
Photo by Kaushik Panchal on Unsplash
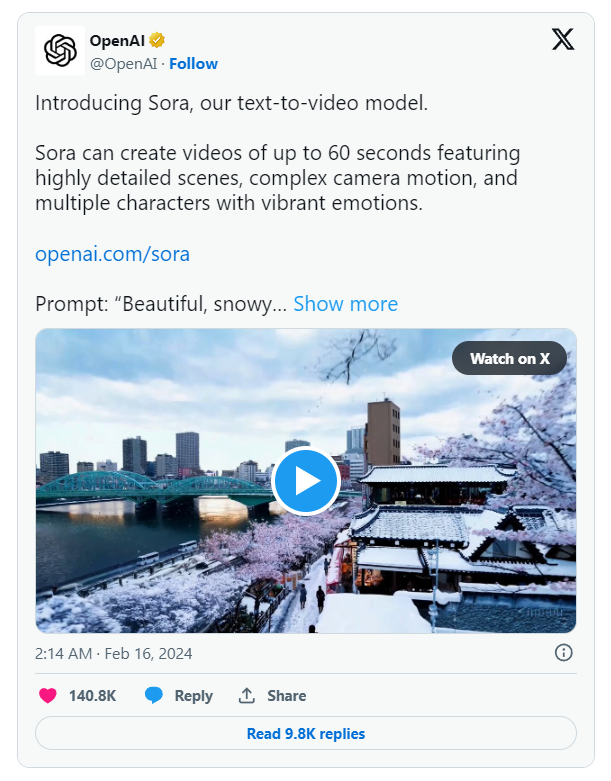
2024 年 2 月 15 日,曾在 2022 年底发布 ChatGPT 惊艳世界的 OpenAI,再次凭借 Sora 的亮相震惊世界。不可否认,这项能够根据文字提示词(text prompt)制作长达一分钟视频的技术必将是迈向 AGI 的又一座里程碑。
在这篇博文中,我将根据 OpenAI 发布的技术报告,介绍这项惊人技术背后的基本研究方法和研究内容。
顺便提一下,“Sora”在日语中是“天空”的意思。虽然官方尚未公布这一命名是何用意,但鉴于 OpenAI 发布的推文中有一段以东京为主题的视频,因此可以推测这个猜测是比较合理的。
OpenAI 通过 X 向全世界展示Sora
目录
01 Sora 的简单介绍
02 它背后的相关技术和相关研究有哪些?
03 这些研究基础加上OpenAI的努力共同造就了 Sora
04 展望 Sora 的未来
01
Sora 的简单介绍
Sora 是由 OpenAI 开发的一款 text-to-video (文生视频)转换模型,其能力和应用范围指引了现代AI技术的新发展方向。该模型不仅限于能够生成几秒钟的视频,甚至可以创建长达一分钟的视频,在保持高质量的同时忠实地满足用户的指令。它仿佛能够将大家的梦想变成现实。

OpenAI Sora 生成的内容演示
根据现实世界生成复杂场景
Sora 可以理解 Prompt 中描述的元素在物理世界中存在形式和运作方式(exist and operate)。这使得该模型能够准确地表现用户期望在视频中出现的动作和行为。例如,它可以逼真地再现人奔跑的景象或自然现象的变化。此外,它还能精确再现多个角色的细节、动作类型以及主体和背景的具体细节。
以往,使用生成式人工智能进行视频创作面临着一个艰巨挑战,即如何在不同场景之间保持一致性和可再现性。这是因为,在单独生成每个场景或每一帧时,要完全理解之前的上下文和细节,并将其适当地继承到下一个场景中是一项极其艰巨的挑战。然而,该模型通过将 “对带有视觉上下文的语言的深刻理解” 和 “对 prompt 的准确解读” 相结合,保证了叙事的一致性。它还能从给定的 prompt 中捕捉人物的情绪和个性特征,并将其描绘成视频中富有表现力的角色。
The post by Bill Peebles (OpenAI) via X
02
它背后的相关技术和相关研究有哪些?
Photo by Markus Spiske on Unsplash
Sora 的研究建立在先前图像数据生成模型研究的基础上。之前的研究采用了多种方法,如递归网络(recurrent networks)、生成对抗网络(GANs)、自回归Transformers和扩散模型,但通常专注于某些单一类别的视觉数据、较短的视频或固定分辨率的视频。Sora 超越了这些限制,并且在生成视频的持续时间、长宽比和尺寸上得到了显著改进。在本节中,我将介绍支持这些改进的核心技术。
2.1 Transformer
Vaswani et al. (2017), “Attention is all you need.”
Transformer是一种神经网络架构,它彻底改变了自然语言处理(NLP)领域。它由 Vaswani 等人于 2017 年首次提出。该模型极大地克服了传统递归神经网络(RNN)和卷积神经网络(CNN)存在的短板,作为一种创新方法支持着当今的各种突破性技术。
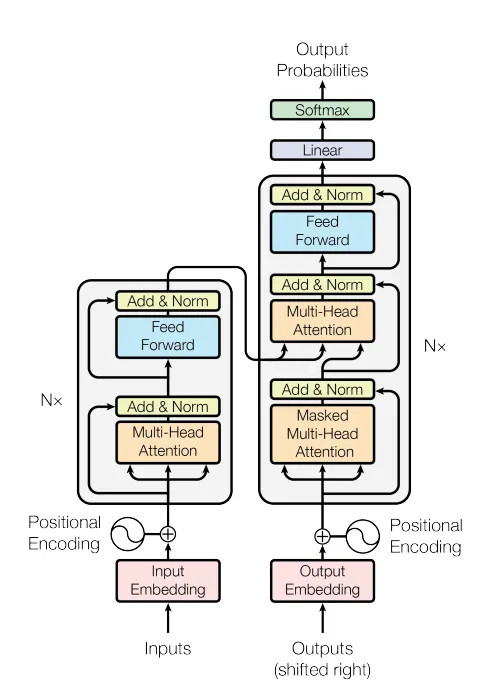
Transformer 模型架构|Vaswani et al. (2017)
RNN 存在的问题:
- 长期依赖(long-term dependencies)问题:尽管 RNN 在理论上可以通过时间传递信息,但在实践中往往难以捕捉长时间跨度的依赖关系。
- 并行处理存在限制:由于 RNN 的每一步计算都依赖于前一步的输出,因此必须进行顺序处理(例如,按顺序逐个处理文本中的单词或句子),从而无法利用现代计算机体系结构提供的并行处理优势。这导致在大型数据集上进行训练效率低下。
CNN 存在的问题:
- 固定的感受野大小(receptive field size):虽然 CNN 擅长提取局部特征,但其固定的感受野大小限制了其在整个上下文中捕捉长距离依赖关系(long-distance dependencies)的能力。
- 难以模拟自然语言的层次结构:使用CNN直接为语言的层次结构建模极具挑战性,可能不足以实现深层次的上下文理解。
Transformer 的新特性:
- 注意力机制:使得模型能够直接建模序列中任意位置之间的依赖关系,从而直接捕捉长距离依赖和广泛的上下文。
- 能够支持并行处理:由于输入数据是作为一个整体一次性处理的,因此实现了计算的高度并行化,大大加快了在大型数据集上的训练速度。
- 可变的感受野(receptive field):注意力机制使得模型能够根据需要动态调整“感受野”的大小。这意味着模型在处理某些任务或数据时,可以自然地将注意力集中在局部信息上,而在其他情况下,则可以考虑更广泛的上下文。
有关 Transformer 更详细的技术解释,请参阅以下链接:
https://towardsdatascience.com/transformers-141e32e69591
2.2 Vision Transformer (ViT)
Dosovitskiy, et al. (2020), “An image is worth 16×16 words: Transformers for image recognition at scale.”
在这项研究中,颠覆自然语言处理(NLP)的 Transformer 原理被应用于图像识别中,为视觉模型开辟了新的方向。
Token 和 Patch
在原始的 Transformer 论文中,token 主要代表单词或句子的一部分,分析这些 token 之间的关系可以深入理解句子的含义。在这项研究中,为了将 token 的概念应用到视觉数据中,图像被划分成了 16×16 的小块(patch),并且每个 patch 都被视为 Transformer 中的一个“token”。这种方法使得模型能够学习到每个 patch 在整个图像中的关系,从而能够基于此识别和理解整个图像。它超越了传统 CNN 模型在图像识别中使用的固定感受野大小的限制,能够灵活捕捉图像中的任何位置关系。
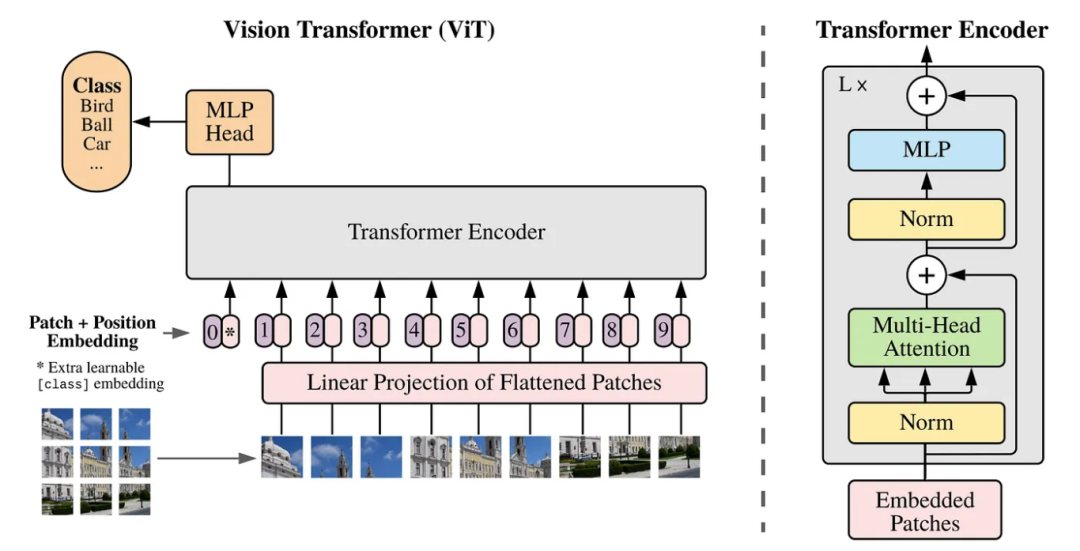
ViT 模型概览|Dosovitskiy, et al. (2020)
有关 Vision Transformer (ViT) 更详细的技术解释,请参阅以下链接:
https://machinelearningmastery.com/the-vision-transformer-model/
2.3 Video Vision Transformer (ViViT)
Arnab, et al. (2021), “Vivit: A video vision transformer.”
ViViT 进一步扩展了 Vision Transformer 的概念,将其应用到视频的多维数据上。视频数据更加复杂,因为它既包含静态图像信息(空间元素),又包含随时间变化的动态信息(时间元素)。ViViT 将视频分解为 patch ,并将其视为 Transformer 模型中的 token。引入 patch 后,ViViT 能够同时捕捉视频中的静态和动态元素,并对它们之间的复杂关系进行建模。
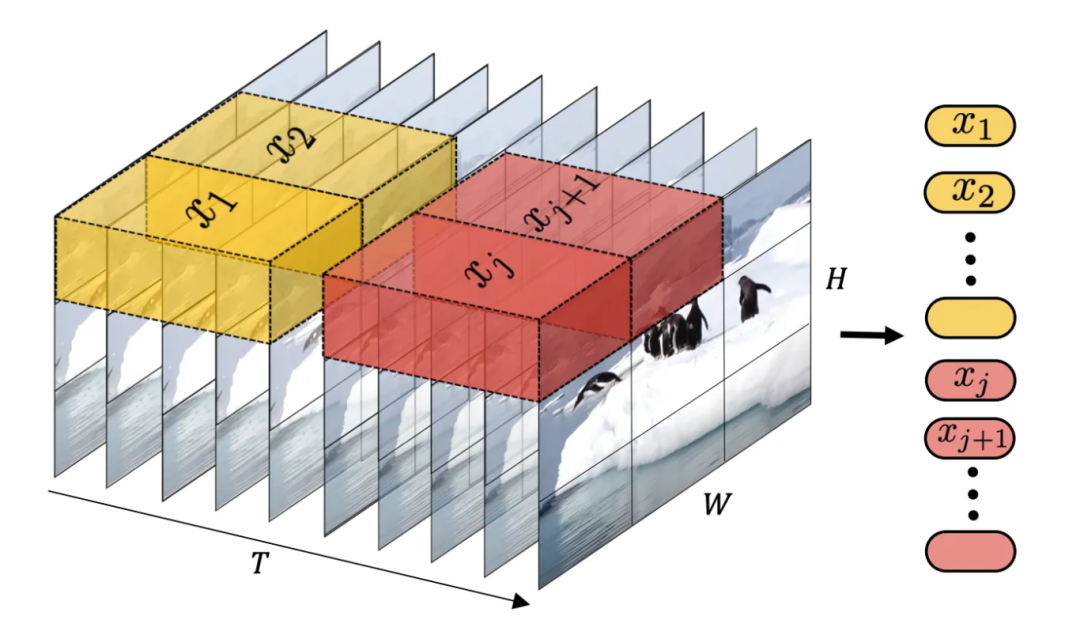
Tubelet (时空输入量) 嵌入图像 |Arnab, et al. (2021)
有关 ViViT 的更多详细技术说明,请参阅以下链接:
https://medium.com/aiguys/vivit-video-vision-transformer-648a5fff68a4
2.4 Masked Autoencoders (MAE) 带有掩码的自编码器
He, et al. (2022), “Masked autoencoders are scalable vision learners.”
这项研究通过使用一种被称为带有掩码的自编码器(Masked Autoencoder)的自监督预训练方法,显著改善了传统上与高维度和海量信息相关的大型数据集训练中存在的计算成本高昂和低效率问题。
具体来说,通过对输入图像的部分内容进行掩码处理,网络被训练来预测隐藏部分的信息,从而更有效地学习图像中的重要特征和结构,并获得丰富的视觉数据表征。这个过程使得数据的压缩(compression )和表征学习(representation learning)更加高效,降低了计算成本,并增强了不同类型的视觉数据以及视觉任务的多样性。
这项研究的方法还与 BERT(Bidirectional Encoder Representations from Transformers)等语言模型的演变密切相关。虽然 BERT 通过 Masked Language Modeling(MLM)实现了对文本数据的深度上下文理解,但 He 等人则将类似的掩码技术应用于视觉数据,实现了对图像的更深层次理解和表示。
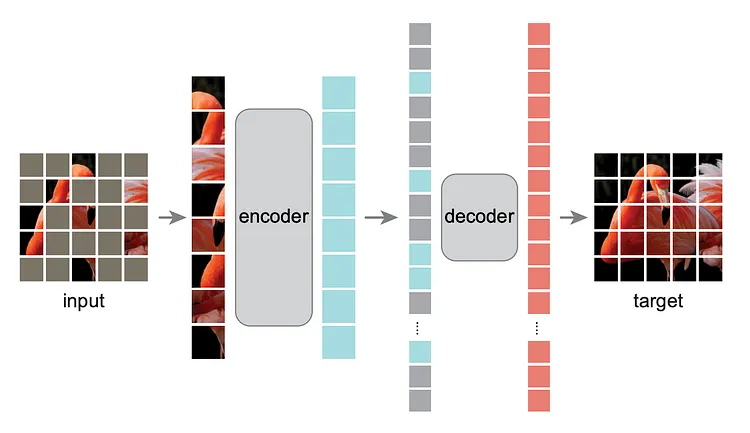
Masked Autoencoders|He, et al. (2022)
有关 MAE 的更多详细技术说明,请参阅以下链接:
https://towardsdatascience.com/paper-explained-masked-autoencoders-are-scalable-vision-learners-9dea5c5c91f0
2.5 Native Resolution Vision Transformer (NaViT)
Dehghani, et al. (2023), “Patch n’Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.”
本研究提出了Native Resolution ViTransformer(NaViT),该模型旨在进一步扩展 Vision Transformer(ViT)的适用性,使其适用于任何长宽比或分辨率的图像。
传统 ViT 面临的挑战
Vision Transformer 引入了一种开创性的方法,通过将图像划分为固定大小的 patches ,并将这些 patches 视为 tokens ,将 transformer 模型应用于图像识别任务。然而,这种方法假设模型针对特定分辨率或长宽比进行了针对性的优化,因此对于不同尺寸或形状的图像,需要对模型进行调整。这是一个比较大的限制,因为现实世界中的应用通常需要处理各种尺寸和长宽比的图像。
NaViT 的创新
NaViT 可高效处理任何长宽比或分辨率的图像,允许它们直接输入模型而无需事先调整。Sora 也将这种灵活性应用于视频场景,通过无缝处理各种尺寸和形状的视频和图像,大大提高了模型的灵活性和适应性。
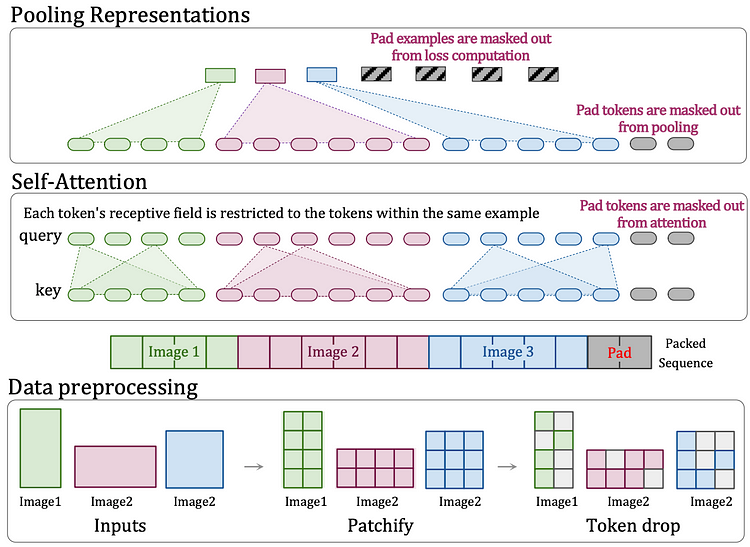
Dehghani, et al. (2023)
2.6 Diffusion Models
Sohl-Dickstein, et al. (2015), “Deep unsupervised learning using nonequilibrium thermodynamics.”
除了 Transformer,扩散模型也是支持 Sora 的骨干技术。这项研究为扩散模型奠定了理论基础,扩散模型是一种利用非平衡热力学的深度学习模型。扩散模型引入了扩散过程的概念,该过程从随机噪声(没有任何模式(pattern)的数据)开始,逐渐去除噪声,从而创建与实际图像或视频相似的数据。
例如,想象一下,一开始只有随机的点,然后逐渐变成美丽风景或人物的视频。这种方法后来被应用于图像和声音等复杂数据的生成,促进了高质量生成模型的发展。

去噪过程的图像|图片来源:OpenAI
Ho et al. (2020), “Denoising diffusion probabilistic models.”
Nichol and Dhariwal (2021), “Improved denoising diffusion probabilistic models.”
在 Sohl-Dickstein 等人(2015)提出的理论框架基础上,开发出了被称为 Denoising Diffusion Probabilistic Models(DDPM)的实用数据生成模型。这种模型在高质量图像生成领域取得了特别显著的成果,证明了扩散模型的有效性。
扩散模型对 Sora 的影响
通常情况下,要训练机器学习模型,需要大量标注数据(比如,告诉模型“这是一张猫的图像”)。然而,扩散模型也可以从未被标注的数据中学习,使其能够利用互联网上大量的视觉内容来生成各种类型的视频。换句话说,Sora 可以通过观察不同的视频和图像,学习到“什么是一个正常视频的样子”。
有关 Diffusion Models 的更多详细技术说明,请参阅以下链接:
https://towardsdatascience.com/diffusion-models-made-easy-8414298ce4da
https://towardsdatascience.com/understanding-the-denoising-diffusion-probabilistic-model-the-socratic-way-445c1bdc5756
2.7 Latent Diffusion Models
Rombach, et al. (2022), “High-resolution image synthesis with latent diffusion models.”
这项研究为利用扩散模型(diffusion models)合成高分辨率图像这一领域做出了重大贡献。它提出了一种方法,与直接生成高分辨率图像相比,该方法通过利用隐空间(latent space)中的扩散模型,在保证质量的前提下大大降低了计算成本。换句话说,它通过对在隐空间(一个容纳图像压缩表征的低维空间)中表示的数据进行编码并引入扩散过程,可以用更少的计算资源实现目标,而不是直接操作图像。
Sora 将这一技术应用于视频数据,将视频的时间+空间数据压缩到较低维度的隐空间,然后将其分解为时空碎片(spatiotemporal patches)。这种高效的隐空间数据处理和生成能力,在使 Sora 能够更快地生成更高质量的视觉内容方面发挥了至关重要的作用。
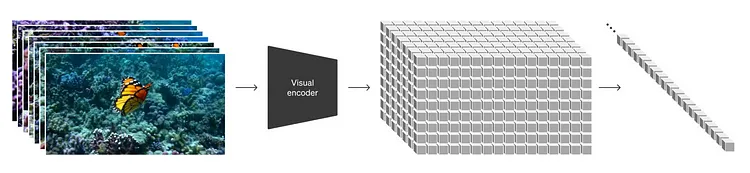
Image of visual encoding|Image Credit (OpenAI)
有关 Latent Diffusion Models 的更多详细技术说明,请参阅以下链接:
https://towardsdatascience.com/paper-explained-high-resolution-image-synthesis-with-latent-diffusion-models-f372f7636d42
2.8 Diffusion Transformer (DiT)
Peebles and Xie. (2023), “Scalable diffusion models with transformers.”
这项研究可能是实现 Sora 最关键的部分。正如 OpenAI 发布的技术报告所述,Sora 采用的不是普通的 transformer ,而是 diffusion transformer(DiT)。
Importantly, Sora is a diffusion transformer. (via OpenAI Sora technical report)
这项研究引入了一种新的模型,用 Transformer 结构替代了扩散模型中常用的 U-net 组件。这种结构通过 Transformer 对 latent patches 的操作实现 Latent Diffusion Model。这种方法能够更高效地处理image patches,从而在有效利用计算资源的同时生成高质量的图像。与 2022 年 Stability AI 宣布的 Stable Diffusion 不同,引入这种 Transformer 被认为有助于更自然地生成视频。
Diffusion Transformers生成的图像|Peebles and Xie. (2023)
此外,值得注意的是,他们的验证结果证明了 DiT 具备可扩展性,为 Sora 的实现做出了重大贡献。具备可扩展性意味着模型的性能能够随着 Transformer 的深度/宽度(使模型更复杂)或输入 token 数量的增加而提高。
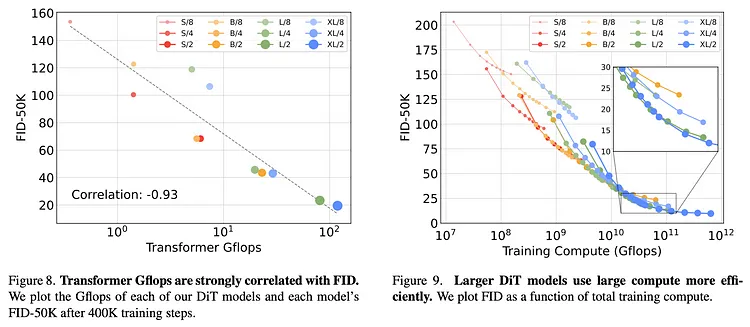
Diffusion Transformers 的可扩展性|Peebles and Xie. (2023)
- Gflops(计算性能):计算机计算速度的度量单位,相当于每秒十亿次浮点运算。在本文中,网络复杂度(network complexity)通过 Gflops 进行衡量。
- FID(Fréchet Inception Distance):这是图像生成的评估指标之一,数值越小表示准确性越高。它通过测量生成图像和真实图像的特征向量之间的距离来定量评估生成图像的质量。
Kaplan 等人(2020)和 Brown 等人(2020)已经证实,在自然语言处理领域已经观察到了这一点(译者注:此处应当指的是“存在可扩展性”),这也是支持 ChatGPT 创新成功背后的关键特性。
Kaplan et al. (2020), “Scaling Laws for Neural Language Models.”
Brown, et al. (2020), “Language models are few-shot learners.”
与传统的扩散模型(diffusion models)相比,由于 Transformer 的优势,它能以更低的计算成本生成高质量的图像,而这一显著特点表明,使用更多的计算资源甚至可以生成更高质量的图像。Sora 将这项技术应用于视频生成。
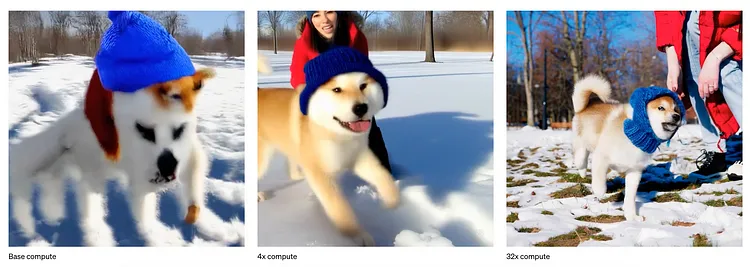
视频生成的可扩展性|Image Credit (OpenAI)
有关 DiT 的更多详细技术说明,请参阅以下链接:
https://youtu.be/eTBG17LANcI
03
这些研究基础加上OpenAI的努力共同造就了 Sora
3.1 可变的视频时长、分辨率、长宽比
主要得益于NaViT,Sora能够生成widescreen 1920x1080p视频、vertical 1080×1920视频以及介于两者之间的所有视频。这意味着它可以为各种设备类型创建任何分辨率的视觉内容。
3.2 使用图像和视频作为 Prompt
目前,Sora 以 text-to-video 的格式实现视频生成,即通过文本提示词给出指令生成视频。不过,从前面的研究中不难看出,也可以使用现有的图片或视频作为输入,而不仅仅是文字。这样,Sora 就可以将图像制作成动画,或将现有视频的过去或未来想象成视觉内容并输出。
3.3 3D consistency
虽然不清楚上述研究如何直接参与其中,帮助实现这一特性。但 Sora 可以生成具有dynamic camera motion效果(译者注:dynamic camera motion 表明视频不是静止不动的,而是随着时间变化而移动、旋转或改变视角。)的视频。随着“摄像机”的移动和旋转,人物和场景元素能够在三维空间中保持一致地移动。
04
展望Sora的未来
这篇博文详细介绍了OpenAI用于生成视频的通用视觉模型 Sora 背后的技术。一旦 Sora 能够向公众开放,让更多人使用,必将在全球范围内产生更加重大的影响。
这一突破所带来的影响预计将涵盖视频创作的各个方面,但据预测,Sora 可能在视频领域扎根后继续进军三维建模领域。届时,不仅对视频创作者产生影响,就连虚拟空间(如元宇宙)中的视觉效果制作也能很快由人工智能轻松生成。
下图已经暗示了这种情况未来可能会出现:
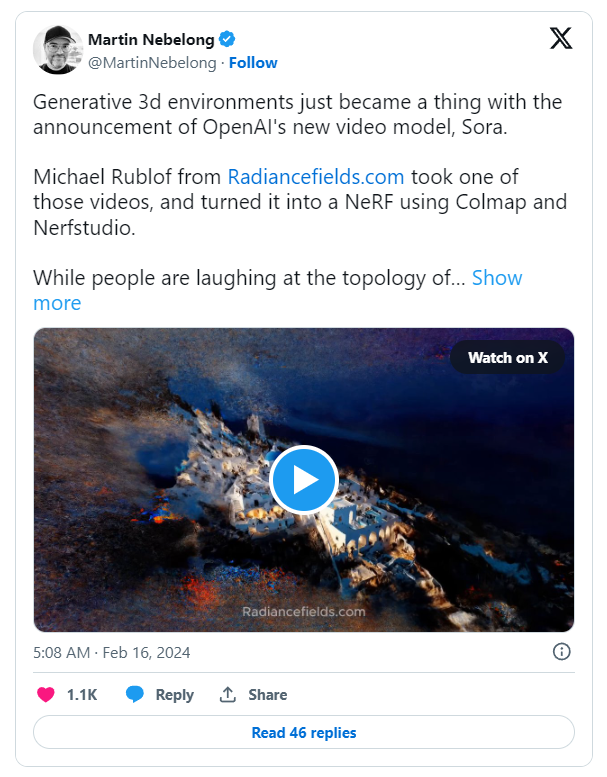
Martin Nebelong 通过 X 发布的与 Micael Rublof 产品相关的帖子
目前,Sora被部分人认为“仅仅”是一个视频生成模型,但Nvidia的Jim Fan暗示它可能是一个数据驱动的物理引擎。人工智能有可能从大量真实世界的视频和(虽然没有明确提到)需要考虑物理行为的视频(如虚幻引擎中的视频)中理解物理规律和现象。如果是这样,那么在不久的将来出现 text-to-3D 模型的可能性也是非常高的。
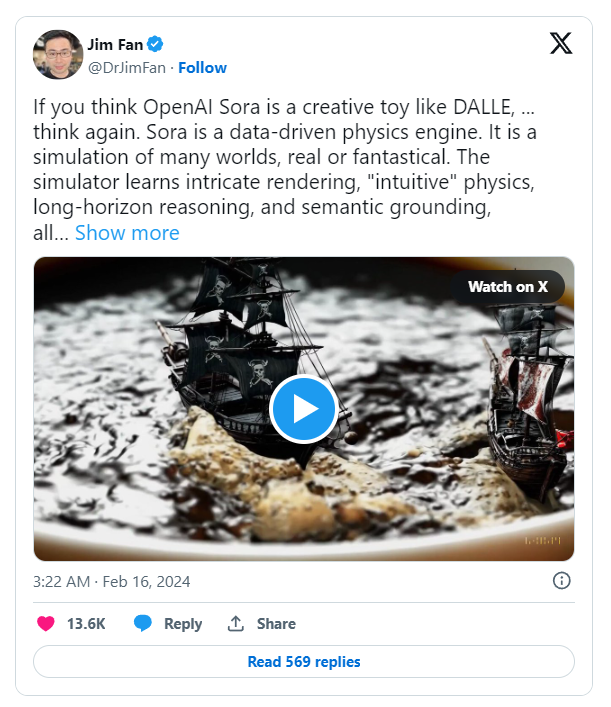
Jim Fan’s intriguing post via X
Thanks for reading!
END

Photo by Kaushik Panchal on Unsplash
2024 年 2 月 15 日,曾在 2022 年底发布 ChatGPT 惊艳世界的 OpenAI,再次凭借 Sora 的亮相震惊世界。不可否认,这项能够根据文字提示词(text prompt)制作长达一分钟视频的技术必将是迈向 AGI 的又一座里程碑。
在这篇博文中,我将根据 OpenAI 发布的技术报告,介绍这项惊人技术背后的基本研究方法和研究内容。
顺便提一下,“Sora”在日语中是“天空”的意思。虽然官方尚未公布这一命名是何用意,但鉴于 OpenAI 发布的推文中有一段以东京为主题的视频,因此可以推测这个猜测是比较合理的。
OpenAI 通过 X 向全世界展示Sora
目录
01 Sora 的简单介绍
02 它背后的相关技术和相关研究有哪些?
03 这些研究基础加上OpenAI的努力共同造就了 Sora
04 展望 Sora 的未来
01
Sora 的简单介绍
Sora 是由 OpenAI 开发的一款 text-to-video (文生视频)转换模型,其能力和应用范围指引了现代AI技术的新发展方向。该模型不仅限于能够生成几秒钟的视频,甚至可以创建长达一分钟的视频,在保持高质量的同时忠实地满足用户的指令。它仿佛能够将大家的梦想变成现实。
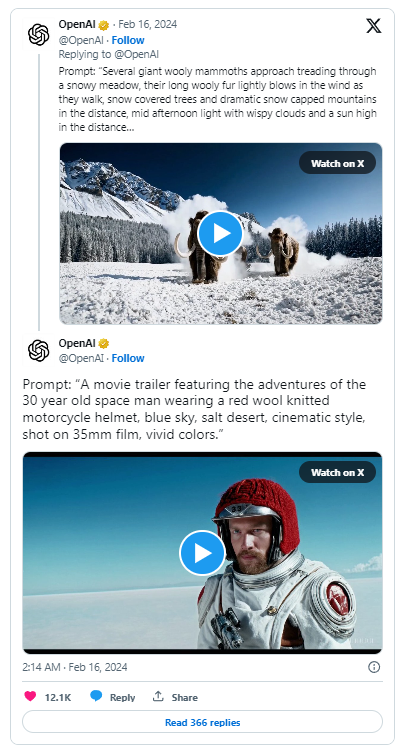
OpenAI Sora 生成的内容演示
根据现实世界生成复杂场景
Sora 可以理解 Prompt 中描述的元素在物理世界中存在形式和运作方式(exist and operate)。这使得该模型能够准确地表现用户期望在视频中出现的动作和行为。例如,它可以逼真地再现人奔跑的景象或自然现象的变化。此外,它还能精确再现多个角色的细节、动作类型以及主体和背景的具体细节。
以往,使用生成式人工智能进行视频创作面临着一个艰巨挑战,即如何在不同场景之间保持一致性和可再现性。这是因为,在单独生成每个场景或每一帧时,要完全理解之前的上下文和细节,并将其适当地继承到下一个场景中是一项极其艰巨的挑战。然而,该模型通过将 “对带有视觉上下文的语言的深刻理解” 和 “对 prompt 的准确解读” 相结合,保证了叙事的一致性。它还能从给定的 prompt 中捕捉人物的情绪和个性特征,并将其描绘成视频中富有表现力的角色。
The post by Bill Peebles (OpenAI) via X
02
它背后的相关技术和相关研究有哪些?
Photo by Markus Spiske on Unsplash
Sora 的研究建立在先前图像数据生成模型研究的基础上。之前的研究采用了多种方法,如递归网络(recurrent networks)、生成对抗网络(GANs)、自回归Transformers和扩散模型,但通常专注于某些单一类别的视觉数据、较短的视频或固定分辨率的视频。Sora 超越了这些限制,并且在生成视频的持续时间、长宽比和尺寸上得到了显著改进。在本节中,我将介绍支持这些改进的核心技术。
2.1 Transformer
Vaswani et al. (2017), “Attention is all you need.”
Transformer是一种神经网络架构,它彻底改变了自然语言处理(NLP)领域。它由 Vaswani 等人于 2017 年首次提出。该模型极大地克服了传统递归神经网络(RNN)和卷积神经网络(CNN)存在的短板,作为一种创新方法支持着当今的各种突破性技术。

Transformer 模型架构|Vaswani et al. (2017)
RNN 存在的问题:
- 长期依赖(long-term dependencies)问题:尽管 RNN 在理论上可以通过时间传递信息,但在实践中往往难以捕捉长时间跨度的依赖关系。
- 并行处理存在限制:由于 RNN 的每一步计算都依赖于前一步的输出,因此必须进行顺序处理(例如,按顺序逐个处理文本中的单词或句子),从而无法利用现代计算机体系结构提供的并行处理优势。这导致在大型数据集上进行训练效率低下。
CNN 存在的问题:
- 固定的感受野大小(receptive field size):虽然 CNN 擅长提取局部特征,但其固定的感受野大小限制了其在整个上下文中捕捉长距离依赖关系(long-distance dependencies)的能力。
- 难以模拟自然语言的层次结构:使用CNN直接为语言的层次结构建模极具挑战性,可能不足以实现深层次的上下文理解。
Transformer 的新特性:
- 注意力机制:使得模型能够直接建模序列中任意位置之间的依赖关系,从而直接捕捉长距离依赖和广泛的上下文。
- 能够支持并行处理:由于输入数据是作为一个整体一次性处理的,因此实现了计算的高度并行化,大大加快了在大型数据集上的训练速度。
- 可变的感受野(receptive field):注意力机制使得模型能够根据需要动态调整“感受野”的大小。这意味着模型在处理某些任务或数据时,可以自然地将注意力集中在局部信息上,而在其他情况下,则可以考虑更广泛的上下文。
有关 Transformer 更详细的技术解释,请参阅以下链接:
https://towardsdatascience.com/transformers-141e32e69591
2.2 Vision Transformer (ViT)
Dosovitskiy, et al. (2020), “An image is worth 16×16 words: Transformers for image recognition at scale.”
在这项研究中,颠覆自然语言处理(NLP)的 Transformer 原理被应用于图像识别中,为视觉模型开辟了新的方向。
Token 和 Patch
在原始的 Transformer 论文中,token 主要代表单词或句子的一部分,分析这些 token 之间的关系可以深入理解句子的含义。在这项研究中,为了将 token 的概念应用到视觉数据中,图像被划分成了 16×16 的小块(patch),并且每个 patch 都被视为 Transformer 中的一个“token”。这种方法使得模型能够学习到每个 patch 在整个图像中的关系,从而能够基于此识别和理解整个图像。它超越了传统 CNN 模型在图像识别中使用的固定感受野大小的限制,能够灵活捕捉图像中的任何位置关系。
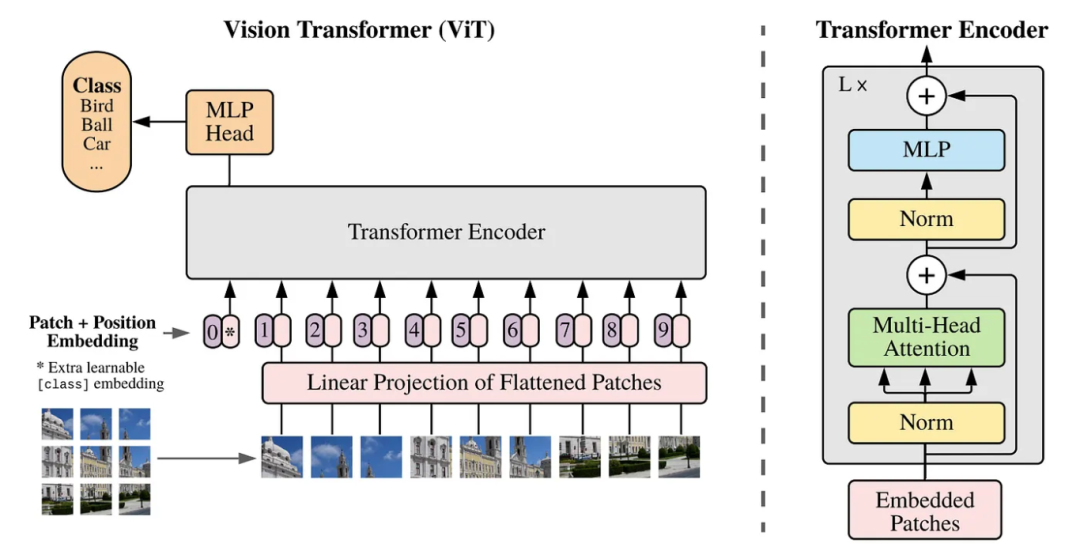
ViT 模型概览|Dosovitskiy, et al. (2020)
有关 Vision Transformer (ViT) 更详细的技术解释,请参阅以下链接:
https://machinelearningmastery.com/the-vision-transformer-model/
2.3 Video Vision Transformer (ViViT)
Arnab, et al. (2021), “Vivit: A video vision transformer.”
ViViT 进一步扩展了 Vision Transformer 的概念,将其应用到视频的多维数据上。视频数据更加复杂,因为它既包含静态图像信息(空间元素),又包含随时间变化的动态信息(时间元素)。ViViT 将视频分解为 patch ,并将其视为 Transformer 模型中的 token。引入 patch 后,ViViT 能够同时捕捉视频中的静态和动态元素,并对它们之间的复杂关系进行建模。

Tubelet (时空输入量) 嵌入图像 |Arnab, et al. (2021)
有关 ViViT 的更多详细技术说明,请参阅以下链接:
https://medium.com/aiguys/vivit-video-vision-transformer-648a5fff68a4
2.4 Masked Autoencoders (MAE) 带有掩码的自编码器
He, et al. (2022), “Masked autoencoders are scalable vision learners.”
这项研究通过使用一种被称为带有掩码的自编码器(Masked Autoencoder)的自监督预训练方法,显著改善了传统上与高维度和海量信息相关的大型数据集训练中存在的计算成本高昂和低效率问题。
具体来说,通过对输入图像的部分内容进行掩码处理,网络被训练来预测隐藏部分的信息,从而更有效地学习图像中的重要特征和结构,并获得丰富的视觉数据表征。这个过程使得数据的压缩(compression )和表征学习(representation learning)更加高效,降低了计算成本,并增强了不同类型的视觉数据以及视觉任务的多样性。
这项研究的方法还与 BERT(Bidirectional Encoder Representations from Transformers)等语言模型的演变密切相关。虽然 BERT 通过 Masked Language Modeling(MLM)实现了对文本数据的深度上下文理解,但 He 等人则将类似的掩码技术应用于视觉数据,实现了对图像的更深层次理解和表示。

Masked Autoencoders|He, et al. (2022)
有关 MAE 的更多详细技术说明,请参阅以下链接:
https://towardsdatascience.com/paper-explained-masked-autoencoders-are-scalable-vision-learners-9dea5c5c91f0
2.5 Native Resolution Vision Transformer (NaViT)
Dehghani, et al. (2023), “Patch n’Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.”
本研究提出了Native Resolution ViTransformer(NaViT),该模型旨在进一步扩展 Vision Transformer(ViT)的适用性,使其适用于任何长宽比或分辨率的图像。
传统 ViT 面临的挑战
Vision Transformer 引入了一种开创性的方法,通过将图像划分为固定大小的 patches ,并将这些 patches 视为 tokens ,将 transformer 模型应用于图像识别任务。然而,这种方法假设模型针对特定分辨率或长宽比进行了针对性的优化,因此对于不同尺寸或形状的图像,需要对模型进行调整。这是一个比较大的限制,因为现实世界中的应用通常需要处理各种尺寸和长宽比的图像。
NaViT 的创新
NaViT 可高效处理任何长宽比或分辨率的图像,允许它们直接输入模型而无需事先调整。Sora 也将这种灵活性应用于视频场景,通过无缝处理各种尺寸和形状的视频和图像,大大提高了模型的灵活性和适应性。
Dehghani, et al. (2023)
2.6 Diffusion Models
Sohl-Dickstein, et al. (2015), “Deep unsupervised learning using nonequilibrium thermodynamics.”
除了 Transformer,扩散模型也是支持 Sora 的骨干技术。这项研究为扩散模型奠定了理论基础,扩散模型是一种利用非平衡热力学的深度学习模型。扩散模型引入了扩散过程的概念,该过程从随机噪声(没有任何模式(pattern)的数据)开始,逐渐去除噪声,从而创建与实际图像或视频相似的数据。
例如,想象一下,一开始只有随机的点,然后逐渐变成美丽风景或人物的视频。这种方法后来被应用于图像和声音等复杂数据的生成,促进了高质量生成模型的发展。

去噪过程的图像|图片来源:OpenAI
Ho et al. (2020), “Denoising diffusion probabilistic models.”
Nichol and Dhariwal (2021), “Improved denoising diffusion probabilistic models.”
在 Sohl-Dickstein 等人(2015)提出的理论框架基础上,开发出了被称为 Denoising Diffusion Probabilistic Models(DDPM)的实用数据生成模型。这种模型在高质量图像生成领域取得了特别显著的成果,证明了扩散模型的有效性。
扩散模型对 Sora 的影响
通常情况下,要训练机器学习模型,需要大量标注数据(比如,告诉模型“这是一张猫的图像”)。然而,扩散模型也可以从未被标注的数据中学习,使其能够利用互联网上大量的视觉内容来生成各种类型的视频。换句话说,Sora 可以通过观察不同的视频和图像,学习到“什么是一个正常视频的样子”。
有关 Diffusion Models 的更多详细技术说明,请参阅以下链接:
https://towardsdatascience.com/diffusion-models-made-easy-8414298ce4da
https://towardsdatascience.com/understanding-the-denoising-diffusion-probabilistic-model-the-socratic-way-445c1bdc5756
2.7 Latent Diffusion Models
Rombach, et al. (2022), “High-resolution image synthesis with latent diffusion models.”
这项研究为利用扩散模型(diffusion models)合成高分辨率图像这一领域做出了重大贡献。它提出了一种方法,与直接生成高分辨率图像相比,该方法通过利用隐空间(latent space)中的扩散模型,在保证质量的前提下大大降低了计算成本。换句话说,它通过对在隐空间(一个容纳图像压缩表征的低维空间)中表示的数据进行编码并引入扩散过程,可以用更少的计算资源实现目标,而不是直接操作图像。
Sora 将这一技术应用于视频数据,将视频的时间+空间数据压缩到较低维度的隐空间,然后将其分解为时空碎片(spatiotemporal patches)。这种高效的隐空间数据处理和生成能力,在使 Sora 能够更快地生成更高质量的视觉内容方面发挥了至关重要的作用。
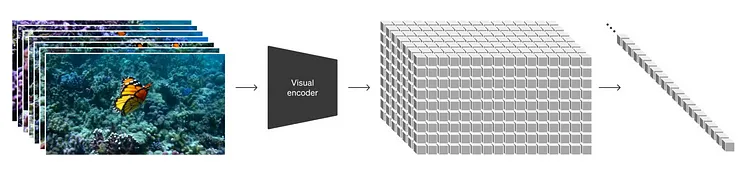
Image of visual encoding|Image Credit (OpenAI)
有关 Latent Diffusion Models 的更多详细技术说明,请参阅以下链接:
https://towardsdatascience.com/paper-explained-high-resolution-image-synthesis-with-latent-diffusion-models-f372f7636d42
2.8 Diffusion Transformer (DiT)
Peebles and Xie. (2023), “Scalable diffusion models with transformers.”
这项研究可能是实现 Sora 最关键的部分。正如 OpenAI 发布的技术报告所述,Sora 采用的不是普通的 transformer ,而是 diffusion transformer(DiT)。
Importantly, Sora is a diffusion transformer. (via OpenAI Sora technical report)
这项研究引入了一种新的模型,用 Transformer 结构替代了扩散模型中常用的 U-net 组件。这种结构通过 Transformer 对 latent patches 的操作实现 Latent Diffusion Model。这种方法能够更高效地处理image patches,从而在有效利用计算资源的同时生成高质量的图像。与 2022 年 Stability AI 宣布的 Stable Diffusion 不同,引入这种 Transformer 被认为有助于更自然地生成视频。
Diffusion Transformers生成的图像|Peebles and Xie. (2023)
此外,值得注意的是,他们的验证结果证明了 DiT 具备可扩展性,为 Sora 的实现做出了重大贡献。具备可扩展性意味着模型的性能能够随着 Transformer 的深度/宽度(使模型更复杂)或输入 token 数量的增加而提高。
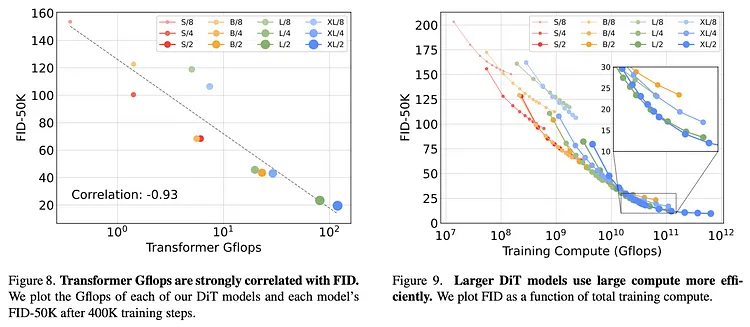
Diffusion Transformers 的可扩展性|Peebles and Xie. (2023)
- Gflops(计算性能):计算机计算速度的度量单位,相当于每秒十亿次浮点运算。在本文中,网络复杂度(network complexity)通过 Gflops 进行衡量。
- FID(Fréchet Inception Distance):这是图像生成的评估指标之一,数值越小表示准确性越高。它通过测量生成图像和真实图像的特征向量之间的距离来定量评估生成图像的质量。
Kaplan 等人(2020)和 Brown 等人(2020)已经证实,在自然语言处理领域已经观察到了这一点(译者注:此处应当指的是“存在可扩展性”),这也是支持 ChatGPT 创新成功背后的关键特性。
Kaplan et al. (2020), “Scaling Laws for Neural Language Models.”
Brown, et al. (2020), “Language models are few-shot learners.”
与传统的扩散模型(diffusion models)相比,由于 Transformer 的优势,它能以更低的计算成本生成高质量的图像,而这一显著特点表明,使用更多的计算资源甚至可以生成更高质量的图像。Sora 将这项技术应用于视频生成。
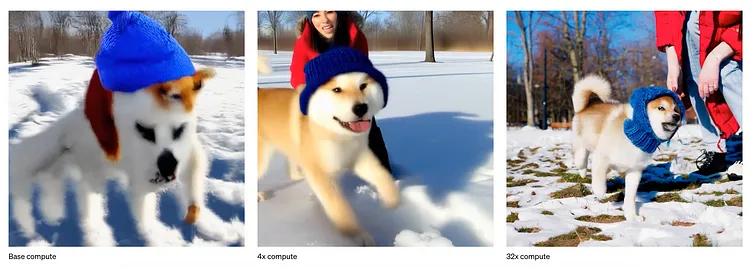
视频生成的可扩展性|Image Credit (OpenAI)
有关 DiT 的更多详细技术说明,请参阅以下链接:
https://youtu.be/eTBG17LANcI
03
这些研究基础加上OpenAI的努力共同造就了 Sora
3.1 可变的视频时长、分辨率、长宽比
主要得益于NaViT,Sora能够生成widescreen 1920x1080p视频、vertical 1080×1920视频以及介于两者之间的所有视频。这意味着它可以为各种设备类型创建任何分辨率的视觉内容。
3.2 使用图像和视频作为 Prompt
目前,Sora 以 text-to-video 的格式实现视频生成,即通过文本提示词给出指令生成视频。不过,从前面的研究中不难看出,也可以使用现有的图片或视频作为输入,而不仅仅是文字。这样,Sora 就可以将图像制作成动画,或将现有视频的过去或未来想象成视觉内容并输出。
3.3 3D consistency
虽然不清楚上述研究如何直接参与其中,帮助实现这一特性。但 Sora 可以生成具有dynamic camera motion效果(译者注:dynamic camera motion 表明视频不是静止不动的,而是随着时间变化而移动、旋转或改变视角。)的视频。随着“摄像机”的移动和旋转,人物和场景元素能够在三维空间中保持一致地移动。
04
展望Sora的未来
这篇博文详细介绍了OpenAI用于生成视频的通用视觉模型 Sora 背后的技术。一旦 Sora 能够向公众开放,让更多人使用,必将在全球范围内产生更加重大的影响。
这一突破所带来的影响预计将涵盖视频创作的各个方面,但据预测,Sora 可能在视频领域扎根后继续进军三维建模领域。届时,不仅对视频创作者产生影响,就连虚拟空间(如元宇宙)中的视觉效果制作也能很快由人工智能轻松生成。
下图已经暗示了这种情况未来可能会出现:
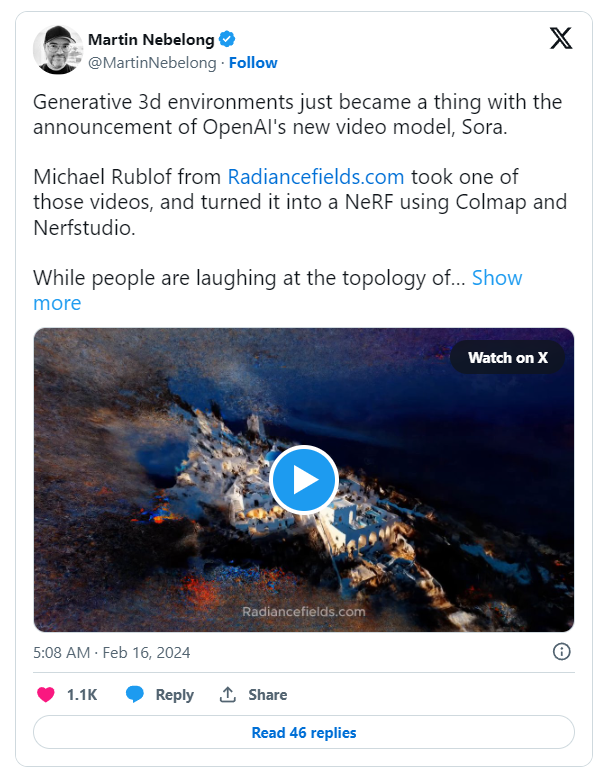
Martin Nebelong 通过 X 发布的与 Micael Rublof 产品相关的帖子
目前,Sora被部分人认为“仅仅”是一个视频生成模型,但Nvidia的Jim Fan暗示它可能是一个数据驱动的物理引擎。人工智能有可能从大量真实世界的视频和(虽然没有明确提到)需要考虑物理行为的视频(如虚幻引擎中的视频)中理解物理规律和现象。如果是这样,那么在不久的将来出现 text-to-3D 模型的可能性也是非常高的。
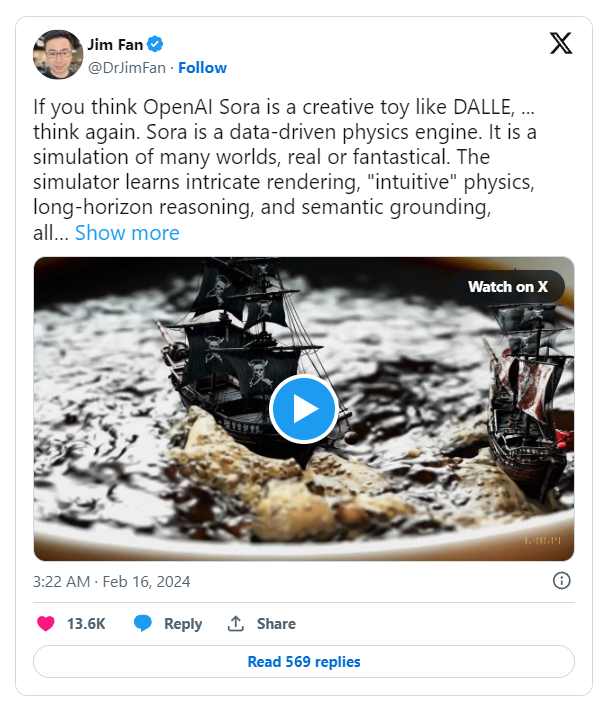
Jim Fan’s intriguing post via X
Thanks for reading!
END














暂无评论内容