传统的参考分割任务主要关注无声视觉场景,而忽略了多模态感知和交互在人类体验中不可或缺的作用。Ref-AVS任务旨在根据包含多模态线索的表达来分割视觉域中的对象。此类表达以自然语言形式表达,但富含多模态线索,包括音频和视觉描述。
要准确定位下图中真正演奏乐器的人,仅靠单一的方法是远远不够的,但已有一些方法在多模态分析上取得了进展。例如:视频对象分割(VOS)依赖第一帧标注的掩码指导后续分割,但却过度依赖第一帧;视频对象参考分割(Ref-VOS)用自然语言描述代替掩码,但能力不足;视听分割(AVS)则通过音频定位发声物体,但对不发声的物体无效。Ref-AVS方法通过整合文本、音频和视觉等多个模态之间的关系,更好地适应了复杂的动态视听场景。不仅能轻松找到同时唱歌和弹吉他的人,甚至还能在同一段素材中反复使用这个方法,准确找出发声的吉他。 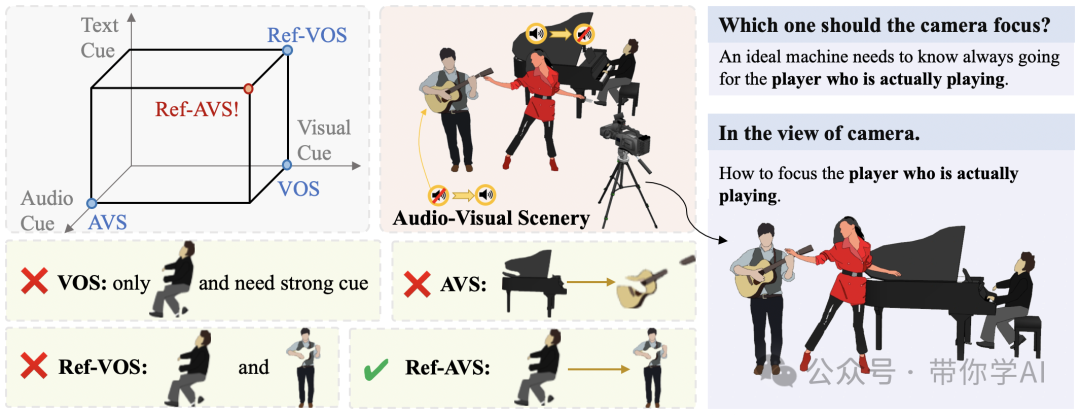
人大和北邮联合发布!多模态感知下的视听分割方法Ref-AVS
01 技术原理—
Ref-AVS的方法 EEMC 会保存之前的记忆,以便更好地理解时间上的变化。不同的模态(比如音频和视觉)会通过特定的标记来清楚地区分。最后,用一种叫交叉注意力的技术,让模型更加高效地处理视觉信息。 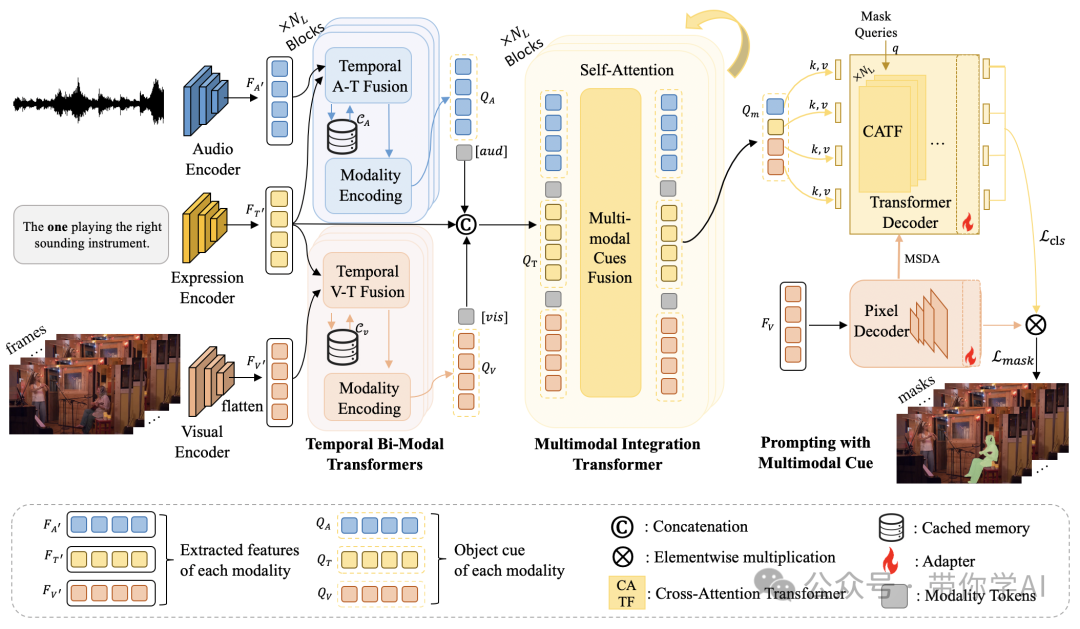 同时,Ref-AVS手动收集 YouTube 视频。具体来说,20 个乐器类别、8 个动物类别、15 个机器类别和 5 个人类类别。注释是使用定制的 GSAI-Labeled 系统收集的。通过结合各种模态表达类型,得到了一个非常多样化的数据集。
同时,Ref-AVS手动收集 YouTube 视频。具体来说,20 个乐器类别、8 个动物类别、15 个机器类别和 5 个人类类别。注释是使用定制的 GSAI-Labeled 系统收集的。通过结合各种模态表达类型,得到了一个非常多样化的数据集。 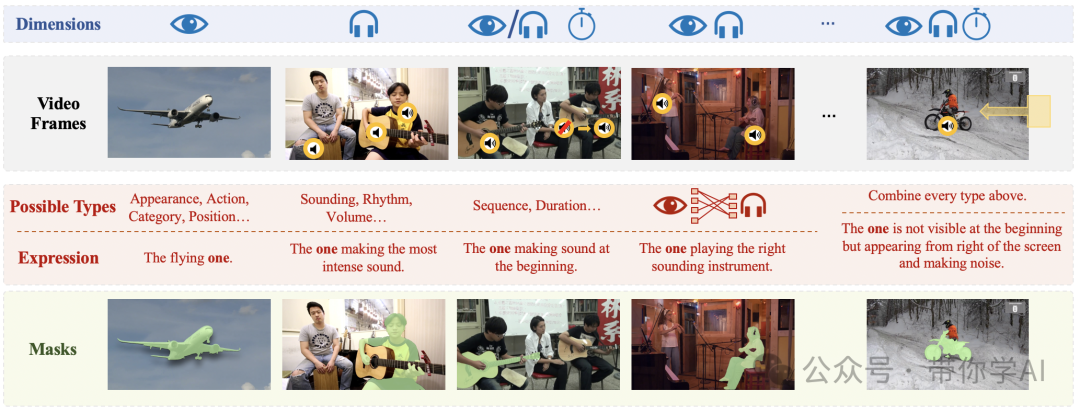 简单来说,Ref-AVS 基准展示了一个从无声到很响的声音变化过程。这个基准包含了多个维度的多模态信息,经过仔细设计,结合了不同的表达方式,确保数据集内容丰富多样。
简单来说,Ref-AVS 基准展示了一个从无声到很响的声音变化过程。这个基准包含了多个维度的多模态信息,经过仔细设计,结合了不同的表达方式,确保数据集内容丰富多样。 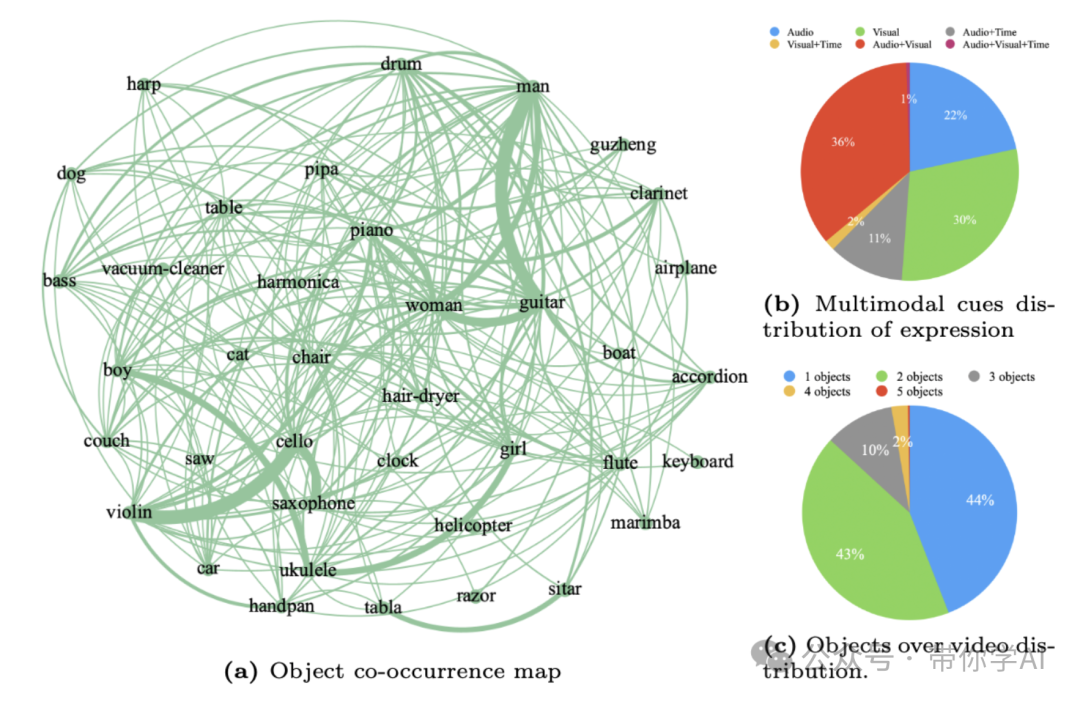
,
人大和北邮联合发布!多模态感知下的视听分割方法Ref-AVS
可视化的方式展示了数据集中对象的共现情况,我们可以观察到涵盖各种类别(如乐器、人物、车辆等)的密集连接网络。丰富的类别组合表明数据集不仅限于一组狭窄的场景,而是涵盖了广泛的现实场景,这些场景中的对象很可能自然地一起出现。 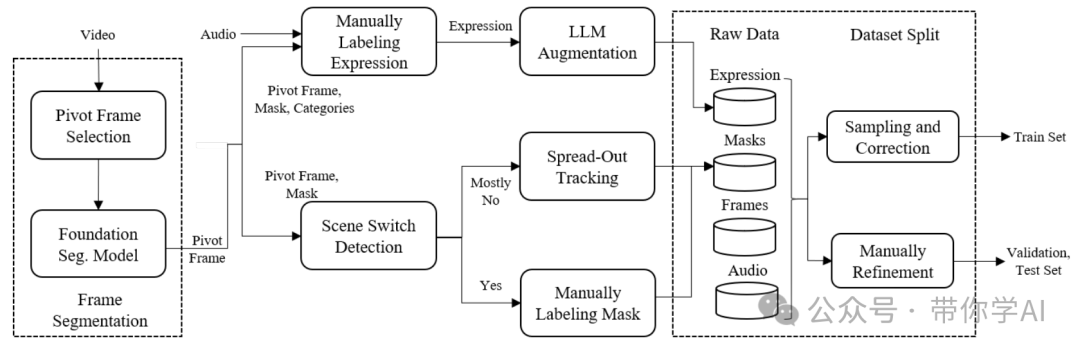 数据集收集流程:这个流程在保证整体过程的高效性和成本效益方面起到了重要作用,帮助获取了高质量的样本。通俗来说,这个数据收集流程帮助更快、更省钱地收集到了高质量的数据样本。在智能监控中,Ref-AVS可以通过结合音频和视觉信息,精确识别并追踪特定人物或物体;在视频编辑中,它能帮助创作者更高效地筛选出需要的片段;
数据集收集流程:这个流程在保证整体过程的高效性和成本效益方面起到了重要作用,帮助获取了高质量的样本。通俗来说,这个数据收集流程帮助更快、更省钱地收集到了高质量的数据样本。在智能监控中,Ref-AVS可以通过结合音频和视觉信息,精确识别并追踪特定人物或物体;在视频编辑中,它能帮助创作者更高效地筛选出需要的片段;














暂无评论内容