edge-tts开源项目介绍
edge-tts是github上高赞的开源文本合成语音TTS项目,该项目截止目前点赞累计点赞达4k! 该项目核心就是调用微软edge的在线语音合成服务,支持40多种语言,318种声音;其中在中文方面,除了普通话外,支持地方口音(比如: 陕西方言、台湾口音、粤语等等),效果可以说是吊打ChatTTS。

下面我给大家实操如何利用edge-tts来实现多种方言的语音合成。
edge-tts语音合成教程
安装对应的环境
!pip install edge-tts
!pip install torchaudio
import edge_tts
print(“edge_tts:”, edge_tts.__version__)
#edge_tts: 6.1.12
查看edge-tts支持的语言
!edge-tts –list-voices # 查看其支持的所有声音
基于命令行端-来生成语音教程
合成对应的香港话、粤语语音-效果展示
获得支持的香港话、粤语语音明细
!edge-tts –list-voices| grep HK # TW
Name: en-HK-SamNeural
Name: en-HK-YanNeural
Name: zh-HK-HiuGaaiNeural
Name: zh-HK-HiuMaanNeural
Name: zh-HK-WanLungNeural
命令行合成生成对应的粤语效果
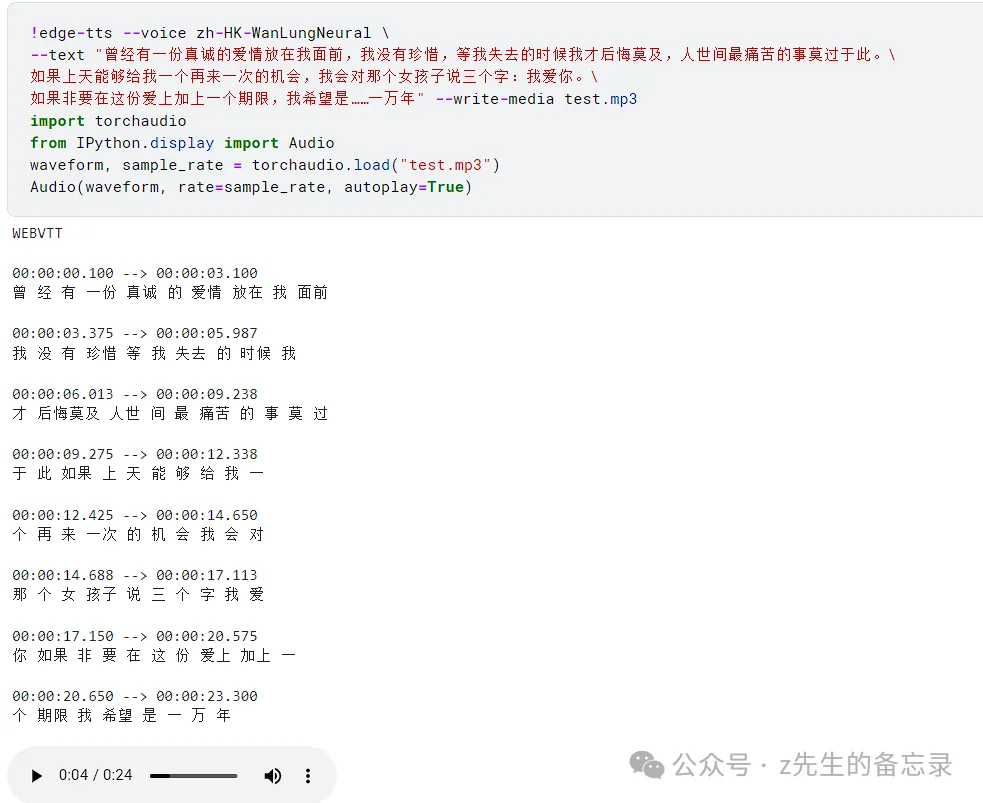
!edge-tts –voice zh-HK-WanLungNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
运行的效果展示:
语音效果如下:
粤语语音展示,z先生的备忘录,24秒
合成对应陕西方言语音-效果展示
!edge-tts –list-voices |grep CN# 查看其支持的中国话
Name: zh-CN-XiaoxiaoNeural
Name: zh-CN-XiaoyiNeural
Name: zh-CN-YunjianNeural
Name: zh-CN-YunxiNeural
Name: zh-CN-YunxiaNeural
Name: zh-CN-YunyangNeural
Name: zh-CN-liaoning-XiaobeiNeural
Name: zh-CN-shaanxi-XiaoniNeural
命令行合成生成对应的陕西方言语音
!edge-tts –voice zh-CN-shaanxi-XiaoniNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
陕西方言语音展示,z先生的备忘录,22秒
合成对应男语音-效果展示
!edge-tts –voice zh-CN-YunyangNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
男语音展示,z先生的备忘录,20秒
合成对应台湾口音-效果展示
获得支持的台湾语音明细
!edge-tts –list-voices| grep TW
Name: zh-TW-HsiaoChenNeural
Name: zh-TW-HsiaoYuNeural
Name: zh-TW-YunJheNeural
合成对应台湾语音
!edge-tts –voice zh-TW-YunJheNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
台湾语音展示,z先生的备忘录,22秒
调整合成语音的语速–rate参数
通过rate参数来设置播放的语速快慢,-30%表示语速变慢30%,+30%表示语速增加30%。
!edge-tts –rate=-30% –voice zh-HK-WanLungNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
减速30效果展示,z先生的备忘录,34秒
调整合成语音的音量–volume
通过–volume参数来设置播放的语速快慢,-60%表示语速变慢60%,+60%表示语速增加60%。
!edge-tts –volume=-50% –voice zh-HK-WanLungNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
调整合成语音的频率–pitch
通过pitch参数来调整合成语音的频率
!edge-tts –pitch=-50Hz –voice zh-HK-WanLungNeural \
–text “曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是……一万年” –write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load(“test.mp3”)
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
减频50hz_效果展示,z先生的备忘录,24秒
基于python代码-来合成语音
import asyncio
import edge_tts
import torchaudio
from IPython.display import Audio
TEXT = “””曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。如果非要在这份爱上加上一个期限,我希望是……一万年”””
VOICE = “zh-HK-HiuGaaiNeural” #选择对应的声音
OUTPUT_FILE = “test.mp3”
communicate = edge_tts.Communicate(TEXT,
VOICE,
rate=’+0%’,
volume= ‘+0%’,
pitch= ‘+50Hz’)
communicate.save_sync(OUTPUT_FILE)
waveform, sample_rate = torchaudio.load(OUTPUT_FILE)
Audio(waveform, rate=sample_rate, autoplay=True)














暂无评论内容