Seed-ASR1是一种基于大型语言模型(LLM)的语音识别模型。Seed-ASR是在音频条件大语言模型(AcLLM)框架上开发的,利用了大型语言模型的强大能力,将连续的语音表示和上下文信息输入到语言模型中。通过分阶段的大规模训练以及语言模型中上下文感知能力的引入,Seed-ASR 在综合评估集上(涵盖多个领域、口音/方言和语言)比传统的端到端模型有了显著提升。
Seed-ASR 具有高识别率、大模型容量、多语言支持、上下文感知和分阶段训练五大特点。通过2000万小时语音和90万小时ASR数据训练,Seed-ASR(CN)和Seed-ASR(ML)在多个数据集上表现优异。其采用了包含20亿参数的音频编码器和数百亿参数的MoE大语言模型,支持普通话、13种方言以及多种语言,并计划扩展至40多种语言。通过整合历史对话和视频编辑等上下文信息,Seed-ASR提升了关键字召回率,增强了多场景下的表现。
《为了提高对对话代理“枫丹”的识别准确性,将其昵称“枫丹”添加到识别提示中作为上下文。然而,如果提示中没有提供相关背景知识,该名字可能会被识别为其他语义合理的同音词。》01 技术原理—
Seed-ASR 在有上下文信息时,会使用指令“有相关上下文,将语音转成文本:”,而没有上下文时,指令则是“将语音转成文本:”。
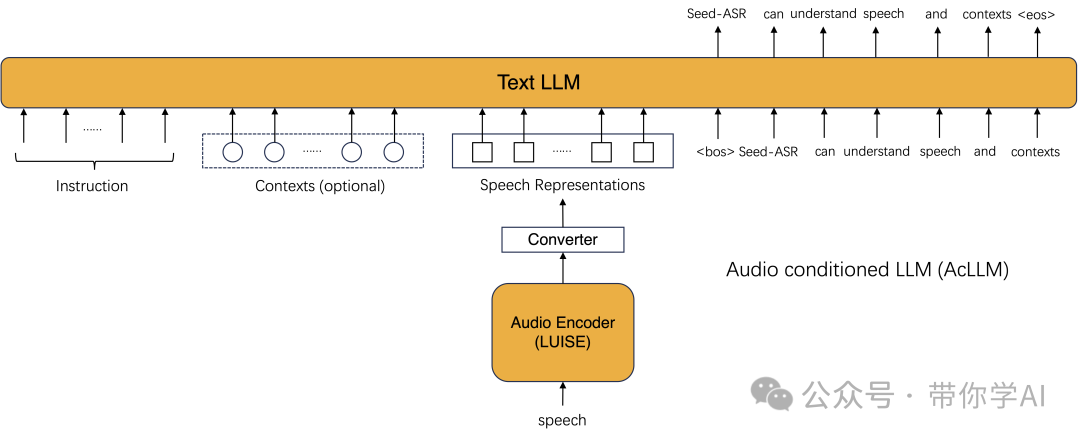
在音频条件大语言模型AcLLM框架内,采用了分阶段训练方法:在监督微调(SFT)阶段,通过大量语音文本对训练来建立映射关系;在上下文SFT阶段,利用少量定制的上下文-语音-文本三元组,引导模型从上下文中捕捉语音线索;最后在强化学习阶段,通过应用MWER标准和一些改进措施进一步增强模型性能。SSL代表自监督学习,SFT代表监督微调,RL代表强化学习。

受基于BERT的语音SSL框架的启发,Seed-ASR开发了音频编码器LUISE(大规模无监督迭代语音编码器),该模型基于一致性,可以捕捉音频信号中的全局和局部结构。
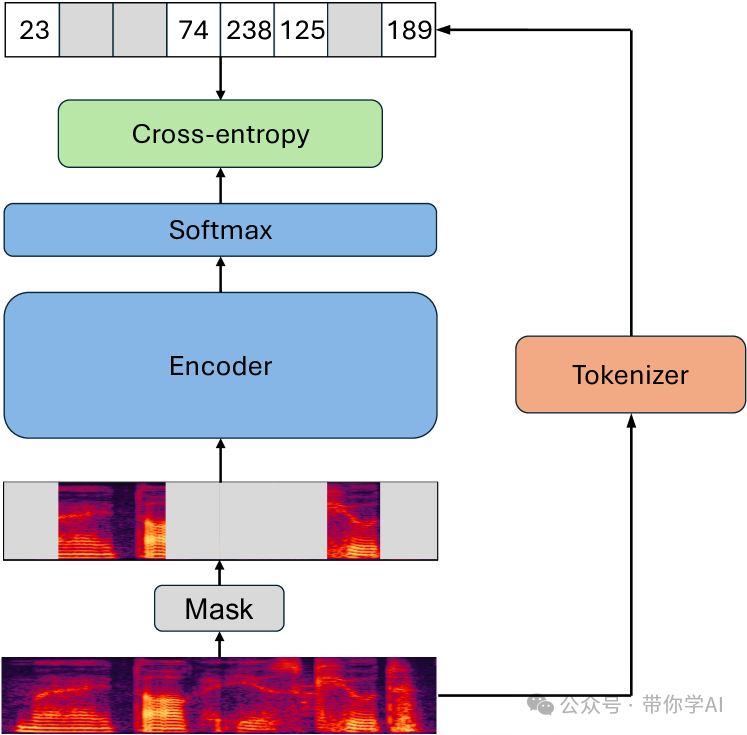
LUISE在大规模无监督数据上进行训练,采用了类似BERT的掩码语言预测学习方式。具体来说,从波形中提取mel-filterbank特征序列,输入分词器模块以获得每帧的离散标签,然后仅对屏蔽帧使用交叉熵准则训练LUISE。训练结束后,去掉softmax层,使用LUISE的编码器部分进行后续的监督微调。02 实际示例—会议场景,提供上下文后修正:
《在邀请Lark会议的与会者时,所有与会者的名字都会作为上下文。当同一名字再次出现时,识别结果会自动修正。》嘈杂噪音识别:

multidomain_sample1,带你学AI,10秒
方言识别:

cantonese_dialect_sample,带你学AI,14秒
多人说话识别:

multidomain_sample5,带你学AI,19秒
外语识别:















暂无评论内容