理解视频中的人类行为越来越重要,特别是在各种视频数据爆炸式增长的情况下。过去的方法需要先定义好物体的模板,或者只靠单张图片进行分析,但这些方法要么麻烦要么在时间上不太靠谱。德国图宾根大学提出了一种全新的方法InterTrack,不需要提前准备模板,也能追踪人和物体的互动。InterTrack将复杂的四维追踪问题分成两步:第一步是逐帧追踪动作,第二步是优化形状模型。首先,InterTrack利用单一视角的重建方法,虽然结果在时间上有点不连贯,但作为基础足够了。接着,用一个超级高效的自编码器来处理人类动作部分,确保动作在时间上的连贯性。对于物体,设计了一种姿态估计器,能够在物体被遮挡时也能平滑地预测它的旋转。
InterTrack:无需知道物体的全新建模方法,追踪人与物体的互动
01 技术原理—
将 4D 跟踪问题分解为每帧姿势跟踪和规范形状优化。首先应用单视图重建方法来获得时间不一致的每帧交互重建。然后,对于人类,提出了一种有效的自动编码器,直接从每帧重建中预测 SMPL 顶点,引入时间一致的对应关系。对于物体,引入了一个姿势估计器,它利用时间信息来预测遮挡下的平滑物体旋转。为了训练模型,InterTrack提出了一种生成合成交互视频的方法,并合成总共 10 小时的 8.5k 序列视频,具有完整的 3D 地面实况。 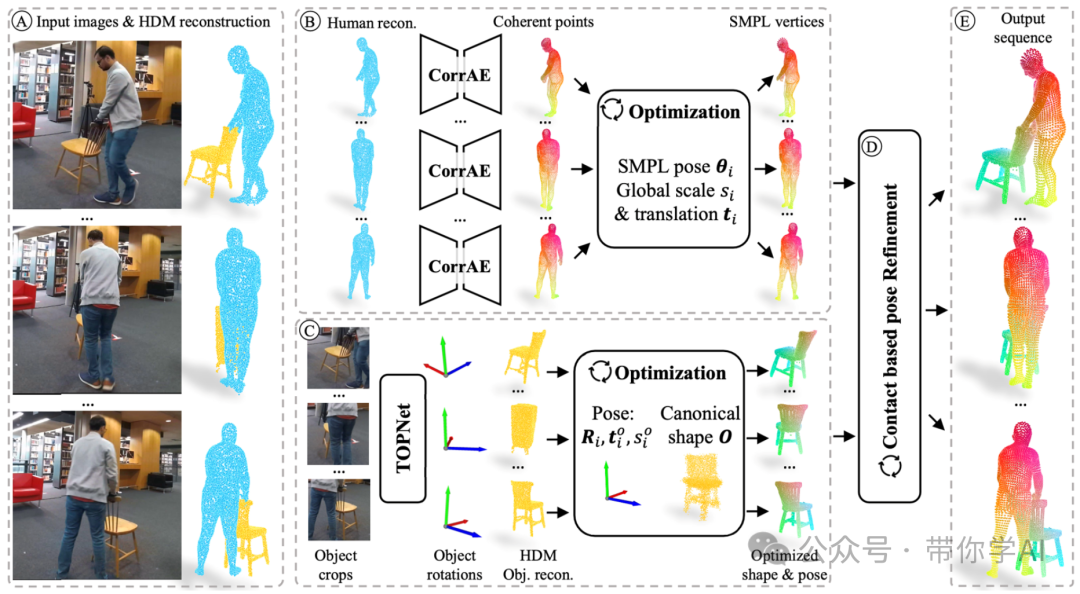 主要思想是将 4D 跟踪问题分解为全局形状优化和每帧姿势跟踪,从而大大减少了解决方案空间。对于人类,使用简单但高效的自动编码器 CorrAE 来获取连贯的人类点,并通过 SMPL 层优化人类。对于物体,使用时间物体姿势估计器 TOPNet 来预测物体旋转,这能够在规范空间中优化常见的物体形状并微调姿势预测。然后,根据接触点联合优化人类和物体以获得一致的跟踪。
主要思想是将 4D 跟踪问题分解为全局形状优化和每帧姿势跟踪,从而大大减少了解决方案空间。对于人类,使用简单但高效的自动编码器 CorrAE 来获取连贯的人类点,并通过 SMPL 层优化人类。对于物体,使用时间物体姿势估计器 TOPNet 来预测物体旋转,这能够在规范空间中优化常见的物体形状并微调姿势预测。然后,根据接触点联合优化人类和物体以获得一致的跟踪。
为了训练能够从视频中估计姿势的模型,InterTrack发明了一种生成互动视频数据的新方法。InterTrack创建了一个名为 ProciGen-Video 的数据集,里面包含了10小时的视频序列,展示了8.5千个人与4.5千种不同物体互动的场景。这个数据集可以用来训练各种基于视频的技术,让它们在实际应用中表现更好。与HDM方法的比较(中间为HDM,右侧为InterTrack),可以看出HDM 在不同帧之间产生不同的形状,而InterTrack的方法可以持续跟踪形状和姿势。














暂无评论内容