
前段时间国产大模型DeepSeek API推出了磁盘上的上下文缓存,无需代码更改!这一新功能自动将频繁引用的上下文缓存在分布式存储上,将API成本降低高达90%,支持无限并发!对于一个高引用的128K提示,第一个令牌的延迟从13秒缩短到仅500毫秒
受益场景:多轮对话,后续轮次命中先前上下文缓存。对相同文档/文件重复查询的数据分析。重复引用仓库的代码分析/调试
今天claude也推出类似功能,AnthropicAI 宣布Claude 「Prompt 缓存」能力发布,成本降低 90%,延迟降低 85%!



Claude可在多个 API 调用之间重用一本书级别长度的上下文,同时提高响应速度和理解能力 ,现在就可用!
blog: https://www.anthropic.com/news/prompt-caching

现在开发者能够在 API 调用之间缓存常用的上下文。通过提示词缓存,客户可以为 Claude 提供更多的背景知识和示例输出。提示词缓存目前在 Claude 3.5 Sonnet 和 Claude 3 Haiku 的公开测试版中可用,Claude 3 Opus 的支持也即将推出
何时使用提示词缓存
提示词缓存在你希望一次发送大量提示词上下文然后在后续请求中重复引用这些信息的情况下效果显著,包括:
会话智能体: 降低扩展对话的成本和延迟,尤其是那些包含长指令或上传文档的对话。
代码助手: 通过在提示词中保留代码库的摘要版本来提高自动补全和代码库问答的效果。
大文档处理: 将完整的长篇材料(包括图片)纳入提示词中,而不增加响应延迟。
详细指令集: 共享广泛的指令、程序和示例列表以微调 Claude 的响应。开发人员通常在提示词中包含几个示例,但通过提示词缓存,您可以通过包括数十个多样化的高质量输出示例来获得更好的性能
智能搜索和工具使用: 提高多轮工具调用和迭代变化场景的性能,因为这些场景通常每一步都需要新的 API 调用
与书籍、论文、文档、播客转录本和其他长篇内容对话: 通过将整个文档嵌入提示词中,让知识库更具活力,并让用户对其提问
早期客户在多种使用场景中通过提示词缓存实现了显著的速度和成本改进——从包含完整知识库到 100 次样本提示再到将对话的每一次转折纳入提示词中
| 使用场景 | 无缓存时的延迟(首个 token 的时间) | 缓存时的延迟(首个 token 的时间) | 成本降低 |
|---|---|---|---|
| 与书籍聊天(100,000 token 的缓存提示) | 11.5s | 2.4s (-79%) | -90% |
| 多次样本提示(10,000 token 提示) | 1.6s | 1.1s (-31%) | -86% |
| 多轮对话(带有长系统提示的 10 轮对话) | 10s | ~2.5s (-75%) | -53% |
如何为缓存的提示定价
缓存的提示根据缓存的输入 token 数量及其使用频率定价。写入缓存的成本比任何给定模型的基础输入 token 价格高 25%,而使用缓存内容则便宜得多,仅为基础输入 token 价格的 10%
| 模型 | 输入 | 提示词缓存 | 输出 |
|---|---|---|---|
| Claude 3.5 Sonnet | – 迄今为止最智能的模型 – 200K 上下文窗口 | $3 / MTok | $3.75 / MTok – 缓存写入 $0.30 / MTok – 缓存读取 |
| Claude 3 Opus | – 适用于复杂任务的强大模型 – 200K 上下文窗口 | $15 / MTok | 提示词缓存 即将推出 $18.75 / MTok – 缓存写入 $1.50 / MTok – 缓存读取 |
| Claude 3 Haiku | – 最快、最具成本效益的模型 – 200K 上下文窗口 | $0.25 / MTok | $0.30 / MTok – 缓存写入 $0.03 / MTok – 缓存读取 |
使用
要使用提示词缓存,只需将以下缓存控制属性添加到想缓存的内容中:
“cache_control”: {“type”: “ephemeral”}
以及在API调用中添加此Beta版标头:
“anthropic-beta”: “prompt-caching-2024-07-31”
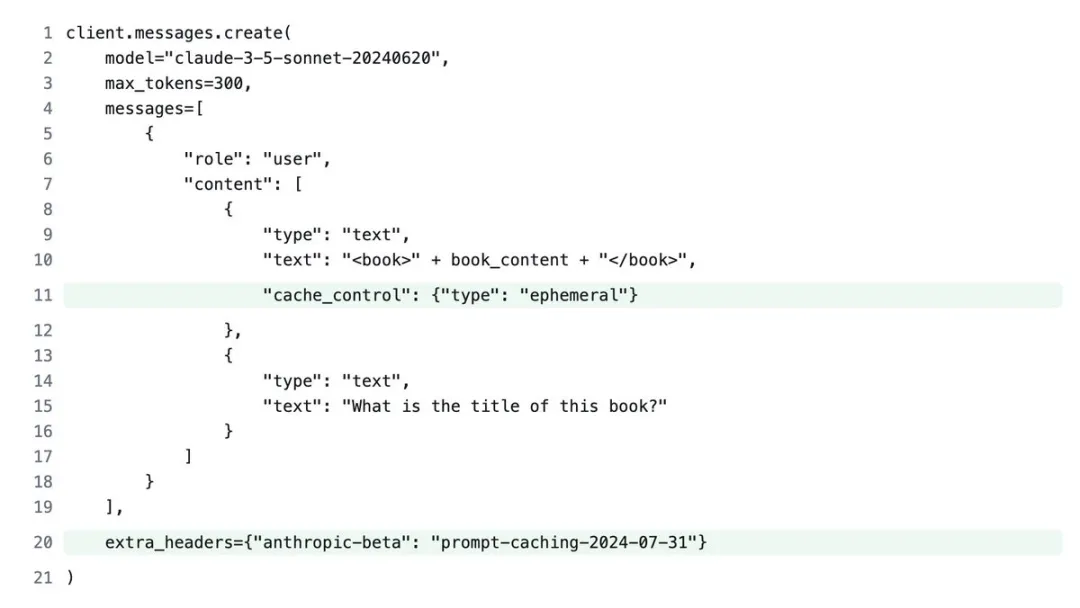
当你使用这些附加功能进行API调用时,claude会检查您的提示词的指定部分是否已从最近的查询中缓存。
如果是这样,claude将使用缓存的提示词,加快处理时间并降低成本。
说到成本,由于需要将提示词存储在缓存中,初始API调用会稍微贵一些,但随后的所有调用价格仅为正常价格的十分之一
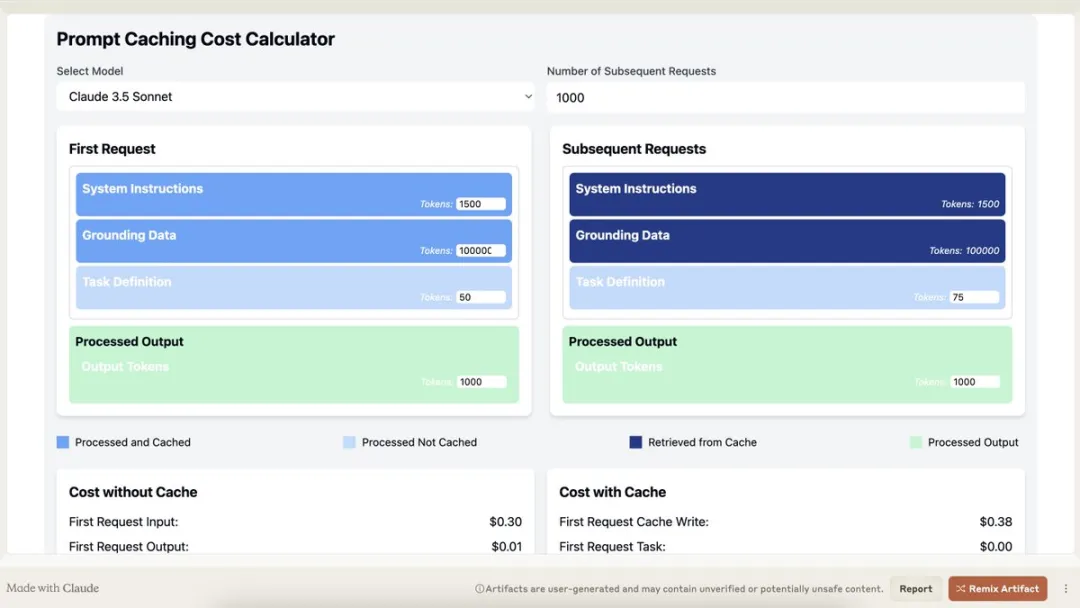
这里用claude artifacts功能创建了一个交互式计算器,可以计算成本节省:
https://claude.site/artifacts/12fe4ec9-8593-4868-8656-ab0d0fbb35bf
提示词缓存在多轮对话中也能发挥作用。可以在对话进行中逐步设置缓存控制断点,以缓存之前的对话轮次
这在与工具使用等功能结合时非常有用,因为这些功能可能在每一轮对话中向上下文窗口添加许多tokens,这会增加处理复杂性。
其他注意事项:
• 缓存生命周期(TTL)为5分钟,每次使用都会重置
• 提示词以1024个token为边界进行缓存
• 您可以在一个提示词中定义最多4个缓存断点
• 对于少于1024个token的提示词缓存支持即将推出














暂无评论内容