跨平台的多模态智能体基准测试 CRAB 由 CAMEL AI 社区主导,由来自牛津、斯坦福、哈佛、KAUST、Eigent AI 等机构的研究人员合作开发。CAMEL AI 社区开发的 CAMEL 框架是最早基于大语言模型的多智能体开源项目,因此社区成员多为在智能体领域有丰富科研和实践经验的研究者和工程师。
AI 智能体(Agent)是当下大型语言模型社区中最为吸引人的研究方向之一,用户只需要提出自己的需求,智能体框架便可以调度多个 LLMs 并支持多智能体(Multi-agents)以协作或竞争的方式来完成用户给定的任务。
目前智能体已越来越多地与大型多模态模型 (MLM) 相结合,支持在各种操作系统( 包括网页、桌面电脑和智能手机) 的图形用户界面( GUI) 环境中执行任务。但是目前针对这种智能体性能评估的基准(benchmarks)仍然存在很多局限性,例如构建任务和测试环境的复杂性,评价指标的单一性等。
针对这些问题,本文提出了一个全新的跨环境智能体基准测试框架 CRAB。CRAB 采用了一种基于图的细粒度评估方法,并提供了高效的任务和评估器构建工具。本文的研究团队还基于 CRAB 框架开发了一个跨平台的测试数据集 CRAB Benchmark-v0,其中涵盖了可以在 PC 和智能手机环境中执行的 100 个任务,其中既包含传统的单平台任务,还包含了必须同时操作多个设备才能完成的复杂跨平台任务。

论文题目:CRAB: Cross-environment Agent Benchmark for Multimodal Language Model Agents
论文地址:https://arxiv.org/abs/2407.01511
代码仓库:https://github.com/camel-ai/crab
作者选取了当前较为流行的四个多模态模型进行了初步实验,实验结果表明,使用 GPT-4o 作为推理引擎的单智能体结构拥有最高的测试点完成率 35.26%。
引言
作为全新的智能体评估基准框架,CRAB(Cross-environment Agent Benchmark)主要用于评估基于多模态语言模型(MLMs)的智能体在跨环境任务中的表现。CRAB 可以模拟真实世界中人类用户同时使用多个设备完成复杂任务的场景,如 Demo 所示,CRAB 可以用来评估智能体同时操纵一个 Ubuntu 桌面系统和一个 Android 手机系统完成发送信息的过程。
想象一下,如果智能体具备根据人类指令同时精确操作电脑和手机的能力,很多繁杂的软件操作就可以由智能体来完成,从而提高整体的工作效率。为了达成这个目标,我们需要为智能体构建更加全面和真实的跨平台测试环境,特别是需要支持同时操作多个设备并且能提供足够的评估反馈机制。本文的 CRAB 框架尝试解决以下几个实际问题:
跨环境任务评估:现有的基准测试通常只关注单一环境(如网页、Android 或桌面操作系统)[1][2][3][4],而忽视了真实世界中跨设备协作场景的复杂性。CRAB 框架支持将一个设备或应用的交互封装为一个环境,通过对多环境任务的支持,提供给智能体更丰富的操作空间,也更贴近实际应用场景。
细粒度评估方法:传统的评估方法要么只关注最终目标的完成情况(目标导向),要么严格比对操作轨迹(轨迹导向)[1][2][3]。这两种方法都存在局限性,无法全面反映智能体的表现。CRAB 提出了基于图的评估方法,既能提供细粒度的评估指标,又能适应多种有效的任务完成路径。
任务构建复杂性:随着任务复杂度的增加,手动构建任务和评估器变得越来越困难。CRAB 提出了一种基于子任务组合的方法,简化了跨环境任务的构建过程。
智能体系统结构评估:本文还探讨了不同智能体系统结构(单智能体、基于功能分工的多智能体、基于环境分工的多智能体)对任务完成效果的影响,为设计更高效的智能体系统提供了实证依据。
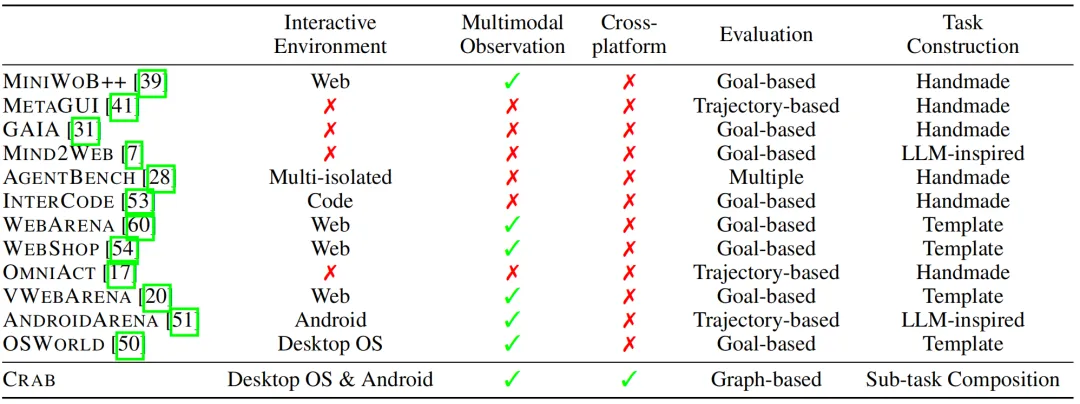
上表展示了本文提出的 CRAB 框架与现有其他智能体基准框架的对比,相比其他基准,CRAB 可以同时支持电脑和手机等跨平台的操作环境,可以模拟更加真实的使用场景。
对于 CRAB,一众网友给出了很高的评价。
有人表示,AGI 已经达成,因为有大语言模型(指 CRAB)已经学会了如何退出 Vim。
“Can you exit Vim?” 这个问题常常是一个编程或技术社区的玩笑,因为 Vim 对新手来说可能很难退出,尤其是当他们不熟悉 Vim 的操作模式时。(在此贡献一张表情包)

有人说很难相信一个智能体可以完成 “查看日历,打开 Vim,进入插入模式,输入事件列表,退出插入模式,并使用 :wq 保存” 这一系列任务。
也有网友总结说下个下一代机器人流程自动化(RPA)将更像是 “请帮我完成下列任务”,而不需要记录每一个步骤,然后在几天内运行时崩溃。


也有人提到了 CRAB 中的图评估器(Graph Evaluator)用于处理智能体在环境中的状态是一种非常智能的方式。

甚至有人夸赞道 CRAB 是 AI PC 的未来,认为这是 LLM 与 PC 和移动设备的完美结合,“它是一种类似 RabbitOS 的 AI,使现有的 PC 和移动设备具备 AI 功能。CRAB 的基准测试允许在现实世界中测试多模态语言模型代理的有效性和实用性。”

定义
任务定义
CRAB 框架将数字设备(如桌面电脑或智能手机)表示为一个具体的环境。每个环境被定义为一个无奖励的部分可观察马尔可夫决策过程(POMDP),可以使用元组
![]()
表示,其中
![]()
为状态空间,
![]()
为动作空间,
![]()
是转移函数,
![]()
是观察空间。
而对于跨环境任务,可以定义一个环境集合
![]()
其中 n 是环境数量,每个环境又可以表示为
![]()
。
基于以上,作者将一个具体的跨环境任务表示为元组
![]()
,其中 M 是环境集合,I 是以自然语言指令形式给出的任务目标,R 是任务的奖励函数。参与任务的智能体系统可以被建模为一个策略
![]()
。
这表示智能体在接收到来自环境
 的观察
的观察
![]() 和动作历史 H 时,在环境 m 中采取动作 a 的概率。
和动作历史 H 时,在环境 m 中采取动作 a 的概率。
图任务分解(Graph of Decomposed Tasks, GDT)
将复杂任务分解为几个更简单的子任务是 LLMs 解决实际问题时非常有效的技巧 [5][6],本文将这一概念引入到了智能体基准测试中,具体来说,本文引入了一种分解任务图(Graph of Decomposed Tasks,GDT),如下图所示,它可以将一个复杂任务表示为一个有向无环图(DAG)的结构。
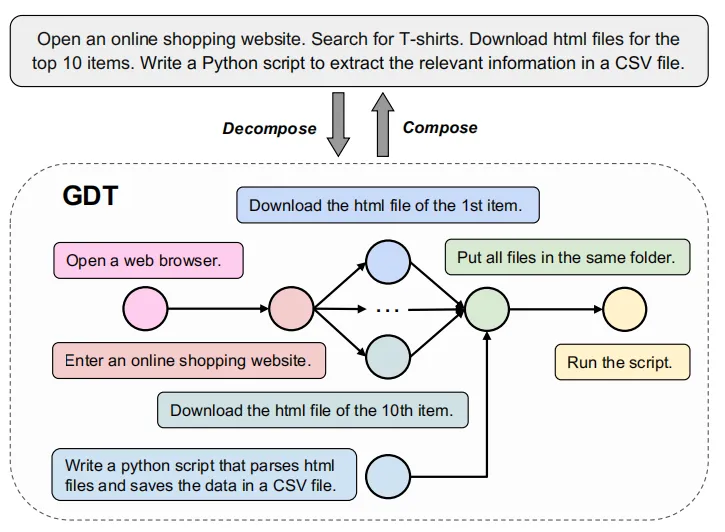
GDT 中的每个节点可以代表一个子任务 (m,i,r),其中 m 为子任务执行的环境,i 为自然语言指令,r 是奖励函数,用于评估环境 m 的状态并输出布尔值,判断子任务是否完成。GDT 中的边表示子任务之间的顺序关系。
CRAB 框架
跨环境智能体交互
CRAB 首次引入了跨环境任务的概念,将多个环境(如智能手机和桌面电脑)组合成一个环境集合,使智能体能够在多个设备之间协调操作完成复杂任务。

在 CRAB 框架中使用基于环境分工的多智能体系统的运行流程如上图所示。工作流程通过一个循环进行,首先通过主智能体观察环境,并对子智能体指定计划,然后所有的子智能体在各自的环境中执行操作。随后由一个图评估器(Graph Evaluator)来监视环境中各个子任务的状态,并在整个工作流程中不断更新任务的完成情况。这种评估方式可以贴近真实场景,以考验智能体的推理能力,这要求智能体能够处理复杂的消息传递,并且需要深入理解现实世界的情况。
图评估器(Graph Evaluator)
CRAB 内置的图评估器同时兼顾了目标导向和轨迹导向评估的优点,其首先将复杂任务分解为多个子任务,形成一个有向无环图结构。随后定义了一种节点激活机制,即图中的节点(子任务)需要根据前置任务的完成情况逐步激活,确保任务的顺序执行。其中每个节点都关联了一个验证函数,用来检查环境中的关键中间状态。相比之前的评估基准,CRAB 图评估器创新性地引入了一系列新的评价指标:
完成率(Completion Ratio, CR):完成的子任务节点数量与总节点数量的比率,CR = C / N。
执行效率(Execution Efficiency, EE):完成率与执行的动作数量的比值,EE = CR / A,A 为指定的动作数。
成本效率(Cost Efficiency, CE):完成率与使用的模型 token 数量的比值,CE = CR / T,T 为使用的模型 token 数量。
这些指标为智能体基准提供了更细粒度和更多维度的评估侧重点。
CRAB Benchmark-v0
基准构建细节
基于提出的 CRAB 框架,本文构建了一个具体的基准测试集 CRAB Benchmark-v0 用于社区进一步开展研究。CRAB Benchmark-v0 同时支持 Android 手机和 Ubuntu Linux 桌面电脑两个环境。并且为 Ubuntu 和 Android 定义了不同的动作集,用来模拟真实生活中的常见交互。其观察空间由两种环境的系统界面构成,并且使用屏幕截图形式获取环境状态。为了方便智能体在 GUI 中操作,作者使用 GroundingDINO [7] 来定位可交互图标,使用 EasyOCR 检测和标注可交互文本,为每个检测项分配一个 ID,方便后续在操作空间内引用。
我们以一个具体任务举例,例如在 Ubuntu 系统上完成如下任务:创建一个新目录 “/home/crab/assets_copy”,并将所有具有指定 “txt” 扩展名的文件从 “/home/crab/assets” 复制到目录 “/home/crab/assets_copy”。
该任务需要执行多步操作才能完成,下图展示了当使用 GPT-4 Turbo 作为推理模型并采用单智能体结构时的实验细节。智能体首先使用 search_application 命令查找终端并打开。
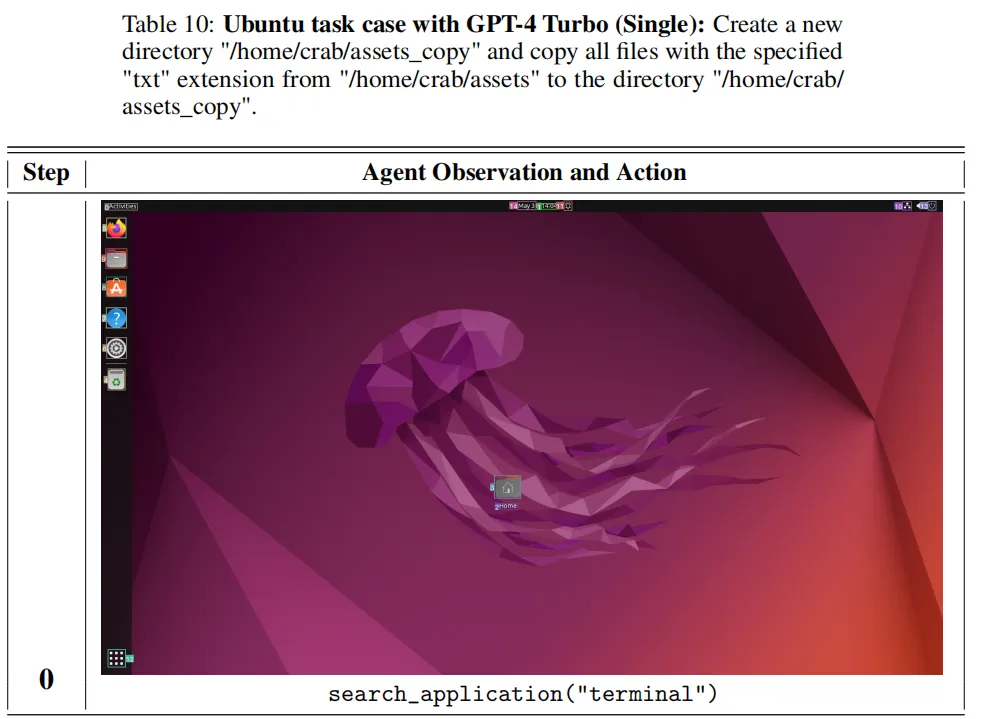
然后使用 Linux 命令 “mkdir -p /home/crab/assets_copy” 创建新的目标目录。
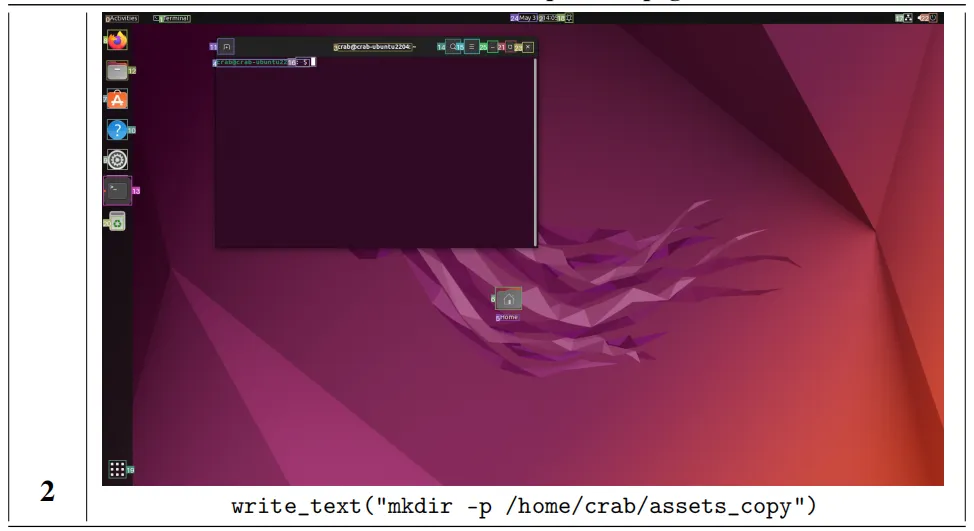
在创建好目标目录后,智能体直接在终端中执行了拷贝命令 :
“cp /home/crab/assets/*.txt/home/crab/assets_copy” 来完成任务,整个流程行云流水,没有任何失误。

实验效果
作者随后在 CRAB Benchmark-v0 进行了 baseline 实验,智能体的核心是后端的多模态语言模型,其用来提供自然语言和图像理解、基本设备知识、任务规划和逻辑推理能力,需要支持多模态混合输入,可以同时处理多轮对话,因而作者选取了 GPT-4o (gpt-4o-2024-05-13)、GPT-4 Turbo (gpt-4-turbo-2024-04-09)、Gemini 1.5 Pro (2024 年 5 月版本) 和 Claude 3 Opus (claude-3-opus-20240229) 作为 baseline 模型。

实验结果如上表所示,其中 GPT-4o 和 GPT-4 Turbo 模型在测试模型中实现了最高的平均测试点完成率(CR)。在执行效率(EE)和成本效率(CE)方面, GPT-4 系列也相比 Gemini 和 Claude 系列模型更加优秀。
总结
本文介绍了一种全新的跨环境多智能体评估基准 CRAB,CRAB 框架通过引入跨环境任务、图评估器和基于子任务组合的任务构建方法,为自主智能体的评估提供了一个更加全面、灵活和贴近实际的基准测试平台。相比先前的智能体基准,CRAB 减少了任务步骤中的手动工作量,大大提高了基准构建效率。基于 CRAB,本文提出了 Crab Benchmark-v0,同时支持智能体在 Ubuntu 和 Android 系统上执行多种复杂的跨环境任务,这一基准的提出,不仅可以推动自主智能体评价体系的发展,也为未来设计更加高效的智能体系统提供全新灵感。














暂无评论内容