就在刚刚,Meta 突然发布并开源了新一代对象分割模型——SAM 2,这是第一个用于图像和视频中实时、可提示的对象分割的统一模型。
据介绍,SAM 2 可以分割任何视频或图像中的任何物体,即使从未见过,因而可以用于现实生活中的任意场景。相比于上一代模型,SAM 2 的图像分割更准确,且速度快了 6 倍。
值得一提的是,SAM 2 的输出结果可与生成式视频模型结合使用,从而创建出新的视频效果,进而催生出新的创意应用。
同时,SAM 2 还能帮助加快视觉数据标注工具的开发,从而建立更好的计算机视觉系统。
此外,SAM 2 现已在 Apache 2.0 下发布,从现在开始,任何人都可以使用 SAM 2 来构建自己的体验。
SAM 2 是如何被构建的?
Meta 团队首先开发了可提示的视觉分割任务,并设计了一个能够执行此任务的模型,即 SAM 2。他们使用 SAM 2 帮助创建一个视频对象分割数据集(SA-V),其规模比目前存在的任何数据集都要大一个数量级,并使用它来训练 SAM 2 以实现最先进的性能。
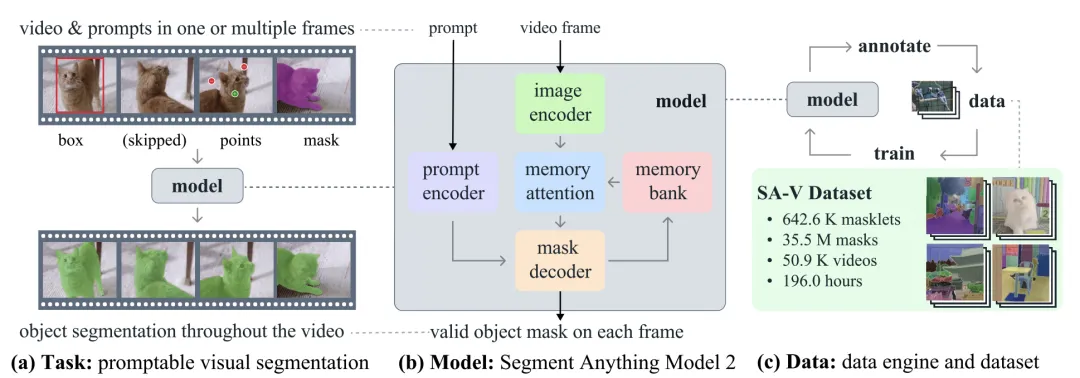
图 | 研究团队引入了分段任意模型 2 (SAM 2),用他们的基础模型(b)来解决提示视觉分割任务(a),该模型是在通过他们的数据引擎(c)收集的大规模 SA-V 数据集上训练的。
可提示的视觉分割
研究团队设计了一个可提示的视觉分割任务,将图像分割任务泛化到视频领域。SAM 经过训练,可以接受图像中的点、框或遮罩作为输入来定义目标对象并预测一个分割遮罩。对于 SAM 2,团队训练它接受视频中任何一帧的输入提示来定义要预测的时空遮罩(masklet)。SAM 2 根据输入提示立即预测当前帧的遮罩,并随着时间的推移将其传播,以生成目标对象在所有视频帧中的 masklet。一旦预测了初始的 masklet,就可以通过在任何帧向 SAM 2 提供额外的提示来迭代地细化它。这可以重复进行,直到获得所需的 masklet。
图像和视频分割的统一架构
研究团队采用了流式架构,这是 SAM 到视频领域的自然泛化,逐个处理视频帧,并存储有关分割对象的信息。在处理每个新帧时,SAM 2 使用记忆注意力模块来关注目标对象的先前记忆。这种设计允许实时处理任意长度的视频,这对于收集 SA-V 数据集时的标注效率以及实际应用(例如在机器人技术中)都非常重要。
SAM 引入了在分割图像中的对象存在模糊性时输出多个有效 masklet 的能力。例如,当一个人点击自行车轮胎时,模型可以将这个点击解释为仅指轮胎或整个自行车,并输出多个预测。在视频中,这种模糊性可以跨越视频帧。例如,如果在一帧中只看到轮胎,那么点击轮胎可能仅与轮胎相关,或者随着后续帧中更多自行车部分变得可见,这个点击可能原本是针对整个自行车的。为了处理这种模糊性,SAM 2 在视频的每一步都创建多个 masklet。如果进一步的提示没有解决模糊性,模型将选择置信度最高的 masklet,以在视频中进一步传播。
在图像分割任务中,给定一个正提示,总有一个有效的对象可以在帧中分割。在视频中,可能由于对象被遮挡或从视野中消失,特定帧上可能不存在有效的对象。为了适应这种新的输出模式,他们增加了一个额外的模型输出(“遮挡头”),用来预测感兴趣的对象是否存在于当前帧上。这使得 SAM 2 能够有效地处理遮挡。
SA-V:构建最大的视频分割数据集
为了收集一个大型且多样化的视频分割数据集,研究团队构建了一个数据引擎,利用与人类标注员互动的模型循环设置。标注员使用 SAM 2 在视频中交互式地标注 masklet,然后使用新标注的数据反过来更新 SAM 2。多次重复这个循环,以迭代地改进模型和数据集。
研究团队发布的 SA-V 数据集包含的标注数量比现有视频对象分割数据集多一个数量级,视频数量大约多 4.5倍。
SA-V 数据集的亮点包括:
在大约 51000 个视频上超过 600000 个 masklet 标注。
视频展示了地理多样性强的真实世界场景,收集自 47 个国家。
标注涵盖了整个对象、对象部分,以及对象被遮挡、消失和重新出现的挑战性实例。
效果怎么样?
为了创建一个用于图像和视频分割的统一模型,研究团队将图像视为单帧视频,通过这种方式在图像和视频数据上联合训练 SAM 2。研究团队利用去年作为 Segment Anything 项目一部分发布的 SA-1B 图像数据集、SA-V 数据集以及额外的内部许可视频数据集。
该模型的主要亮点包括:
SAM 2 在 17 个零样本视频数据集上的交互式视频分割性能显著优于先前的方法,并且所需的交互时间大约减少了三倍。
SAM 2 在 23 个数据集的零样本基准测试套件上的表现超过了 SAM,同时速度提高了六倍。
与之前的最新模型相比,SAM 2 在现有的视频对象分割基准测试(DAVIS、MOSE、LVOS、YouTube-VOS)中表现出色。
使用 SAM 2 进行推理的感觉几乎是实时的,大约每秒 44 帧。
在视频分割标注中,使用 SAM 2 的循环比使用 SAM 的手动逐帧标注快 8.4 倍。
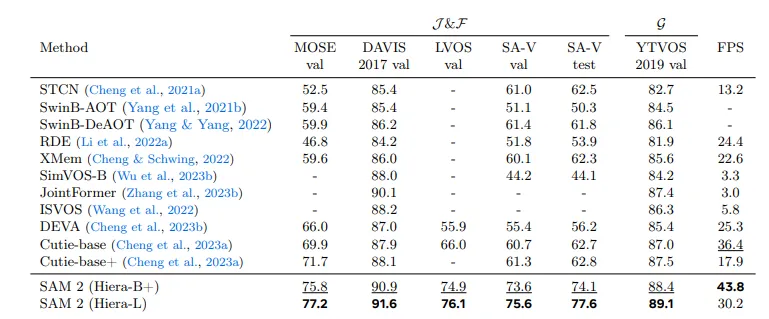
图 | 与之前的模型相比,SAM 2 在现有的视频对象分割基准测试中表现出色。
除此之外,为了衡量 SAM 2 的公平性,研究团队还对模型在不同人口群体上的性能进行了评估。结果显示,在感知性别上进行视频分割时,模型的性能差异最小,在评估的三个感知年龄组(18-25岁、26-50岁和50岁以上)之间的差异也很小。
不足与展望
虽然 SAM 2 在分割图像和短视频中的对象时表现出色,但在挑战性场景中,模型的性能还可以进一步改进。
首先,SAM 2 可能在遇到相机视角的剧烈变化、长时间的遮挡、拥挤场景或长视频时,会丢失对象的跟踪。
为了实际缓解这个问题,研究团队设计了模型以实现交互性,并允许在任何帧中进行手动干预,通过纠正点击来恢复目标对象。
当目标对象只在某一帧中指定时,SAM 2 有时会混淆对象,无法正确分割目标。在许多情况下,通过在后续帧中添加额外的细化提示,可以完全解决此问题,并在整个视频中获取正确的 masklet。
其次,尽管 SAM 2 支持同时分割多个单独对象的能力,但模型的效率会大幅下降。在内部,SAM 2 分别处理每个对象,只使用共享的每帧嵌入,没有对象间的通信。虽然这简化了模型,但引入共享的对象级上下文信息可能会帮助提高效率。
此外,对于复杂快速移动的对象,SAM 2 有时会错过细微细节,并且跨帧的预测可能不稳定。在同一帧或额外帧中添加进一步的提示来细化预测只能部分缓解这个问题。改进这一能力可以促进需要精细结构精确定位的实际应用。
最后,虽然研究团队的数据引擎在循环中使用 SAM 2,并且在自动生成 masklet 方面取得了重大进展,但仍然依赖人工标注员进行一些步骤,如验证 masklet 的质量和选择需要纠正的帧。未来的发展可能包括进一步自动化数据标注过程,以提高效率。














暂无评论内容