
7 月 30 日,OpenAI 推出了 ChatGPT 高级语音模式,用户首次能够体验 GPT-4o 超逼真语音交互。目前,Alpha 版本面向于小部分 ChatGPT Plus 用户,秋季之后将逐步推广至所有 Plus 用户。
OpenAI 表示,春季更新期间演示的视频和屏幕共享功能并不包括在 Alpha 版本在内,而是在后面推出。
ChatGPT 高级语音模式不同于此前的语音模式,原有的音频解决方案使用了三个独立的模型:一个用于将用户的语音转换为文本,然后由 GPT-4 处理 Prompt,然后由第三个模型将 ChatGPT 生成的文本转化为语音。
GPT-4o 是一个多模态模型,能够在没有其他模型辅助的情况下处理这些任务,因为在体验上将显著降低对话的延迟。
OpenAI 还透露,GPT-4o 可以感知用户声音中的情绪语调,包括悲伤、兴奋或者唱歌;目前,Alpha 组的用户将在 ChatGPT 中收到提醒,并将收到一封邮件介绍如何使用。
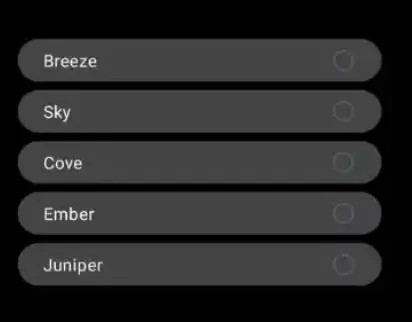
据悉,高级语音模式种的预设声音将仅限 Juniper、Breeze、Cove 以及 Ember,这些都是与付费配音演员合作制作的,而 5 月份演示的 Sky 声音将不再可用。
OpenAI 发言人 Lindsay McCallum 表示,ChatGPT 目前还无法模仿其他人的声音,无论是个人还是公众人物,并且会屏蔽与这四种预设声音不同的输出。
此外,OpenAI 引入了新的过滤方式来避免模型生成受版权保护的音频,从而造成法律纠纷。
自发布 Demo 以来,OpenAI 已经与 100 多名使用 45 种不同语言的外部红队成员一起测试了 GPT-4o 语音功能,相关的安全措施报告将在 8 月初发布。
© 版权声明
THE END
















暂无评论内容