生成一张从新角度看事物的图片是件很难的事,因为3D场景本身很复杂,而且用来训练模型的多角度图片数据也不够多样。最近,有研究人员把大规模的文本生成图像(T2I)模型和单目深度估计(MDE)结合起来,用来处理一些复杂的自然场景图片。这些方法通常是先通过深度图将图片变形,然后用T2I模型来修补这些变形的图片。不过,这些方法在应对深度图中的噪声和保留图像细节方面还存在问题,尤其是当需要从一个角度变换到另一个角度时。
为了解决这些问题,索尼提出了一种新方法,叫做“单视角生成新视角的语义保留生成变形框架”。这个框架通过增强不同视角之间的注意力,使得T2I模型能够学会何时进行图片的变形,何时生成新的内容。
01 技术原理—
假设你有一张图片和一个你想要的相机角度。我们首先会得到两个东西:一个是这张图片的二维坐标,另一个是这个新角度下的变形坐标。然后,语义保留网络会用这些坐标提取出这张图片的主要特征,而基于这些特征的扩散模型会学着如何把图片变形,生成新的视角。 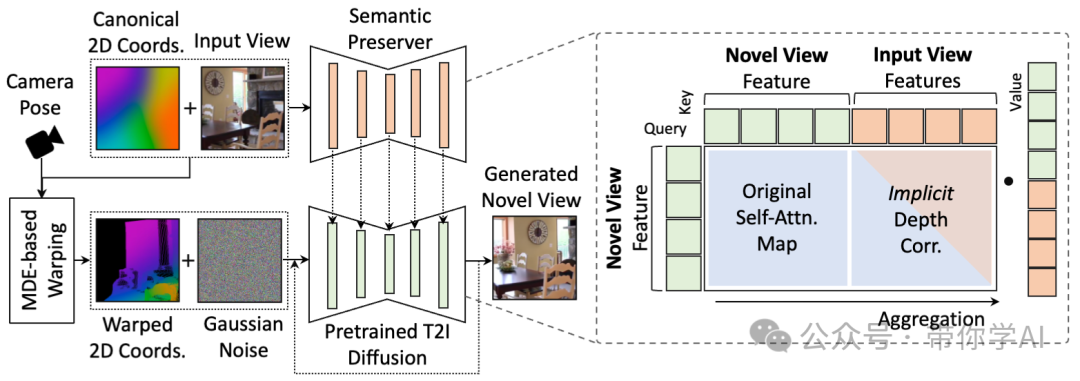 模型仅基于单一输入视图即可生成合理的新视图,从而能够处理域内图像(顶部)和域外图像(底部)。模型可以应用于各种下游任务。例如,给定一张图像,模型会生成 3-4 张新视图图像,然后将它们输入到快速 3DGS 重建器(如InstantSplat )中。然后我们可以在 30 秒内轻松获得 3DGS 场景。
模型仅基于单一输入视图即可生成合理的新视图,从而能够处理域内图像(顶部)和域外图像(底部)。模型可以应用于各种下游任务。例如,给定一张图像,模型会生成 3-4 张新视图图像,然后将它们输入到快速 3DGS 重建器(如InstantSplat )中。然后我们可以在 30 秒内轻松获得 3DGS 场景。 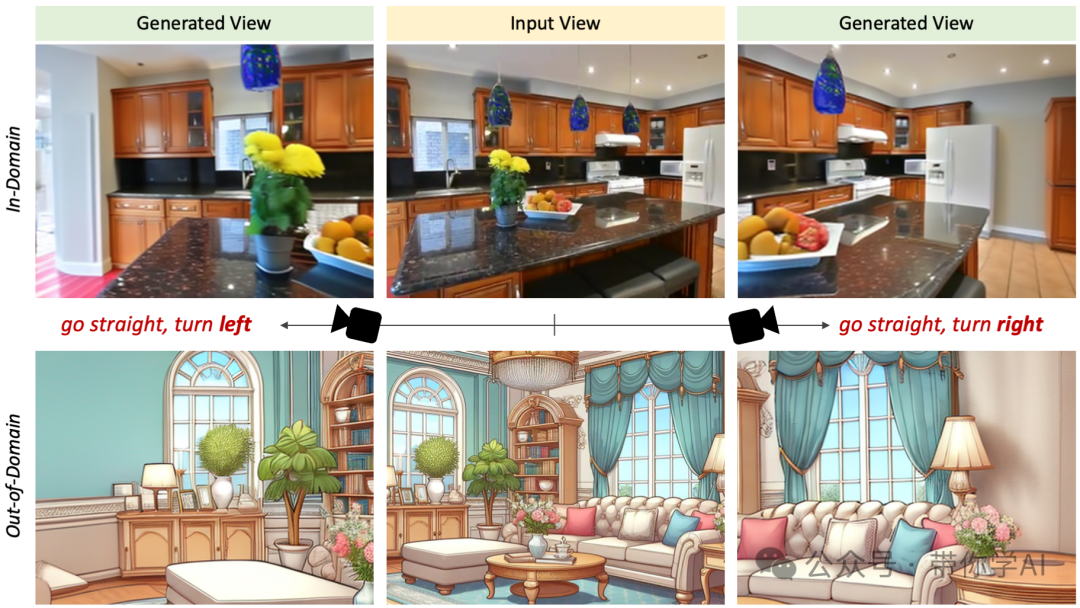 GenWarp引入了一种新方法,其中扩散模型学习以 MDE 深度对应关系为条件隐式进行几何扭曲,而不是直接扭曲像素或特征。模型以在生成过程中交互补偿扭曲不良区域,从而防止通常由显式扭曲引起的伪影。
GenWarp引入了一种新方法,其中扩散模型学习以 MDE 深度对应关系为条件隐式进行几何扭曲,而不是直接扭曲像素或特征。模型以在生成过程中交互补偿扭曲不良区域,从而防止通常由显式扭曲引起的伪影。
 增强的自注意力机制中,原始的自注意力部分更关注需要生成先验的区域,例如遮挡或扭曲不良的区域(顶部),而跨视图注意力部分则关注可以从输入视图可靠扭曲的区域(底部)。通过同时聚合两种注意力,模型可以自然地确定要生成哪些区域以及要扭曲哪些区域。
增强的自注意力机制中,原始的自注意力部分更关注需要生成先验的区域,例如遮挡或扭曲不良的区域(顶部),而跨视图注意力部分则关注可以从输入视图可靠扭曲的区域(底部)。通过同时聚合两种注意力,模型可以自然地确定要生成哪些区域以及要扭曲哪些区域。 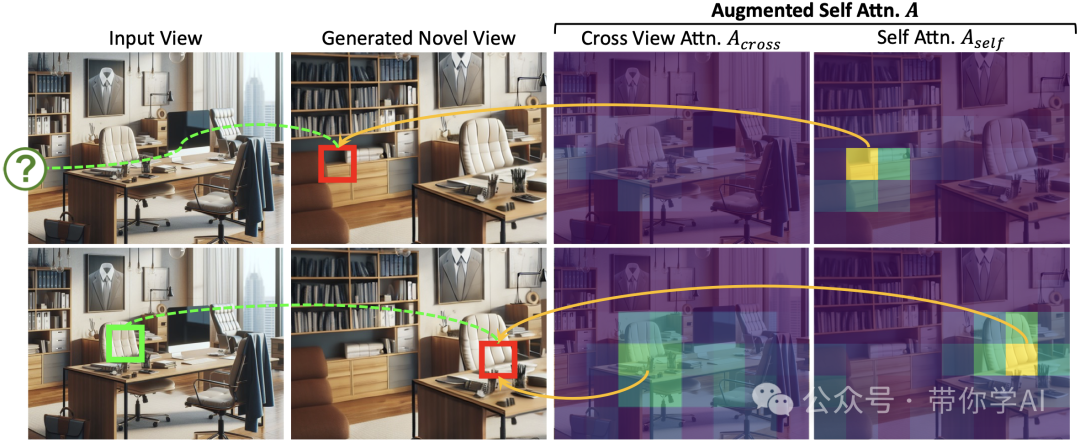 根据输入图像和估计的深度重建的 3D 场景。(中)扭曲的图像。(右)生成的图像。
根据输入图像和估计的深度重建的 3D 场景。(中)扭曲的图像。(右)生成的图像。
模型可以处理来自各个领域的图像,包括室内/室外场景,甚至具有挑战性的相机视点变化的插图。 














暂无评论内容