2024年5月15日,字节宣布其主力AI大模型的定价为输入0.0008元/千tokens(0.8元/百万tokens),当时称较行业便宜99.3%。
5月21日,阿里云宣布,通义千问对标ChatGPT-4的主力模型Qwen-Long,API输入价格从0.02元/千tokens(20元/百万tokens)降至0.0005元/千tokens(0.5元/百万tokens),直降97%。
百度随之公告,文心大模型的两款入门级主力模型ENIRE Speed、ENIRE Lite全面免费。
此前,智谱AI入门级产品GLM-3 Turbo模型的调用价格也从5元/百万tokens降至1元/百万tokens。
而引领这一趋势的事件,正是5月6日, DeepSeek发布全新第二代MoE模型DeepSeek-V2,并宣布自身的API定价为每百万tokens输入1元、输出2元,这一价格显著低于当前市场上的其他同类产品,仅为GPT-4-Turbo价格的近百分之一。
5月15日,DeepSeek完成备案正式开放服务,之后国内AI大模型公司纷纷加入大幅降价行列。
DeepSeek这家从未在市场融资的神秘大模型公司一跃成名。


成立背景和核心理念
DeepSeek(杭州深度求索人工智能基础技术研究有限公司,本文简称“DeepSeek”)由梁文锋创立,他在DeepSeek最终受益的股份比例超80%(根据天眼查数据)。
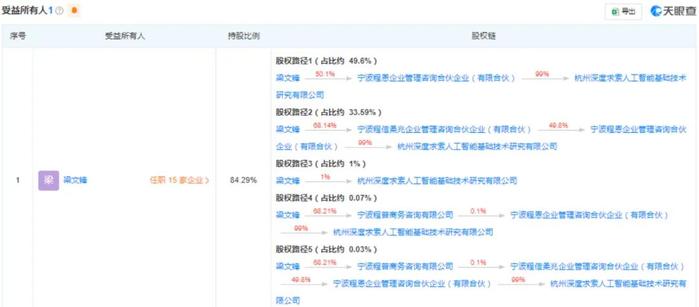
梁文锋是幻方量化的实际控制人,幻方量化是国内量化私募领域的巨头之一,管理规模曾一度飙升至千亿,现在管理规模依然在600亿元左右。

DeepSeek的创立,源于梁文峰在幻方量化时期即对AI的热衷。
2019年,其自研的深度学习训练平台「萤火一号」总投资近2亿元,搭载了1100块GPU;两年后,「萤火二号」的投入增加到10亿元,搭载了约1万张英伟达A100显卡。
背靠幻方,DeepSeek第一期研发投入即为幻方自主出资,同时有“萤火超算”万卡级别的算力支持,单从资金及硬件配置上,DeepSeek在初期远比国内大部分AI初创企业优渥。
使得DeepSeek是国内除了互联网大厂之外少有的能够拥有超过1万张英伟达A100显卡的人工智能公司。
(1)要原创不要模仿
随着经济发展,中国也要逐步成为贡献者,而不是一直搭便车。DeepSeek要以创新贡献者的身份,加入到游戏里去。
—— 梁文峰曾这样解释DeepSeek的初衷。
DeepSeek的中文翻译为“深度求索”,这反映了公司的定位与目标。
DeepSeek没有选择“1→10”而逆向选择了“0→1”,其提出了一种崭新的MLA(一种新的多头潜在注意力机制)架构,是DeepSeek对模型架构进行了全方位创新。
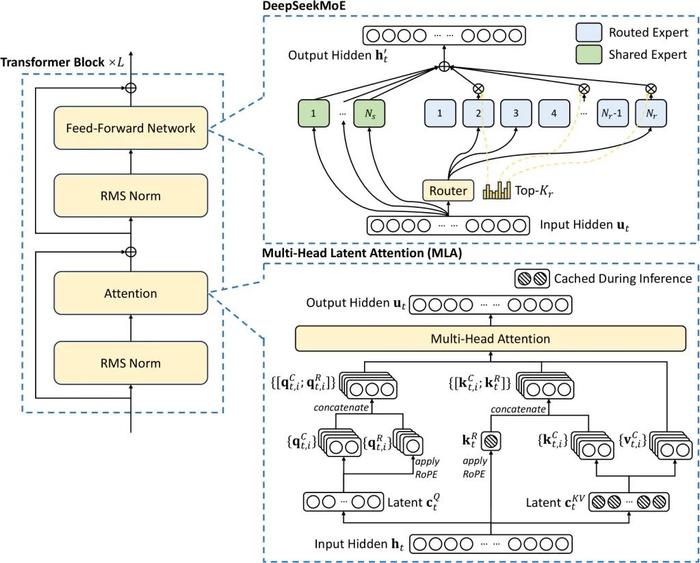
也正是这种独特架构,其把显存占用降到了过去最常用的MHA架构的5%-13%,同时,它独创的DeepSeekMoESparse结构,也把计算量降到极致,所有这些最终促成了成本的下降,宣布了行业震惊的定价方案,并引领了大模型降价潮。
(2)首要创新,暂不考虑商业化
梁文峰曾表示:
创新首先是一个信念问题。
DeepSeek是国内少数专注研究和技术的AI大模型公司,也是唯一一家未全面考虑商业化,甚至没有进行融资的公司。
DeepSeek希望形成一种生态,业界直接使用DeepSeek的技术和产出,DeepSeek只负责基础模型和前沿的创新,然后其它公司在DeepSeek的基础上构建toB、toC的业务。
(3)本土人才撑起研发
与其他AI企业执着地去海外挖人不同,DeepSeek热衷于自身培养。
DeepSeek的团队成员包括来自顶尖高校的应届毕业生、博四、博五实习生以及毕业几年的年轻人,他们对研究充满热情和好奇心。
梁文峰表示:“前50名顶尖人才可能不在中国,但也许我们能自己打造这样的人。”

团队构成与专业背景
(1)创始人——梁文锋
梁文锋,深度求索创始人、幻方量化创始人。
他本硕就读于浙江大学,攻读人工智能,念书时就笃定“AI定会改变世界”。
毕业后,梁文锋没有走程序员的既定路线,而是下场做量化投资,成立幻方量化。幻方量化成立仅6年管理规模即曾达到千亿,被称为“量化四大天王”之一。
(2)团队构成
OpenAI前政策主管、Anthropic联合创始人Jack Clark认为,DeepSeek“雇佣了一批高深莫测的奇才”。
DeepSeek的团队成员包括来自顶尖高校的应届毕业生、博四、博五实习生以及毕业几年的年轻人,但是具体是谁,我们不得而知。

模型介绍
立足于开源,DeepSeek认为先有一个强大的技术生态更重要。
在颠覆性的技术面前,闭源形成的护城河是短暂的。DeepSeek的护城河来自在研发过程中团队的成长及经验的积累。
目前DeepSeek的模型全部开源,包括通用大模型DeepSeek LLM、MoE模型DeepSeek MoE、DeepSeek V2、代码模型DeepSeek Coder、DeepSeek Coder V2、数学模型DeepSeek Math、多模态大模型DeepSeek VL。
DeepSeek 的 GitHub 页面
(1)MoE模型DeepSeek-V2
2024年1月,DeepSeek发布并开源国内首个MoE大模型 DeepSeekMoE。
2024年5月, DeepSeek发布并开源第二代MoE模型DeepSeek-V2。
DeepSeek-V2是一个混合专家 (MoE) 语言模型,具有训练经济、推理高效的特点。它包含 236B 总参数,其中每个 token 激活 21b,支持 128K tokens 的上下文长度。

DeepSeek-V2没有沿用主流的“类LLaMA的Dense结构”和“类Mistral的Sparse结构”,而是对模型框架进行了全方位的创新,提出了媲美MHA的MLA架构,大幅减少计算量和推理显存;自研Sparse结构DeepSeekMoE进一步将计算量降低到极致,两者结合最终实现模型性能跨级别的提升。
与 DeepSeek 67B 相比,DeepSeek-V2 实现了显著增强的性能,同时节省了 42.5% 的训练成本、减少了 93.3% 的 KV 缓存、并将最大生成吞吐量提升至 5.76 倍。
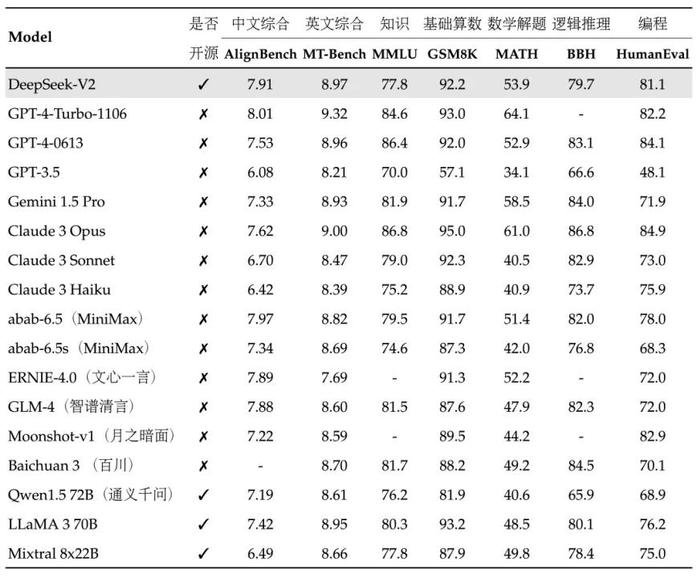
与发布时的模型对比,DeepSeek-V2均表现出色。
中文综合能力(AlignBench)开源模型中最强,与GPT-4-Turbo,文心4.0等闭源模型在评测中处于同一梯队。
英文综合能力(MT-Bench)与最强的开源模型LLaMA3-70B同处第一梯队,超过最强MoE开源模型Mixtral 8x22B。(根据DeepSeek发布同期披露评测数据)
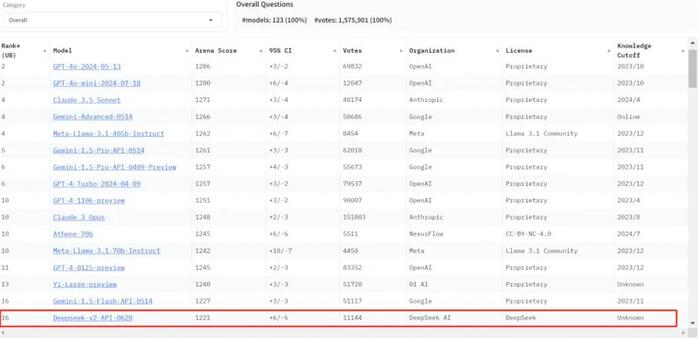
在 LMSYS 盲测竞技场最新排名中,DeepSeek-V2总榜排名世界模型第17,排于其前面的仅有OpenAI、Anthropic、Google、META、NexusFlow、零一万物的大模型。
在Meta-Llama-3.1开源之前,DeepSeek-V2是全球开源模型第一位。
LMSYS 盲测竞技场总榜:
价格
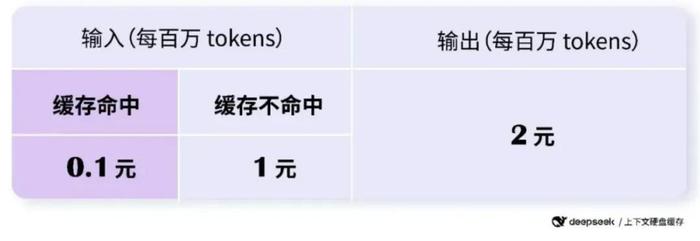
DeepSeek-V2 API的定价为:每百万tokens输入1元、输出2元
最新启用了上下文硬盘缓存技术,把预计未来会重复使用的内容,缓存在分布式的硬盘阵列中。如果输入存在重复,则重复的部分只需要从缓存读取,无需计算。缓存命中的部分,DeepSeek 费用为 0.1元 每百万 tokens。
(2)通用大模型DeepSeek LLM
2023年11月,DeepSeek 发布并开源通用大语言模型DeepSeek LLM,是DeepSeek继DeepSeek Coder后发布的第二款模型。
同时开源 7B 和 67B 的两种规模模型,均含基础模型(base)和指令微调模型(chat)。
相比当时开源的同级别模型 LLaMA2 70B,DeepSeek LLM 67B 在近20个中英文的公开评测榜单上表现更佳。尤其突出的是推理、数学、编程等能力(如:HumanEval、MATH、CEval、CMMLU)。
(3)代码领域模型DeepSeek CoderV2
2023年11月,DeepSeek发布并开源他们首款模型,代码模型 DeepSeek-Coder。
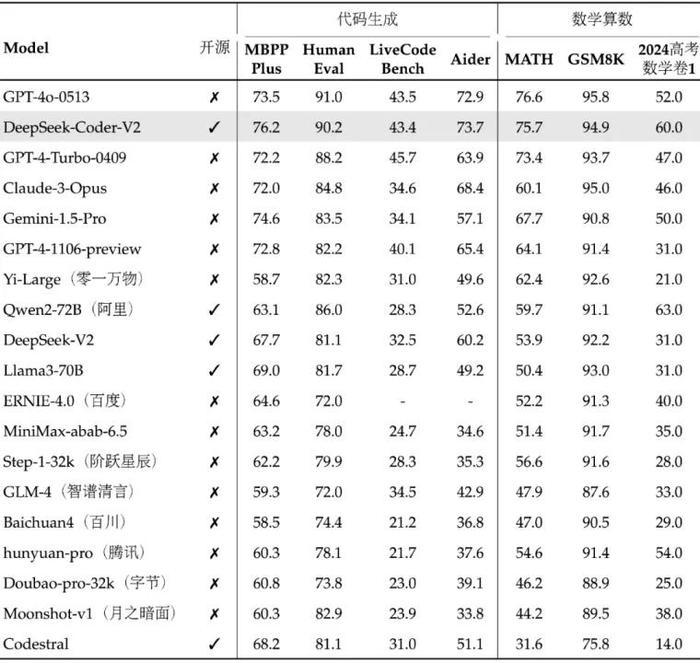
2024年6月,DeepSeek发布并开源代码模型DeepSeek-Coder-V2。DeepSeek-Coder-V2包含236B与16B两种参数规模,对编程语言的支持从86种扩展到338种。
DeepSeek-Coder-V2 沿用 DeepSeek-V2 的模型结构,总参数 236B,激活 21B,发布时在代码、数学的多个榜单上位居全球第二,介于最强闭源模型 GPT-4o 和 GPT-4-Turbo 之间。(根据DeepSeek发布同期披露评测数据)
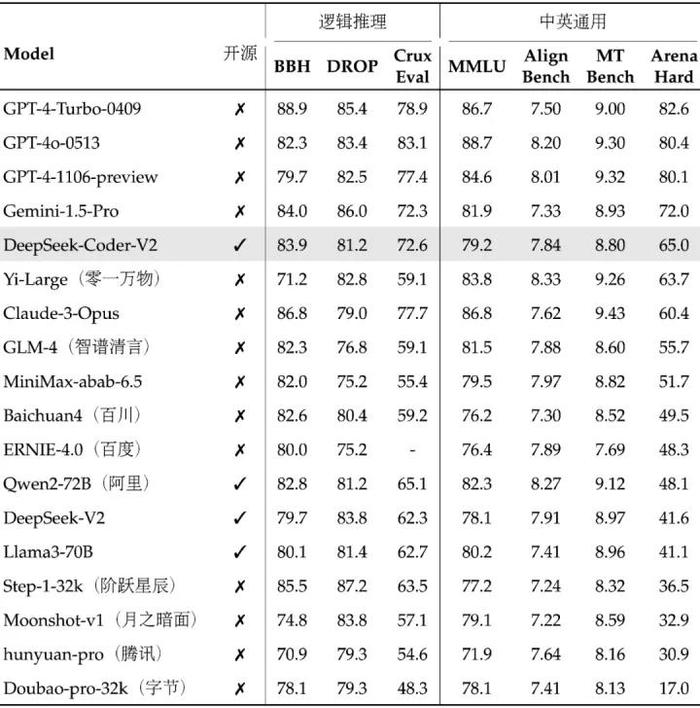
DeepSeek-Coder-V2 还具有良好的通用性能,发布时在中英通用能力上位列国内第一梯队。(根据DeepSeek发布同期披露评测数据)
(4)多模态大模型DeepSeek VL
2024年3月,DeepSeek发布并开源多模态大模型DeepSeek VL。同时开源 7B与1.3B的两种规模模型。
DeepSeek-VL 7B超越同规模(7B 参数)的 EMU2-Chat/Yi-VL 等模型,甚至超过更大规模(17B 参数)的 CogVLM
DeepSeek-VL在不丢失语言能力的情况下融入多模态能力,能够对绝大多数现实场景下的问题给出细致而有条理的回复。

能够接受大尺寸分辨率图片作为输入,高达1024×1024,识别图片中的细小物体。同时具备通用多模式理解能力,能够处理逻辑图、网页、公式识别、科学文献、自然图像,以及在复杂场景中体现智能。

小结
国内不少公司习惯于跟随海外科技公司,参考技术做应用变现。即使是互联网大厂在创新方面也较为谨慎,更加重视应用层面。
DeepSeek逆向而行,在这一波AI大模型的发展浪潮中展现出了更为积极进取的姿态。
DeepSeek不再满足于仅仅成为一个跟随者,而是选择站在技术创新的前端,从架构到模型参与整个AI大模型行业的进程,“要原创,要创新”。
在AI大模型架构层面,创新型提出了MLA架构,并取得了卓越的成绩。
我们非常认同DeepSeek创始人梁立峰关于“中国不可能永远只做模仿”的观点,我们期待DeepSeek在创新的道路上行稳致远,也期待更多的中国公司加入创新的行业。














暂无评论内容