虽然已经发布近一周时间,OpenAI 视频生成大模型 Sora 的影响仍在继续!
其中,Sora 研发负责人之一 Bill Peebles 与纽约大学助理教授谢赛宁撰写的 DiT(扩散 Transformer)论文《Scalable Diffusion Models with Transformers》被认为是此次 Sora 背后的重要技术基础之一。该论文被 ICCV 2023 接收。

- 论文地址:https://arxiv.org/pdf/2212.09748v2.pdf
- GitHub 地址:https://github.com/facebookresearch/DiT
这两天,DiT 论文和 GitHub 项目的热度水涨船高,重新收获大量关注。
论文出现在 PapersWithCode 的 Trending Research 榜单上,星标数量已近 2700;还登上了 GitHub Trending 榜单,星标数量每日数百增长,Star 总量已超 3000。
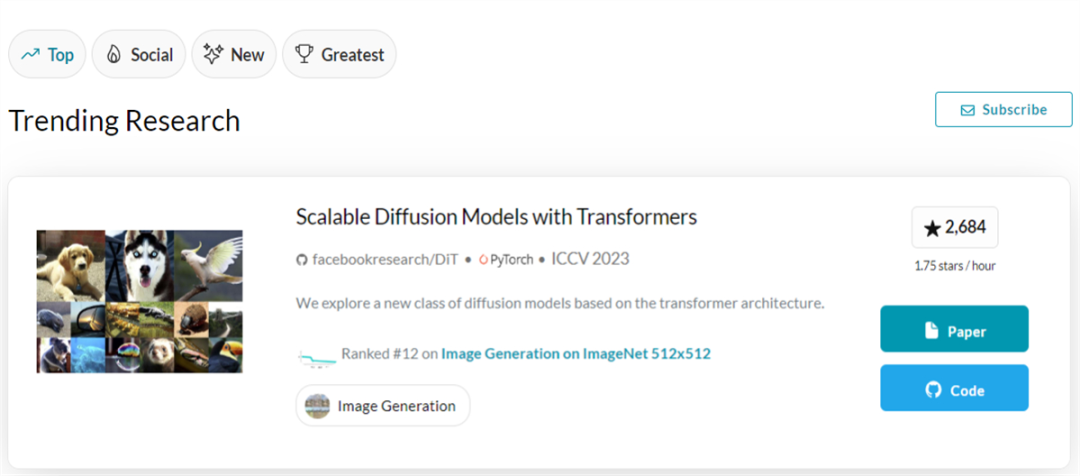
来源:https://paperswithcode.com/
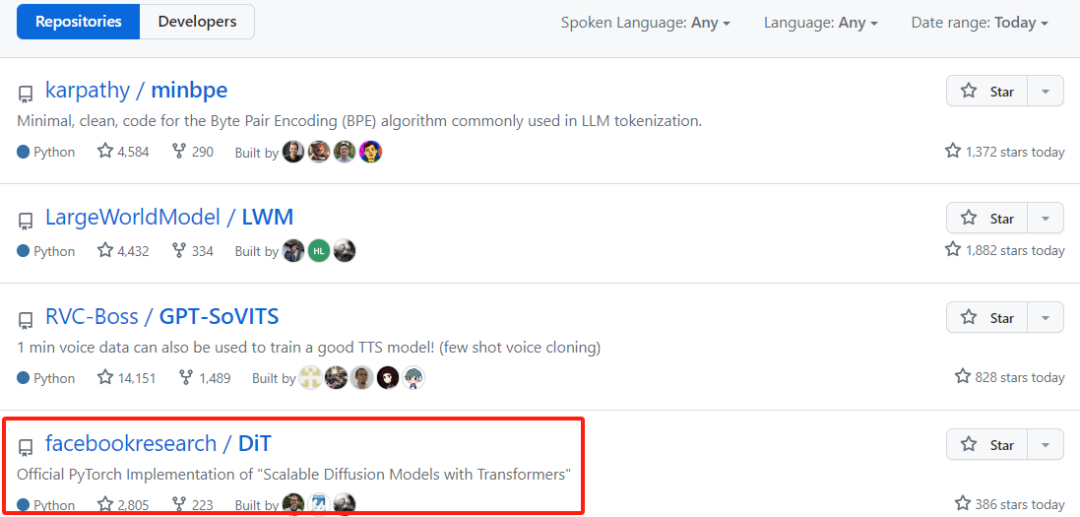
来源:https://github.com/facebookresearch/DiT
这篇论文最早的版本是 2022 年 12 月,2023 年 3 月更新了第二版。当时,扩散模型在图像生成方面取得了惊人的成果,几乎所有这些模型都使用卷积 U-Net 作为主干。
因此,论文的目的是探究扩散模型中架构选择的意义,并为未来的生成模型研究提供经验基线。该研究表明,U-Net 归纳偏置对扩散模型的性能不是至关重要的,并且可以很容易地用标准设计(如 transformer)取代。
具体来说,研究者提出了一种基于 transformer 架构的新型扩散模型 DiT,并训练了潜在扩散模型,用对潜在 patch 进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以 Gflops 衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
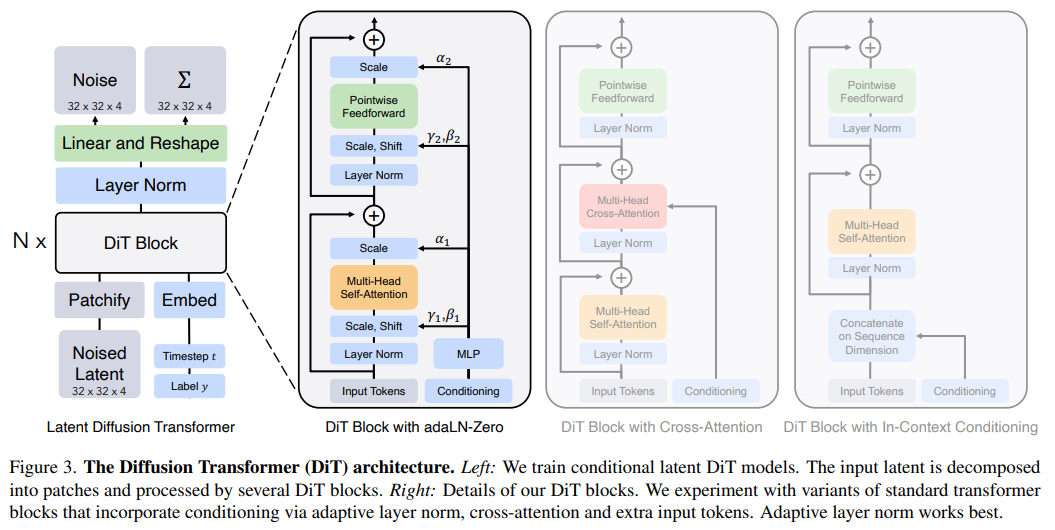
研究者尝试了四种因模型深度和宽度而异的配置:DiT-S、DiT-B、DiT-L 和 DiT-XL。

他们发现,通过增加 Transformer 深度 / 宽度或增加输入 token 数量,具有较高 Gflops 的 DiT 始终具有较低的 FID。

除了良好的可扩展性之外,DiT-XL/2 模型在 class-conditional ImageNet 512×512 和 256×256 基准上的性能优于所有先前的扩散模型,在后者上实现了 2.27 的 FID SOTA 数据。

质量、速度、灵活性更好的 SiT
此外,DiT 还在今年 1 月迎来了升级!谢赛宁及团队推出了 SiT(Scalable Interpolant Transformer,可扩展插值 Tranformer),相同的骨干实现了更好的质量、速度和灵活性。
谢赛宁表示,SiT 超越了标准扩散并通过插值来探索更广阔的设计空间。

该论文标题为《SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers》。

- 论文地址:https://arxiv.org/pdf/2401.08740.pdf
- GitHub 地址:https://github.com/willisma/SiT
简单来讲,SiT 将灵活的插值框架集成到了 DiT 中,从而能够对图像生成中的动态传输进行细微的探索。SiT 在 ImageNet 256 的 FID 为 2.06,将基于插值的模型推向了新的高度。

论文一作、纽约大学本科生 Nanye Ma 对这篇论文进行了解读。本文认为,随机插值为扩散和流提供了统一的框架。但又注意到, 基于 DDPM(去噪扩散概率模型)的 DiT 与较新的基于插值的模型之间存在性能差异。因此,研究者想要探究性能提升的来源是什么?
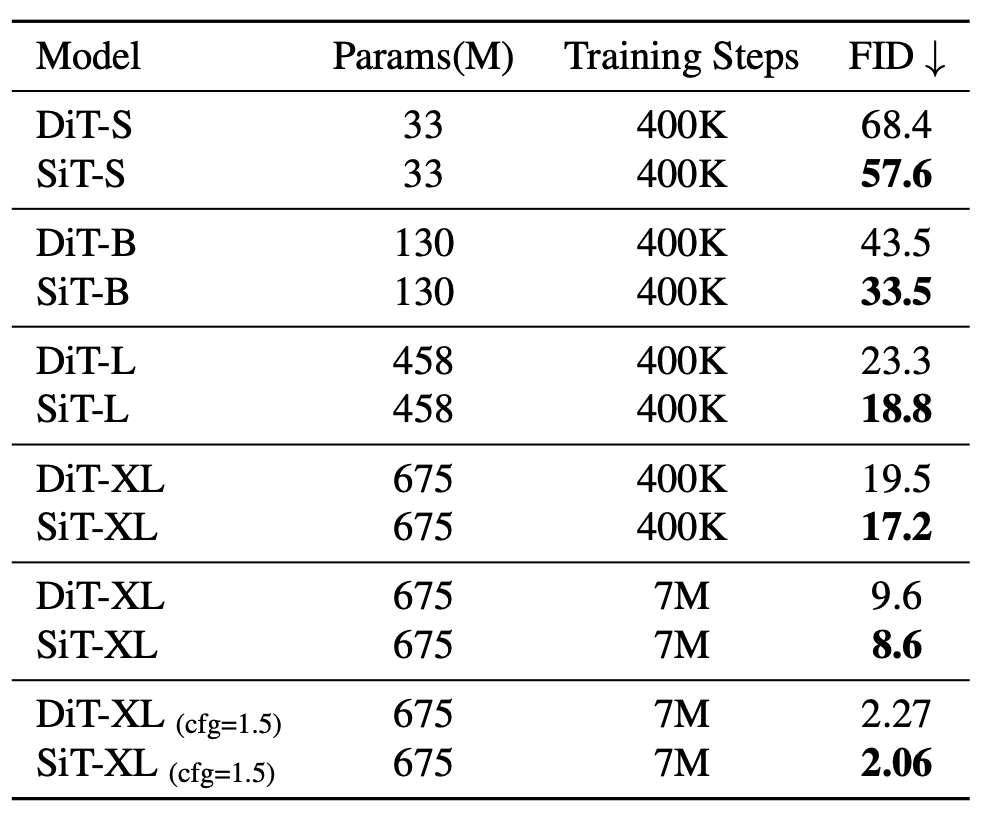
他们通过设计空间中的一系列正交步骤,逐渐地从 DiT 模型过渡到 SiT 模型来解答这一问题。同时仔细评估了每个远离扩散模型的举措对性能的影响。
研究者发现,插值和采样器对性能的影响最大。当将插值(即分布路径)从方差保留切换到线性以及将采样器从确定性切换到随机性时,他们观察到了巨大的改进。

对于随机采样,研究者表明扩散系数不需要在训练和采样之间绑定,在推理时间方面可以有很多选择。同时确定性和随机采样器在不同的计算预算下各有其优势。
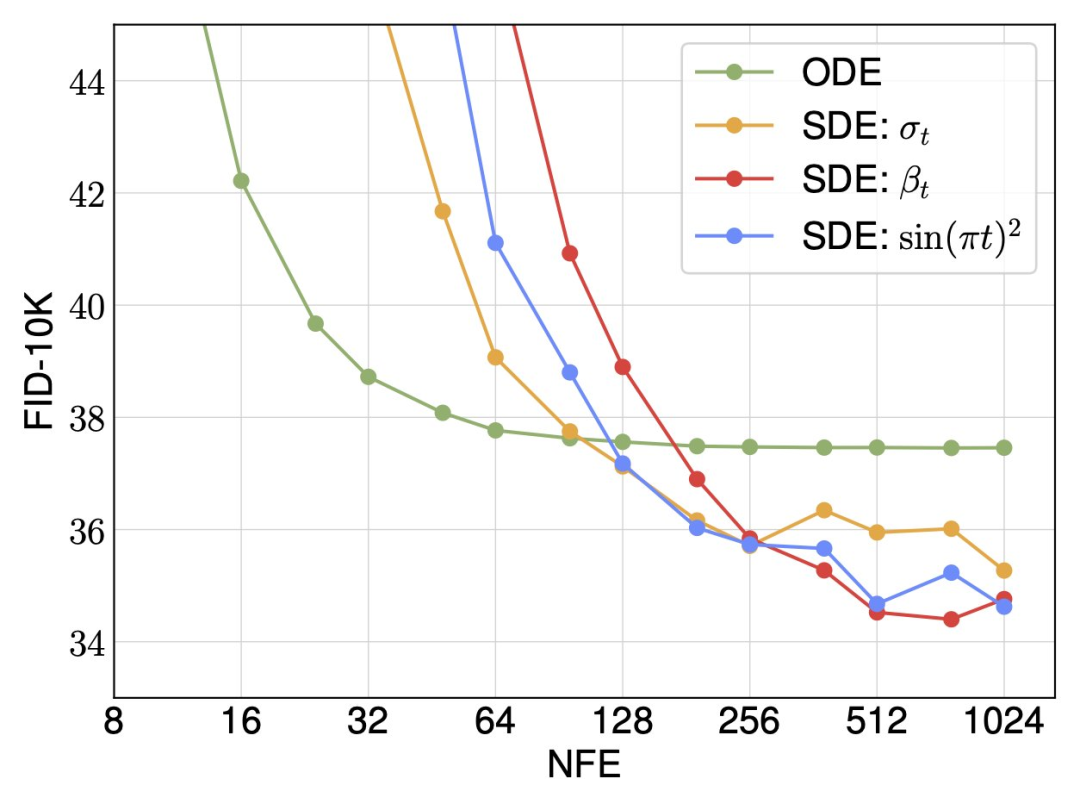
最后,研究者将 SiT 描述为连续、速度可预测、线性可调度和 SDE 采样的模型。与扩散模型一样,SiT 可以实现性能提升,并且优于 DiT。
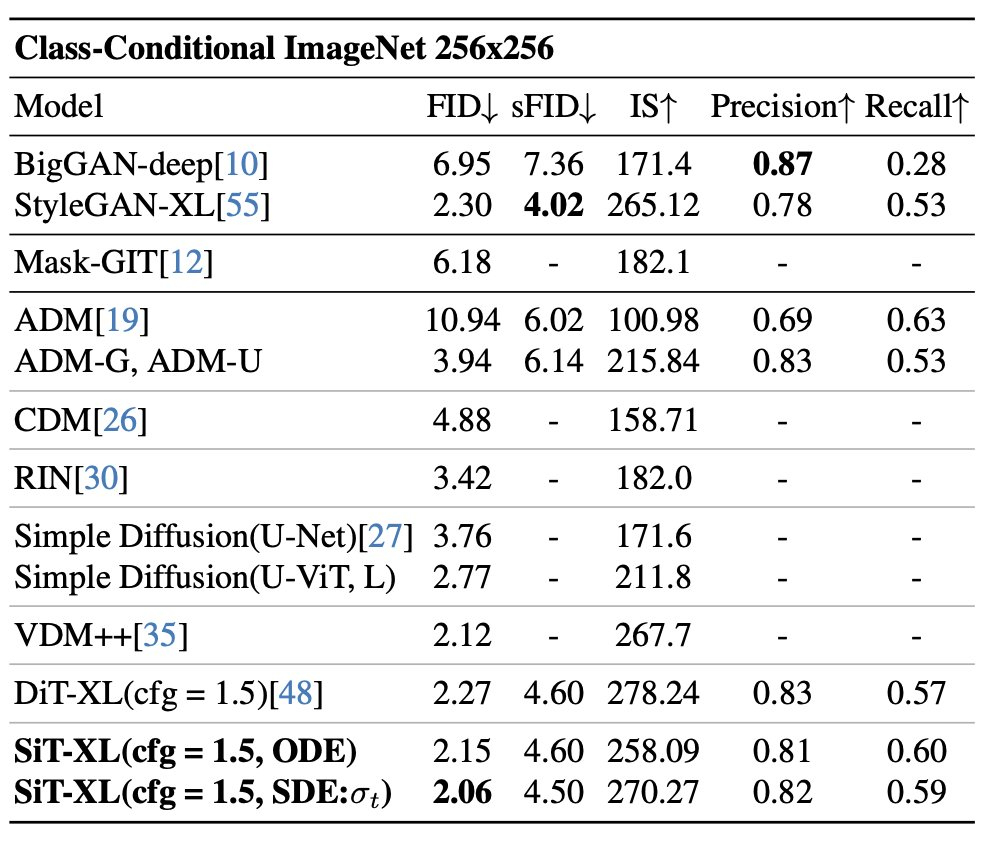
更多关于 DiT 和 SiT 的内容请参阅原始论文。














暂无评论内容