第一次开源模型革命,突然就兴起了……
Llama3.1发布后,Meta还沉浸在强烈的社会反响中时,法国的Mistral AI团队突然扔出王炸:它们的最新开源模型Mistral Large 2 。
而Llama3.1刚坐了一天王位,就被它踢下去了……
80余种编程语言训练,顶尖函数调用能力
Mistral的AI以代码模型著称,致力于帮助各种编码环境和项目的开发人员。 过去几个Mistral的AI就在80多种编程语言的多样化数据集上进行训练,能精通包括Python、Java、C、C++、JavaScript和Bash在内的绝大部分编程语言。
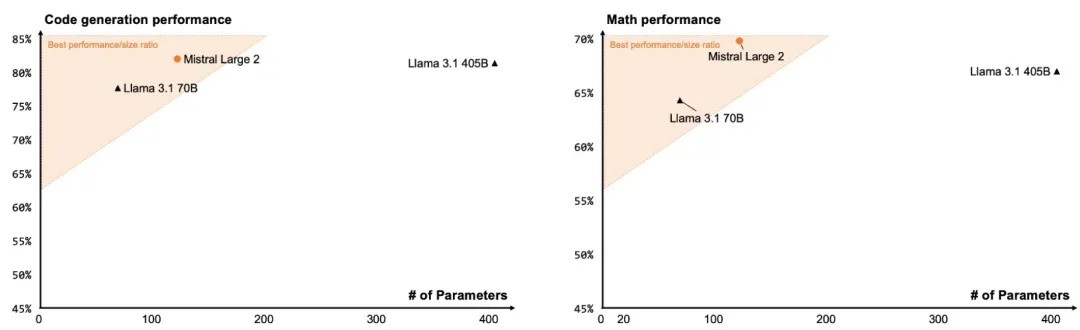
Mistral Large 2也进行了非常大比例的代码训练,性能远优于1代Mistral Large,与GPT-4o、Claude 3 Opus和Llama 3 405B等领先型号的表现不相上下。
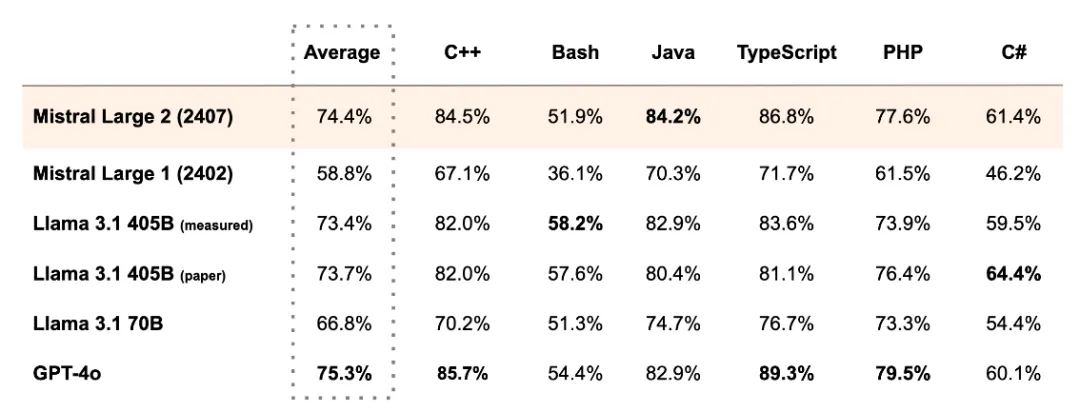
Llama 3.1的一个短板就是human eval数据不尽人意,而Mistral Large 2极大改善了这一点:
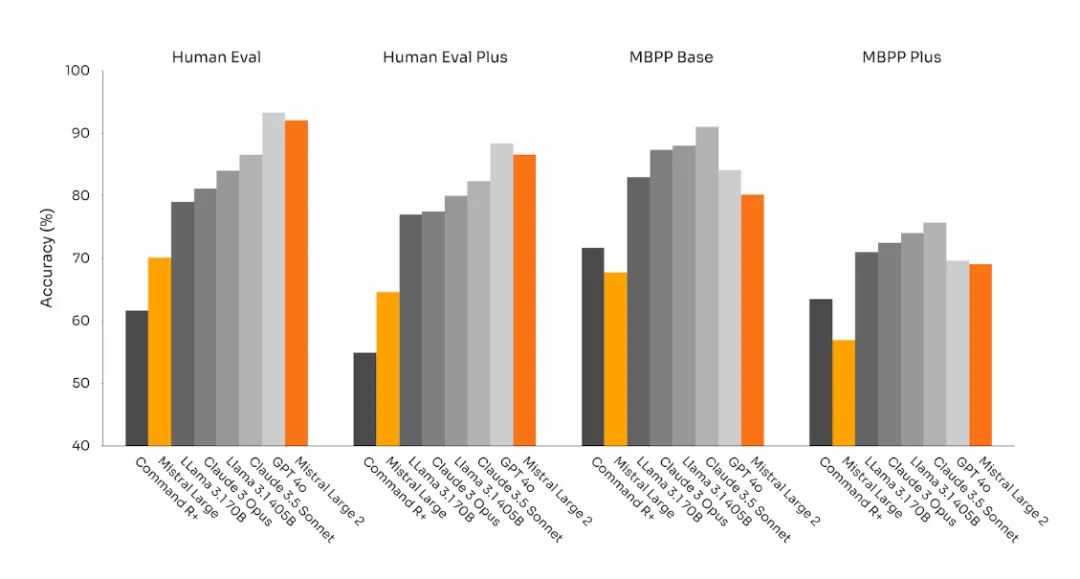
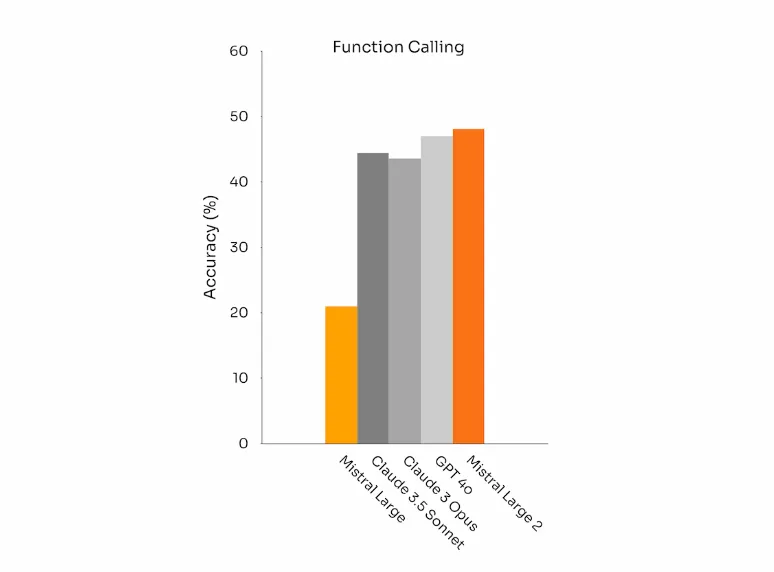
Mistral Large 2还增强了函数调用功能(Function Calling)。经过训练,Mistral Large 2能够熟练执行并行和顺序函数的调用,有望为复杂业务和项目赋能。而Mistral Large 2这一功能甚至打赢了GPT-4o和Claude 3.5 sonnet。
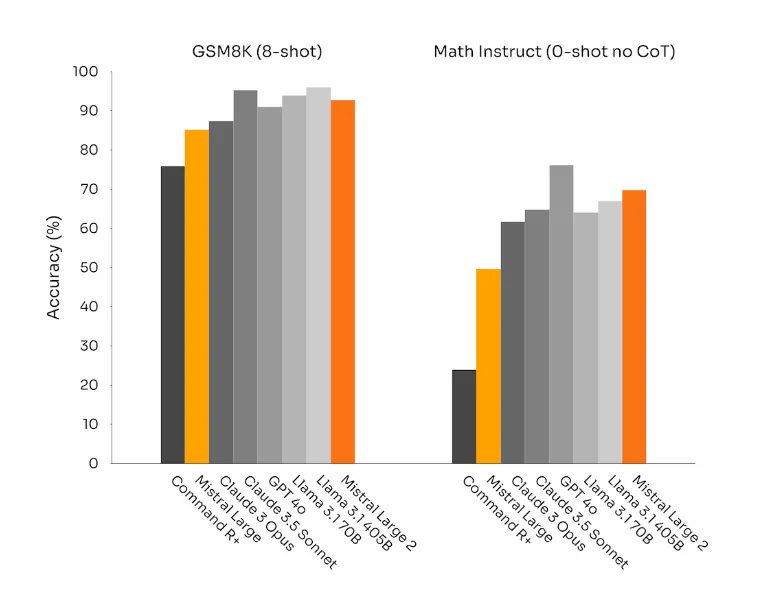
在数学性能上,Mistral Large 2模型也展示了其增强的推理和解决问题的能力。 根据GSM8K和MATH两个基准测试的数据来看,与顶级模型不相上下。
有网友去问Mistral Large 2模型:3.9和3.11哪个大?没想到它居然答对了!

长期以来困扰AI的难题终于被破解了(狗头)。
多语言文本指令优化
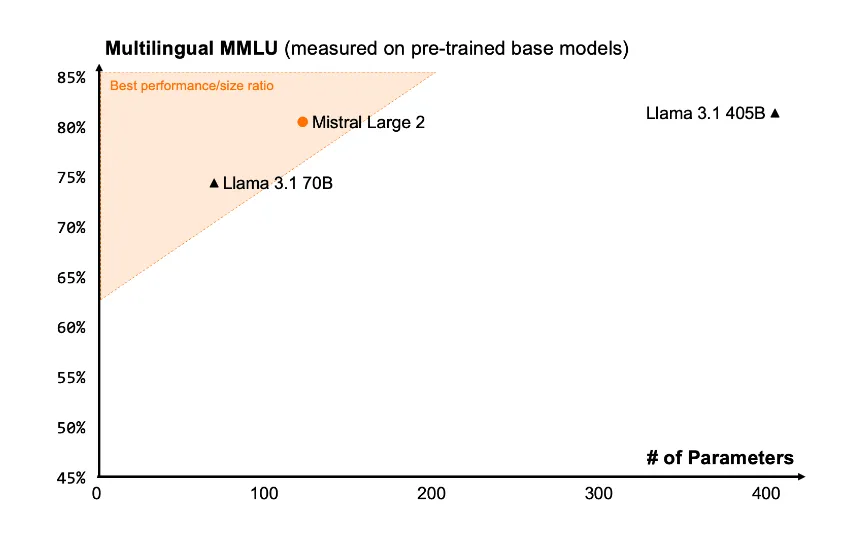
论其大小,Mistral Large 2是一个123b参数的模型,具有128k上下文窗口。预训练版本的MMLU能达到84.0%。
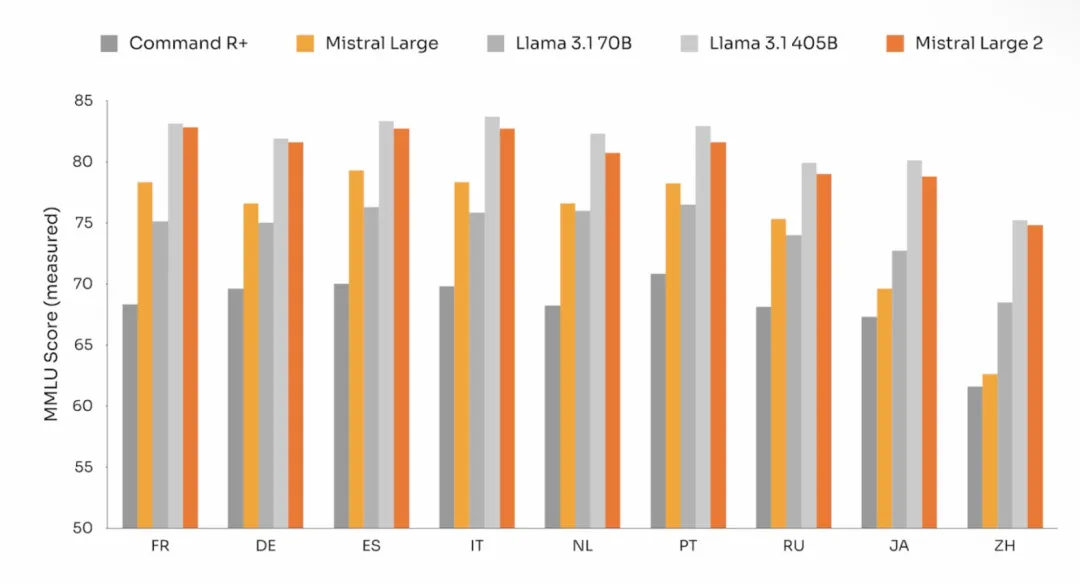
昨天发布的Llama3.1针对八种不同语言进行了文本指令优化,但其中偏偏没有中文。有人吐槽Llama 3.1的中文能力差到还不如去用通义千问。这次Mistral Large 2带上了,包括中文在内,还支持英语、日语、韩语、法语等数十种语言。
据测试,在多语言MMLU上,Mistral Large 2的平均性能明显优于Llama 3.1 70b(高6.3%),与Llama 3 405B相当(低0.4%)。
在对齐和指令功能方面,团队在Mistral Large 2上投入了很多精力。在WildBench、ArenaHard和MT Bench测试中,其性能与当前的顶尖模型相当,而它的优点是文本的平均生成长度明显降低。
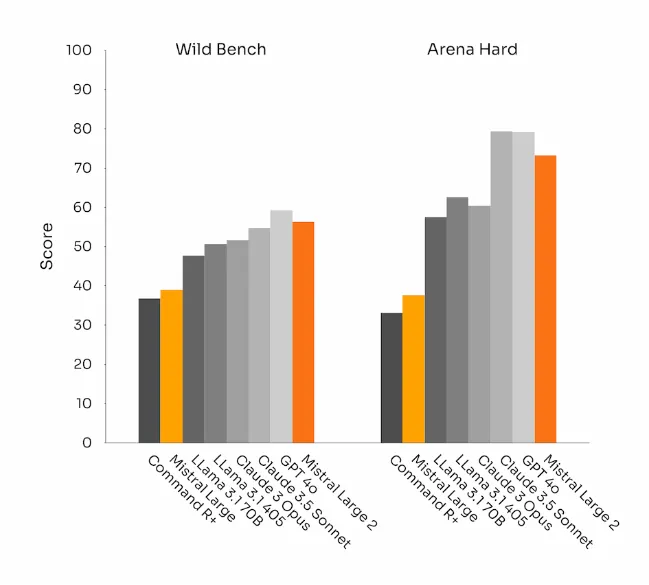
在一些AI的基准测试中,生成冗长的文本往往会提高测试分数。但在业务应用中,文本的简洁性反而至关重要:文本越简洁,交互越快,成本越低。
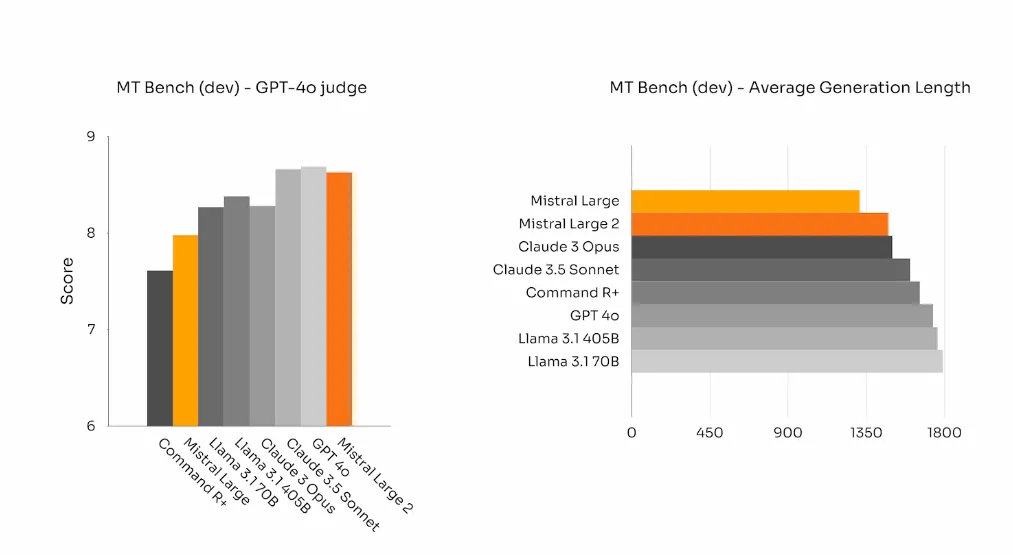
而这么一个强势的模型,其大小竟比Llama 3.1 405b小了3倍! 网友直呼:这简直就是纯纯的黑魔法啊!

Mistral Large 2和Llama 3.1的发布时间只差一天,而相仿的性能下,模型大小还能压缩这么多,简直是后生可畏啊!
开源模型都卷成这个样子了,闭源模型(我不说是谁)还需要继续努力呀。

那明天我们会不会还能看到另一个新的开源模型发布? 我已经按捺不住了。
最后附上Mistral Large 2的Hugging Face链接:
https://huggingface.co/mistralai/Mistral-Large-Instruct-2407














暂无评论内容