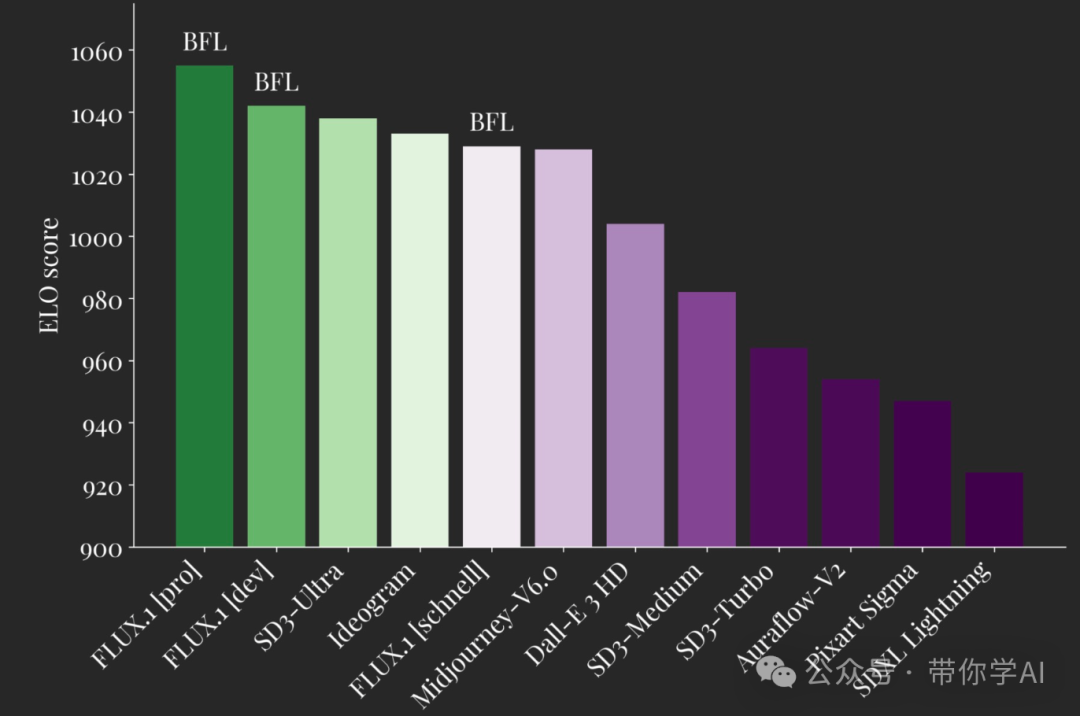
就在Midjourney进行大更新的第二天,开源图像生成领域迎来了新的黑马—FLUX.1。这款新模型不仅声称性能超越DALL·E3、Midjourney V6等闭源模型,还大幅领先于开源的SD3系列。FLUX.1可以准确生成人手和手指,这一问题一直是AI图像生成模型的一大挑战,而FLUX.1在这方面取得了突破性进展。(在线访问和Github以及ComfyUI在文章底部)FLUX.1的创始人Robin Rombach是扩散模型领域的权威专家,他曾领导了Stable Diffusion系列项目。今年3月,由于Stability AI内部动荡,Robin选择离开。经过四个月,他带着新的开源大模型平台FLUX.1重磅回归。FLUX.1一亮相就获得了由Andreessen Horowitz领投的3200万美元种子轮融资,这无疑为其未来发展注入了强劲动力。FLUX.1模型家族包括三个变体:FLUX.1 [pro]商业用途、FLUX.1 [dev]学术研究和FLUX.1 [schnell]本地开发,分别针对商业应用、学术研究和个人使用进行了优化。

 模型特性
模型特性
大规模参数:拥有12B(120亿)参数,是迄今为止最大的开源文本到图像模型之一。
多模态架构:基于多模态和并行扩散Transformer块的混合架构,提供强大的图像生成能力。
图像质量:在视觉质量、提示词遵循、大小/纵横比可变性、字体和输出多样性等方面超越了其他流行的模型。
技术创新:引入了流匹配训练方法、旋转位置嵌入和并行注意力层,提高了模型性能和硬件效率。
FLUX.1模型采用并行扩散Transformer块,通过高效处理序列数据,增强了信息编码和解码能力。使用流匹配训练方法简化了训练过程并提高生成质量,同时引入旋转位置嵌入技术,提升了图像细节表现。并行注意力层使模型能同时关注输入序列中的多个部分,捕捉长距离依赖关系,提高生成图像的准确性。

所有 FLUX.1 型号都支持不同的长宽比和分辨率(10 万和 200 万像素),如下图所示。

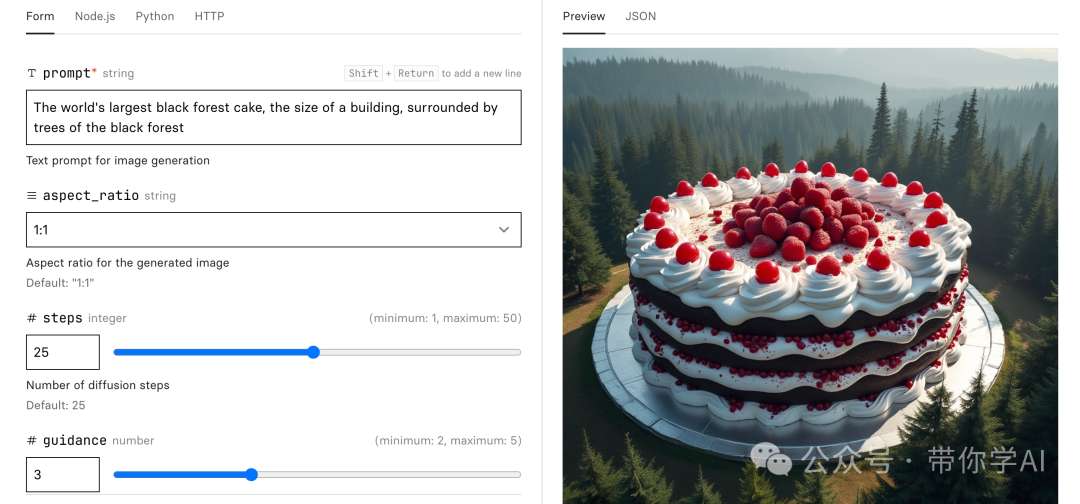
以replicate为例,可以看到左侧可以调整提示词、比率以及输出质量等。
LUX.1 在文字生成、复杂指令遵循和人手生成上具备优势。
 具体示例+提示词
具体示例+提示词
超现实:abstract chrome 80s scifi automaton, airbrush

文字:
![]()

真实人物:kyle sleeping on the couch

动物:professional photograph of a lynx lit by moody harsh lighting in the middle of a forest

风景:
















暂无评论内容