OpenAI 创始团队成员、特斯拉AI总监Andrej Karpathy最近在推特上发文曝光了大模型的”锯齿状智能”(Jagged Intelligence)。
什么是”锯齿状智能”?

这是Andrej Karpathy最新创造的词,就是说现在最先进的大语言模型(LLM)在某些任务上能力超群,但在另一些看似简单的任务上却蠢得不行。
Karpathy发现,最先进的大语言模型(LLM)表现出一种奇怪的现象:
它们能解决超复杂的数学问题,却在一些傻瓜问题上栽跟头。
说白了就是,有的时候聪明得不得了,有的时候又蠢得要命。
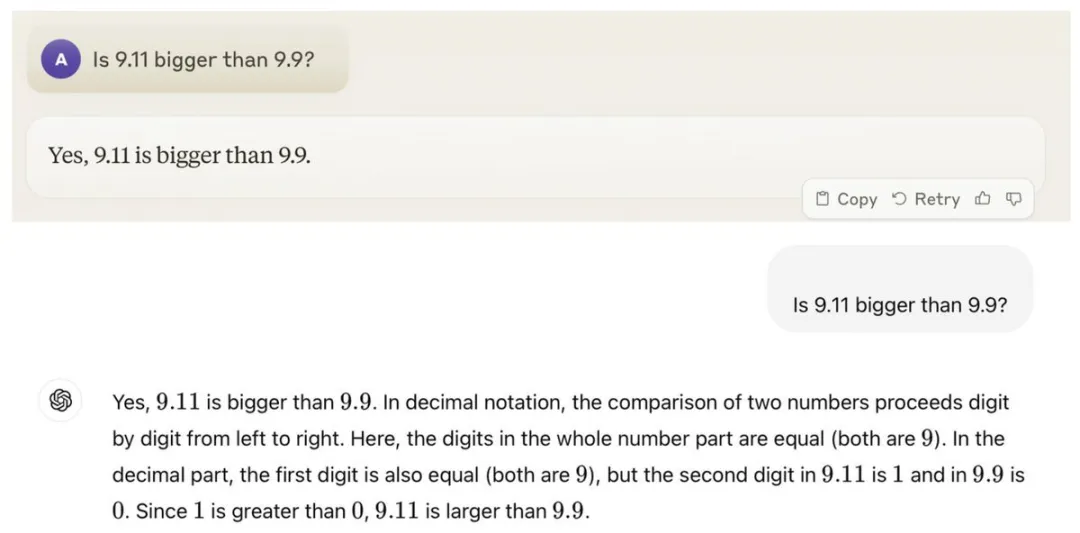
比如前两天,有人问GPT:
9.11和9.9,哪个数字更大?
结果这位”AI顶流”居然说9.11更大!??
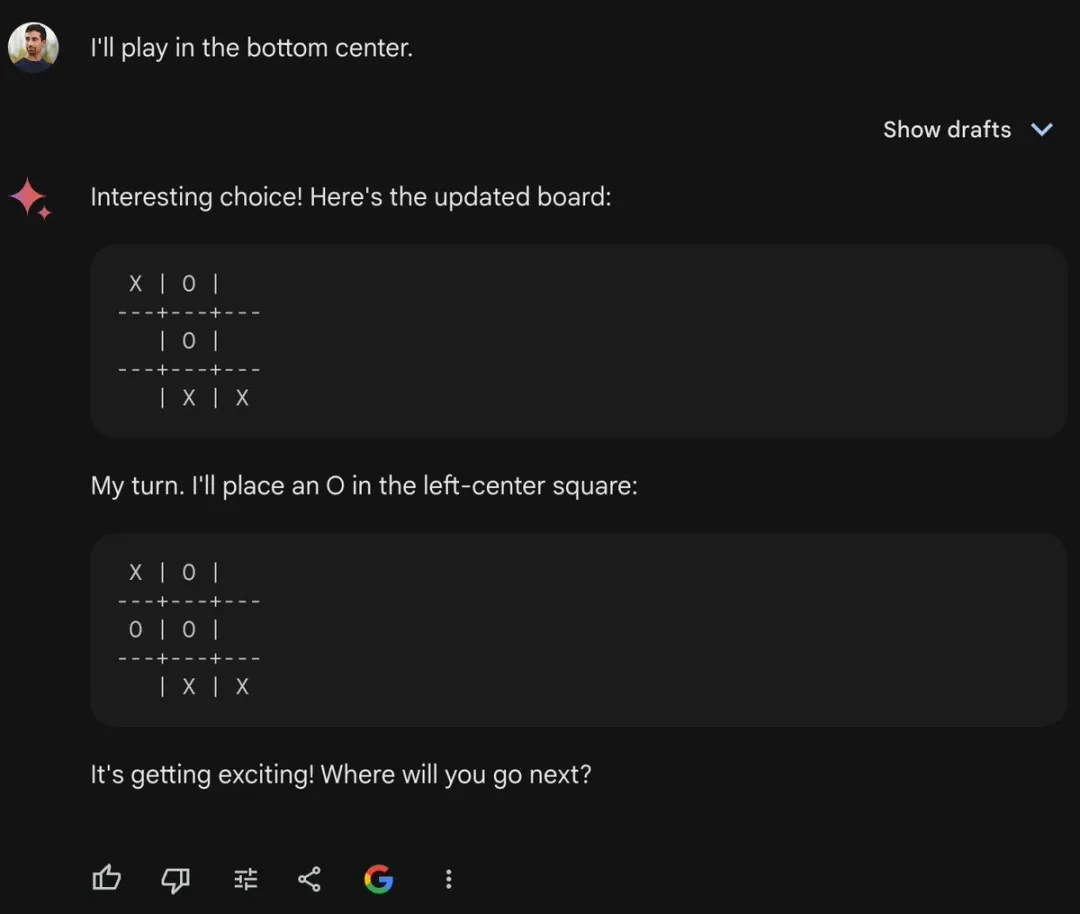
还有人让它下井字棋,结果它下出了一些完全不合逻辑的棋步。
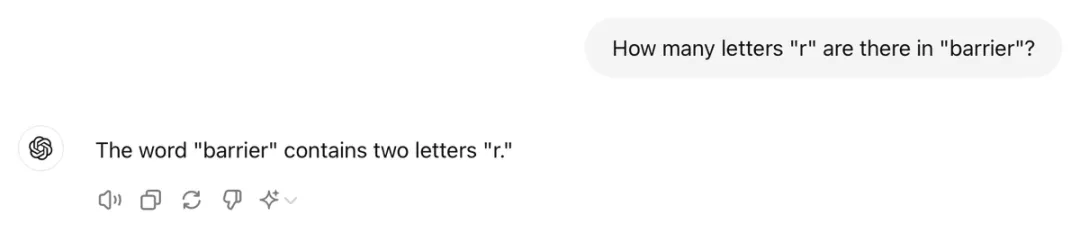
更离谱的是,让ChatGPT-4数一下”barrier”这个单词里有几个”r”,它居然说是2个!?
这不是闹笑话吗?

但偏偏,同一个模型又能识别出成千上万种狗狗或花朵的品种👆。
因此Karpathy把这种现象称为”锯齿状智能“。
有些任务完成得超乎人类想象(按人类标准来说),有些任务却又失败得一塌糊涂(同样按人类标准)。
而最难搞的是,你很难预测它在哪些任务上会出错。
这就和人类的智力发展不太一样了。我们从小到大,各方面能力基本都是同步提高的。
Karpathy还举例说,Llama 3.1论文中关于减少”幻觉”的部分就是一个好例子。
那么,这个”参差智能”问题到底该怎么解决呢?
Karpathy认为,上面这些并不是根本性的问题。他表示,解决这些问题需要在整个技术栈上做更多工作,不仅仅是简单地扩大规模。
他特别提到,目前的大模型缺乏”认知自我认知”能力。这需要在模型训练后采用更复杂的方法,而不是简单地”模仿人类标注者并做大“这种到目前为止一直在用的naive方案。
有网友评论说:
也许某种形式的自动化上下文优化(类似RAG)可以稳健地解决其中一些问题。比如,将LLM路由到上下文生成器以添加必要的上下文。
这位网友还观察到:
LLM急于回答问题的倾向(可能是RLHF或人类偏好训练的产物)正在影响其在回答之前思考和分解某些问题的能力。
Jack(@jack_sometrades) 则从训练数据的角度给出了解释:
如果LLM只是在插值其训练数据,那这种现象就说得通了吧?
KayN(@theonekayn) 也持类似观点:
LLM在你举的那些表现不好的例子中出现的问题,是它们所训练的数据导致的结果。显然,它们有能力用代码表达出一个单词中”r”的数量的解决方案,只是当它们被限制在自然语言中时就做不到了。
不过Ryan Gomes(@ryangomes)认为这反而证明了LLM的本质:
当你把LLM理解为对其训练集的近似检索时,这一切就开始变得更有意义了。
Karpathy 认为,目前在实际应用中使用大模型时还是要小心谨慎。他建议:
- 将大模型用于它们擅长的任务
- 警惕那些可能出问题的”锯齿边缘”
保持人工监督
最后,网友KIFF(@Liff_82) 还分享了一个有趣的现象:
最搞笑的是,它们总是告诉你时钟显示的是10:10 – 然后它还能同时向你解释为什么LLM会犯这个错误。

那么问题来了,你发现大模型还有哪些”又聪明又傻”的表现?














暂无评论内容