微软刚刚搞出了一个叫YOCO(You Only Cache Once)的新架构,号称能让大模型在大幅减少显存占用的同时,还能保留全局注意力能力。

那这个YOCO到底是何方神圣呢?
为啥能让大模型又瘦身又不掉智商呢?
来一探究竟!
YOCO:一次缓存解千愁
YOCO的全称是”You Only Cache Once”,翻译过来就是”你只需缓存一次“。
这个架构的核心思想是把每一层拆成两半:
前半部分:用高效的自注意力机制生成KV缓存的向量
后半部分:专门用KV缓存来生成输出token的嵌入
听起来有点绕?
首先,得了解一下KV缓存是个啥。
KV缓存,全称Key-Value缓存,是Transformer模型中注意力机制的关键。它能存储生成的key和value向量,这样后续的token就可以重复使用这些缓存值,大大减少计算时间。
这也是为啥decoder-only模型这么受欢迎的主要原因。

那YOCO是怎么玩的呢?
它用了两种高效的自注意力(ESA)方法:
门控保留ESA:
用递归公式来提高内存效率
引入指数衰减和因果掩码
采用数据驱动方法,使用可学习参数
滑动窗口ESA:
把注意力窗口限制在固定数量的token上
在推理时把KV缓存的复杂度降到常数级
然后,YOCO还搞了个跨注意力和跨解码器的操作:
用前半部分的输出创建全局KV缓存
为每个新token生成查询矩阵
在查询和全局KV缓存之间做跨注意力
用归一化和SwiGLU激活来预测下一个token
听起来是不是很高大上?
但有什么好处呢?
显存大杀器
YOCO最牛的地方就是能狠狠削减显存占用。
传统Transformer的内存复杂度是O(L * N * D),而YOCO把它降到了O((N + L) * D)。
当输入规模比层数大得多时,这玩意儿就能近似O(N)了!
而且,YOCO在前半部分用常数大小的缓存,后半部分用全局缓存,这样一来二去,显存占用就大大降低了。
推理加速器
除了省显存,YOCO在推理阶段也有不少优势:
预填充阶段:
自解码器并行处理
预填充时只运行一半的层
比传统Transformer快约30倍
生成阶段:
GPU内存变化更少
吞吐量更高
有网友看到这儿,忍不住就嗨了:
“这不就是GPT-7吗?要是有人把今年的顶尖论文都实现并连接起来,咱们起码能到GPT-7了吧!”
说的挺吓人,再这么下去,AGI 要来得更快了吧?
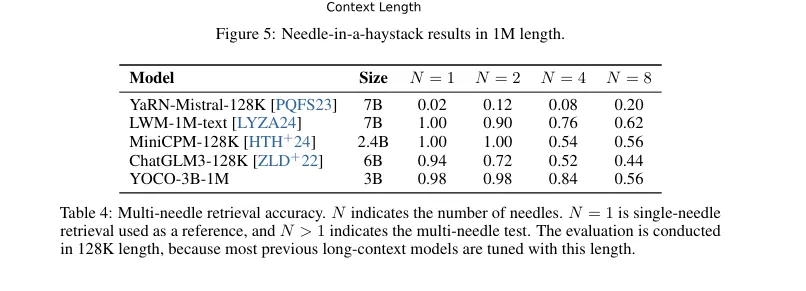
总的说来,YOCO这波操作确实很有看头。它不仅能让大模型”瘦身”,还能保持全局注意力能力,简直是又瘦又聪明。
你对YOCO这种新架构怎么看呢?














暂无评论内容