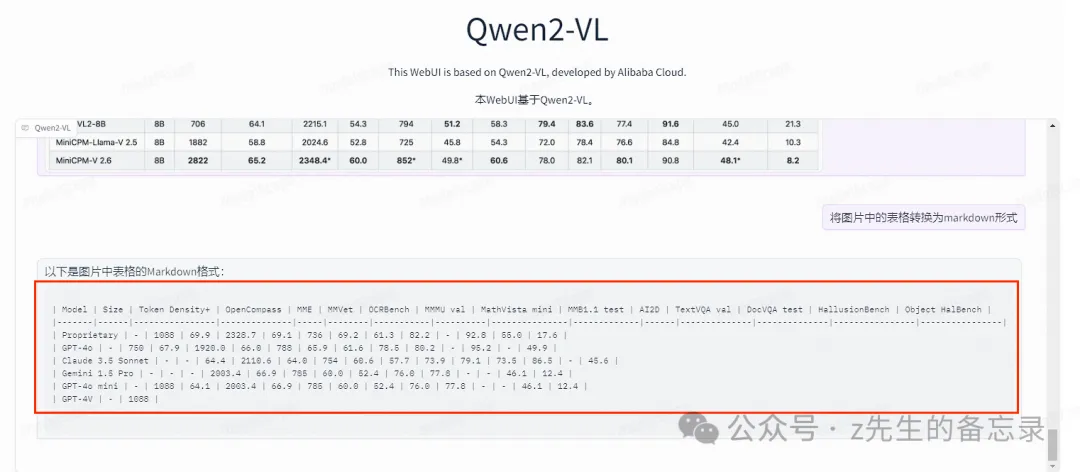
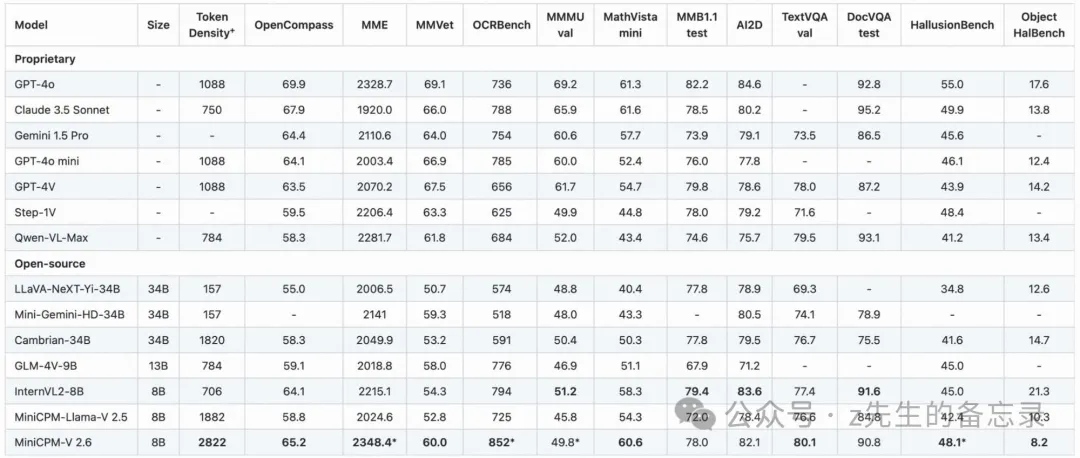
MiniCPM-V-2.6-int4的运行结果
| Model | Size | Token Density* | OpenCompass | MME | MMVet | OCRBench | MMMU val | MathVista val | MMB1.1 test | AI2D | TextVQA val | DocVQA test | HallusionBench | Object HalBench |
| — | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| Proprietary | | | | | | | | | | | | | |
| GPT-4o | – | 1088 | 69.9 | 2328.7 | 69.1 | 736 | 69.2 | 61.3 | 82.2 | 84.6 | – | 92.8 | 55.0 | 17.6 |
| Claude 3.5 Sonnet | – | 750 | 67.9 | 1920.0 | 66.0 | 788 | 65.9 | 61.6 | 78.5 | 80.2 | – | 95.2 | 49.9 | 13.8 |
| Gemini 1.5 Pro | – | – | 64.4 | 2110.6 | 64.0 | 754 | 60.6 | 57.7 | 73.9 | 79.1 | 73.5 | 86.5 | 45.6 | – |
| GPT-4o mini | – | 1088 | 64.1 | 2003.4 | 66.9 | 785 | 60.0 | 52.4 | 76.0 | 77.8 | – | – | 46.1 | 12.4 |
| GPT-4V | – | 1088 | 63.5 | 2070.2 | 67.5 | 656 | 61.7 | 54.7 | 79.8 | 78.6 | 78.0 | 87.2 | 43.9 | 14.2 |
| Step-1V | – | – | 59.5 | 2206.4 | 63.3 | 625 | 49.9 | 44.8 | 78.0 | 79.2 | 71.6 | – | 48.4 | – |
| Qwen-VL-Max | – | – | 784 | 2281.7 | 61.8 | 684 | 52.0 | 43.4 | 74.6 | 75.7 | 79.5 | 93.1 | 41.2 | 13.4 |
| Open-source | | | | | | | | | | | | | |
| LLaVA-NeXT-Yi-34B | 34B | 157 | 55.0 | 2006.5 | 50.7 | 574 | 48.8 | 40.4 | 77.8 | 78.9 | 69.3 | – | 34.8 | 12.6 |
| Mini-Gemini-HD-34B | 34B | 157 | – | 2141 | 59.3 | 518 | 48.0 | 43.3 | – | 80.5 | 74.1 | 78.9 | – | – |
| Cambrian-34B | 34B | 1820 | 58.3 | 2049.9 | 53.2 | 591 | 50.4 | 50.3 | 77.8 | 79.5 | 76.7 | 75.5 | 41.6 | 14.7 |
| GLM-4V-9B | 13B | 784 | 59.1 | 2018.8 | 58.0 | 776 | 46.9 | 51.1 | 67.9 | 71.2 | – | – | 45.0 | – |
| InternVL2-8B | 8B | 706 | 64.1 | 2215.1 | 54.3 | 794 | 51.2 | 58.3 | 79.4 | 83.6 | 77.4 | 91.6 | 45.0 | 21.3 |
| MiniCPM-Llama-V 2.5 | 8B | 1882 | 58.8 | 2024.6 | 52.8 | 725 | 45.8 | 54.3 | 72.0 | 78.4 | 76.6 | 84.8 | 42.4 | 10.3 |
| MiniCPM-V 2.6 | 8B | 2822 | 65.2 | 2348.4* | 60.0 | 852* | 49.8* | 60.6 | 78.0 | 82.1 | 80.1 | 90.8 | 48.1* | 8.2 |
CPU times: user 1min 51s, sys: 689 ms, total: 1min 52s
Wall time: 1min 52s
可以看出MiniCPM-V-2.6-int4输出的结果完全正确,而Qwen2-VL输出不完整并且有遗漏的。
测试小结
从上面的4个案例来看,仅供参考~
- 由魔塔的界面使用的Qwen2-VL-7B-Instruct大模型,在OCR层面和数据逻辑计算还是不错的。
- Qwen2-VL-7B-Instruct在复杂类的报表图片内容识别性能是低于MiniCPM-V-2.6多模态大模型的。














暂无评论内容