
Meta宣布推出其最新的Segment Anything Model 2 (SAM 2),这是首个用于实时、可提示的图像和视频对象分割的统一模型。SAM 2在图像分割精度和视频分割性能方面超越了初代模型,并将交互时间减少了三倍,同时具备零样本泛化能力,能够分割以前未见过的视觉内容。
在SAM发布之前,创建准确的对象分割模型需要高度专业的技术人员和大量注释数据。SAM通过提示技术简化了这一过程,直接应用于多种现实世界的图像分割任务。马克·扎克伯格在公开信中指出,开源人工智能具有提升生产力、创造力和生活质量的潜力,并能加速经济增长和推动医学科学研究。
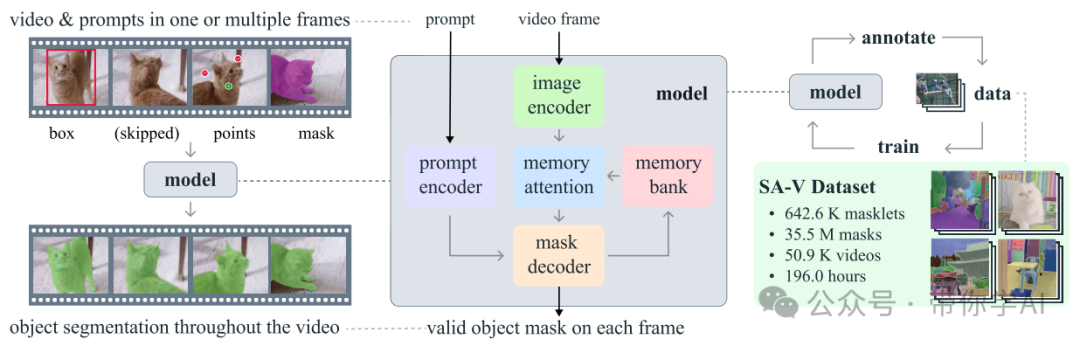
此外,Meta开源了SA-V数据集,其视频数量是现有最大视频分割数据集的4.5倍,注释数量是53倍,包含约51,000个真实视频和超过600,000个masklet。(Github和官网体验在文章底部)
技术原理
Segment Anything Model 2 (SAM 2)是解决图像和视频中可提示视觉分割问题的基础模型。将SAM扩展至视频,将图像视为单帧视频。该模型采用一种简单的转换器架构,配备了用于实时视频处理的流内存。同时,包括图像编码器、记忆编码器、记忆注意力模块、提示编码器和掩模解码器等模块。
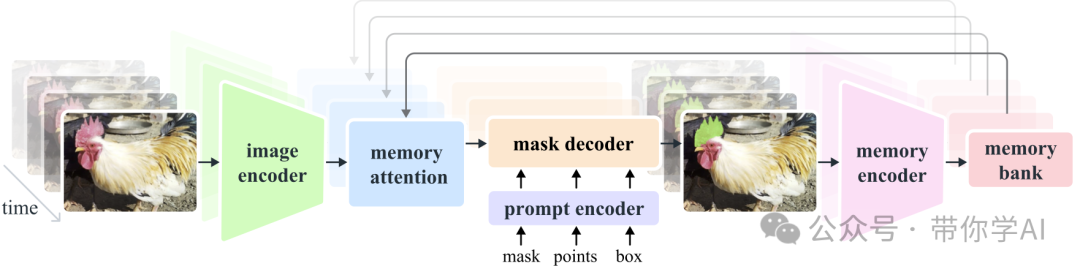
图像编码器使用流式处理方法处理视频帧,基于预训练的Hiera模型提供多尺度特征表示,显著提升处理效率。记忆编码器和记忆注意力模块是SAM 2的重要创新,前者将模型预测和用户交互编码为记忆,后者利用这些记忆增强当前帧的特征表示,从而更好地捕捉目标对象的动态变化。
提示编码器能够接受点击、框选或遮罩等不同类型的提示,并将其转化为模型理解的嵌入表示。掩模解码器则使用双向transformer块更新提示和帧嵌入,确保模型输出有效掩模。
实际应用
SAM 2 将图像分割扩展至视频,通过记忆机制和提示优化掩码预测,利用流式架构实时处理视频帧,支持任意长视频的精确分割预测。
SAM 2 在摄像机视点变化、长时间遮挡、场景拥挤或视频过长时可能丢失物体跟踪,但通过交互设计和手动单击校正可恢复目标物体。
对于复杂的快速移动物体,SAM 2 有时会错过细节且预测不稳定,添加提示只能部分缓解;训练时未对预测抖动施加惩罚,改进该功能可提升精细结构定位的实际应用。
在工业界,SAM 2 提供快速注释工具,助力下一代计算机视觉系统,如自动驾驶汽车。其实时推理能力将激发新型对象选择和交互方式。内容创作者可利用 SAM 2 进行创意视频编辑,提升生成视频模型的可控性。此外,SAM 2 在科学和医学研究中也大有作为,如无人机监测濒危动物或定位腹腔镜摄像机中的区域。














暂无评论内容