Meta RoCE网络
网络拓扑
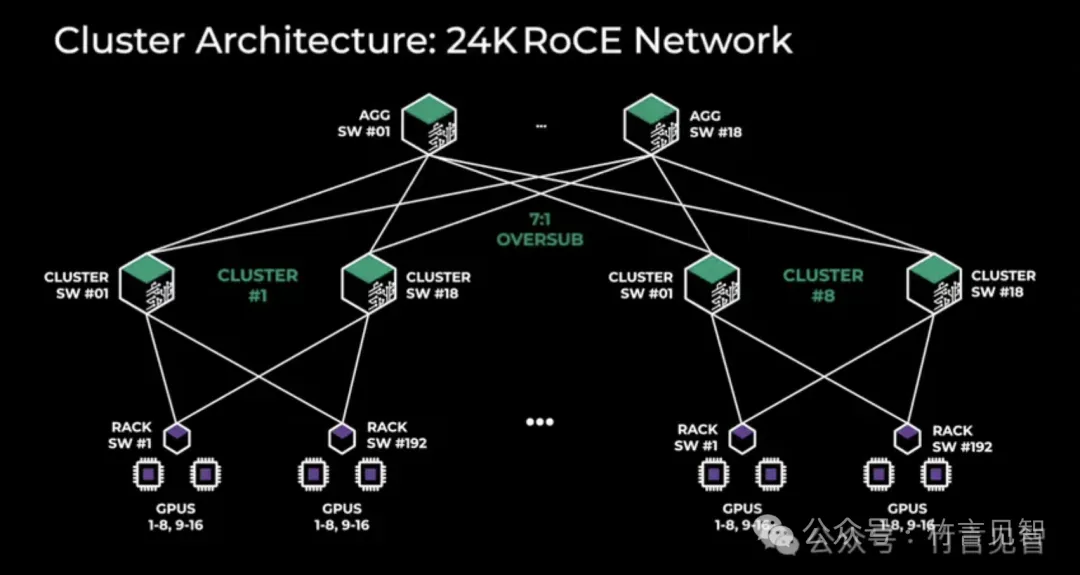
基于RoCE的AI集群由24K个GPU组成,通过一个三层Clos网络连接。
在底层,每个机架有16个GPU分布在两台服务器上,并通过一个Minipack2 ToR交换机连接。
在中层,192个这样的机架通过集群交换机连接,形成一个拥有3,072个GPU的集群,具有完整的双切带宽,确保没有过订阅。
在顶层,同一数据中心大楼内的8个这样的集群通过聚合交换机连接,形成一个24K GPU的集群。
聚合层的网络连接没有保持完整的双切带宽,而是有一个1:7的过订阅比率。LLama3.1模型4D并行算法和训练作业调度程序都针对网络拓扑进行了优化,以达到最小化跨集群的网络通信目的。
路由选择
使用增强ECMP设计和集中式流量工程TE做路由。
拥塞控制
通过receiver-driven流量准入和CTSW上深缓冲区来控制拥塞。
阿里HPN7网络
网络拓扑
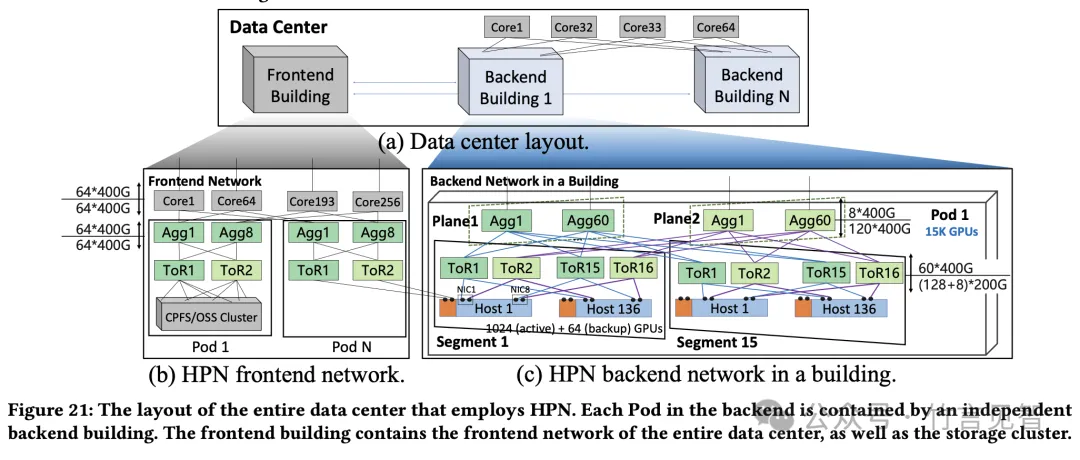
HPN引入了一种两层、双平面架构,而非传统的三层CLOS架构,能够在单个Pod内互联15K个GPU(万级GPU)。每个pod中包含15个segment,每个segment包含1024主+64备张GPU。
每台服务器配备了9个NIC,每个NIC具有2×200Gbps的带宽。这九个NIC中的一个(即图7中的NIC0)连接到前端网络,而其余八个NIC连接到后端网络以承载LLM训练期间的流量。2*8=16个端口可全连接16个ToR交换机。
采用最新的51.2Tbps以太网单芯片交换机,在Tier1中每个交换机配备128个活动+8个备份的200Gbps下行端口和60个上行400Gbps端口,确保了近1:1的超额认购比(实际为1.067:1)。
同时增加core层,连接多个pod形成第三层网络,来增加整体集群容量。
路由选择
通过部署主机-交换机协作系统,确保所有主机保持最新的链路状态并计算正确的不相交路径。
拥塞控制
实现了一个简单而有效的应用层负载均衡方案,以充分利用所有 RDMA 连接。
对于每个连接,HPN 维护一个计数器,记录当前活动的工作队列元素(WQEs)中的总字节数。该计数器揭示了当前连接的拥塞状态:拥塞的连接会减慢工作队列的消耗速度。
百度HPN网络
https://cloud.baidu.com/article/364290
网络拓扑
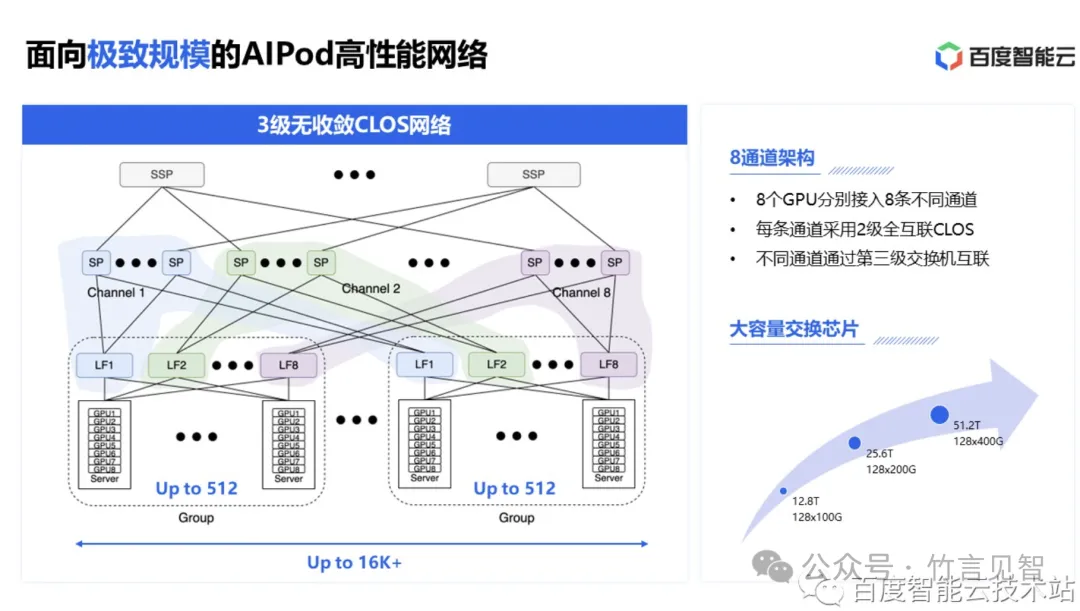
HPN-AIPod 使用 8 导轨架构,3级无收敛(收敛比1:1)CLOS网络。
每个服务器 8 张网卡,然后每张网卡分别连到一个 TOR 汇聚组的 8 个 TOR 上。这样每个汇聚组下最大可有8*8*8=512张GPU。
8 个 Leaf 交换机再往上连入不同的 8 个通道,每个通道内 Spine 交换机和 Leaf 交换机之间做 fullmesh 全互联。这样的一个集群最大可以支持超过 16K GPU。
虽然主要的通信发生在同一个通道内,但总还是会存在跨通道的通信。所以通过 SuperSpine 再把不同的通道的 Spine 交换机连接起来,打通各个通道,进而进一步扩大整体集群容量。
https://mp.weixin.qq.com/s/kOy7f4YB7wZl-6rWkbVXtw
路由选择
联合亲和性调度和DLB动态负载均衡,解决交换机哈希冲突。
腾讯星脉2.0网络
腾讯基于RoCE构建了星脉网络计算架构,星脉网络目前已从1.0升级到2.0架构,搭载全自研的网络设备与AI算力网卡,自研TiTa和TCCL网络协议,支持超10万卡大规模组网。网络通信效率比上一代提升60%,让大模型训练效率提升20%。
网络拓扑
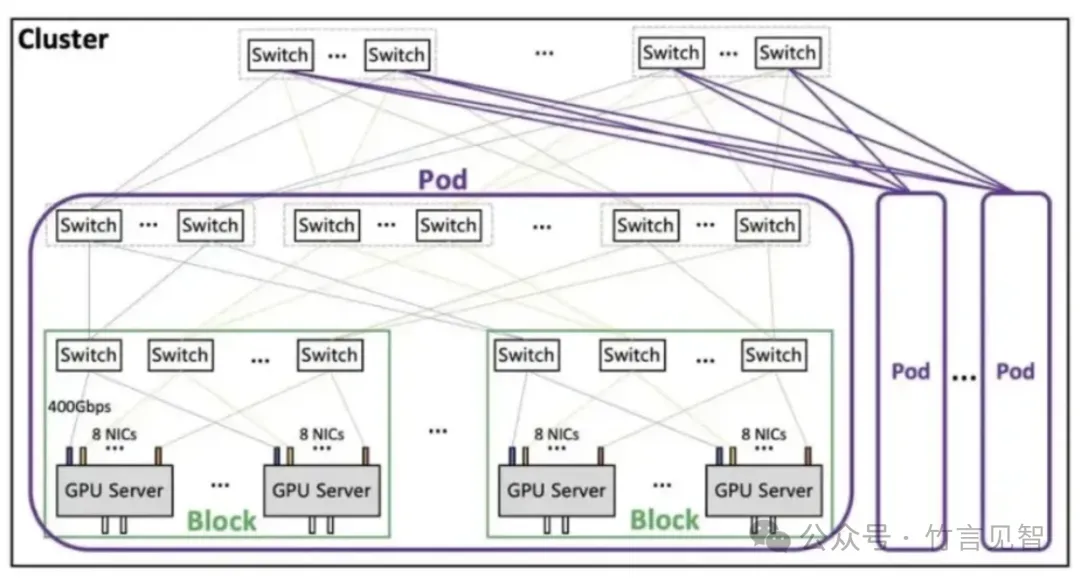
星脉网络采Fat-Tree架构,单集群规模支持1.6万个节点(整体超过10万个GPU)。单个服务器(8个GPU)为一个计算节点,包含8张400Gbps网卡,可提供3.2通信带宽。整体架构分为Block-Pod-Cluster三级。
Block是最小单元,包括256个GPU;
Pod是典型集群规模,包括16-64个Block;
1个Cluster最大支持16个Pod,也就是65536-262144个GPU。
拥塞控制
自研通信协议TiTa,并搭载腾讯独有的主动拥塞控制算法。
TiTa协议2.0从部署在交换机转移到了端侧的网卡上,从原来的被动拥塞算法升级到了更为智能的主动拥塞控制算法,可主动调整数据包发送速率,从而避免网络拥堵;并通过拥堵智能调度,实现网络拥塞快速自愈。
字节megascale集群网络
网络拓扑
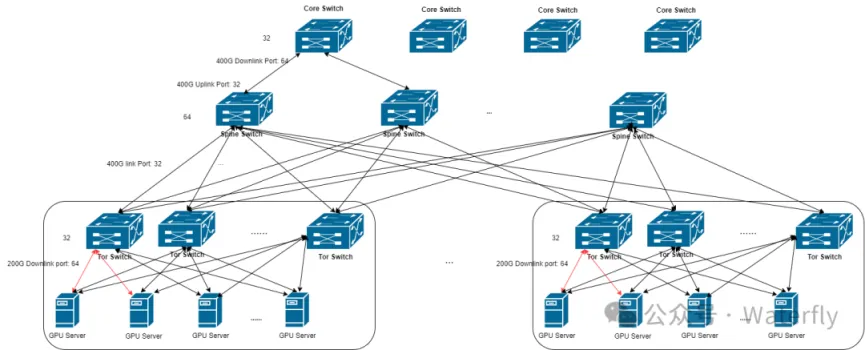
集群包含超10K个GPU,通过一个三层类CLOS网络连接。
数据中心交换机采用Broadcom Tomahawk 4芯片构建,每个Tomahawk芯片的总带宽为25.6Tbps,具有64个400Gbps端口。
每层交换机网络收敛比为1:1,也即32个端口用作下行链路,32个端口用作上行链路。
网络提供了高带宽和小直径。每个节点都可以在有限的跳数内与其他节点通信。
每台服务器上的八个200G网卡以多轨方式连接到八个不同的ToR交换机,形成一组ToR交换机。
ToR交换机一个400G下行链路端口被特定的AOC电缆分割成两个200G下行链路端口。Spine交换机32个端口用于下行链路,Core交换机64个端口用下行链路。
ToR-group,每组8个ToR交换机,支持接入32*2=64个服务器,共计64*8=512张GPU。
Spine-block,包含32个Spine交换机,每个Spine交换机32个端口全连接到每个ToR交换机,即连接到4个ToR-group,所以每个Spine-block下包含4*512 = 2048张GPU。
Core-pod,Core交换机64个端口可以连接64个Spine交换机,即2个Spine-block,所以一个Core-pod可以包含2*2048=4096张GPU。
多格Core-pod通过Core交换机全互联,构建超万卡集群。
路由
精心设计的网络拓扑并调度网络流量以减少ECMP哈希冲突。
交换机级别由于每个上行链路的带宽是下行链路的两倍,降低冲突概率。
有策略地调度训练任务中的数据密集型节点在同一个ToR交换机下运行,显著减少通信所需的交换机跳数的同时,进一步降低了ECMP哈希冲突的概率。
拥塞控制
开发了一种结合了Swift和DCQCN原理的算法,该算法将往返时间(RTT)的精确测量与显式拥塞通知(ECN)的快速拥塞响应能力相结合。提高吞吐量的同时最小化了与PFC相关的拥塞。
零一万物网集群络
网络拓扑
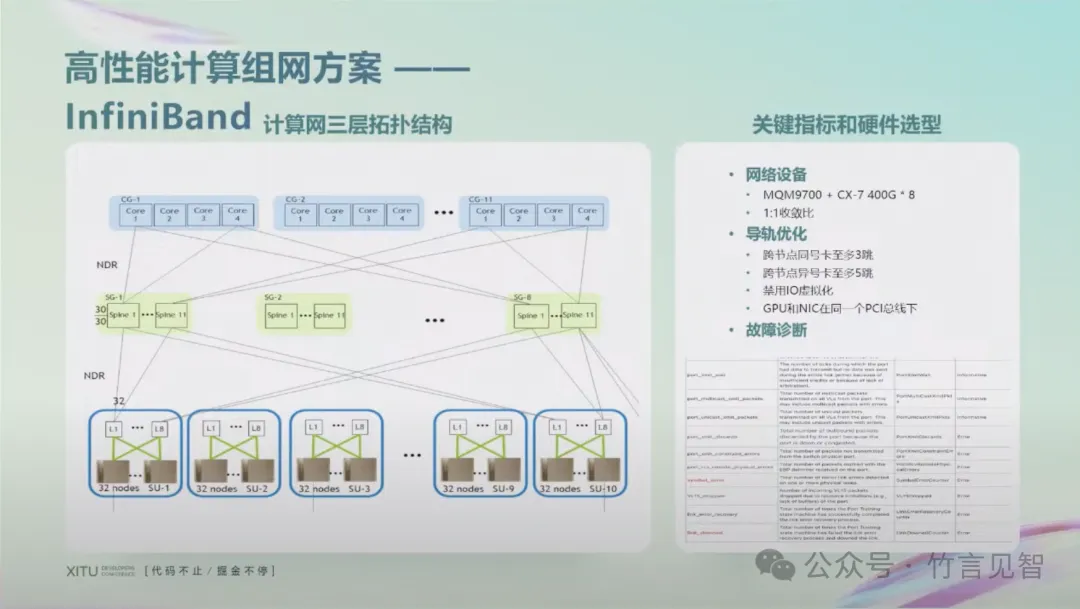
架构基本沿用DGX SuperPod的网络配置,采用IB的三层组网架构,理论上支持64k GPU集群(当前规模千卡级别)。其中leaf-spine网络架构,leaf交换机通过导轨优化连接到上层spine交换机,再连接到core交换机。
采用MQM9700交换机,connectX-7网卡;每台服务器包含8个400Gbps网卡GPU。
同时做了导轨优化,实现了跨节点同号卡至多3跳,跨节点异号卡至多5跳。
具体的SU数量及GPU关系可参考下图。
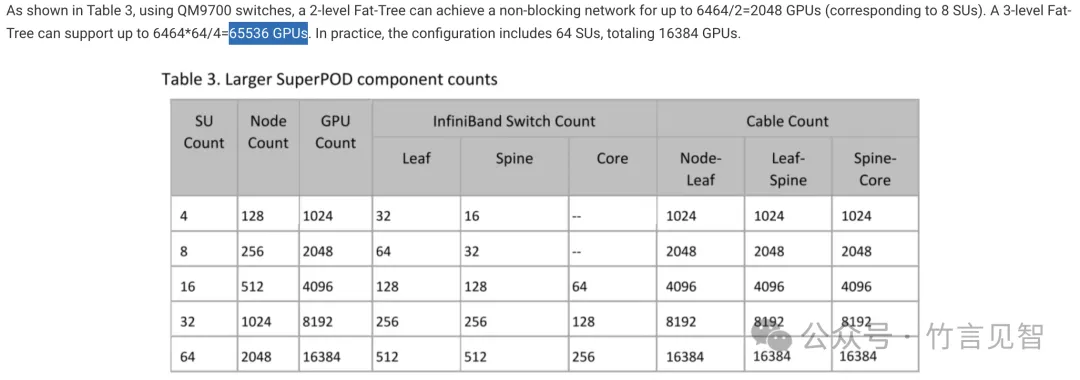
https://www.fibermall.com/blog/large-scale-gpu-clusters.htm#NVIDIA_DGX_SuperPod_%E2%80%93_A100














暂无评论内容