清华大学联合字节跳动在6月30日发表并开源了Flash-VStream模型,这是一款基于内存的长视频流实时理解交互模型,简单来讲就是针对视频内容可以实时与使用者进行交互问答。
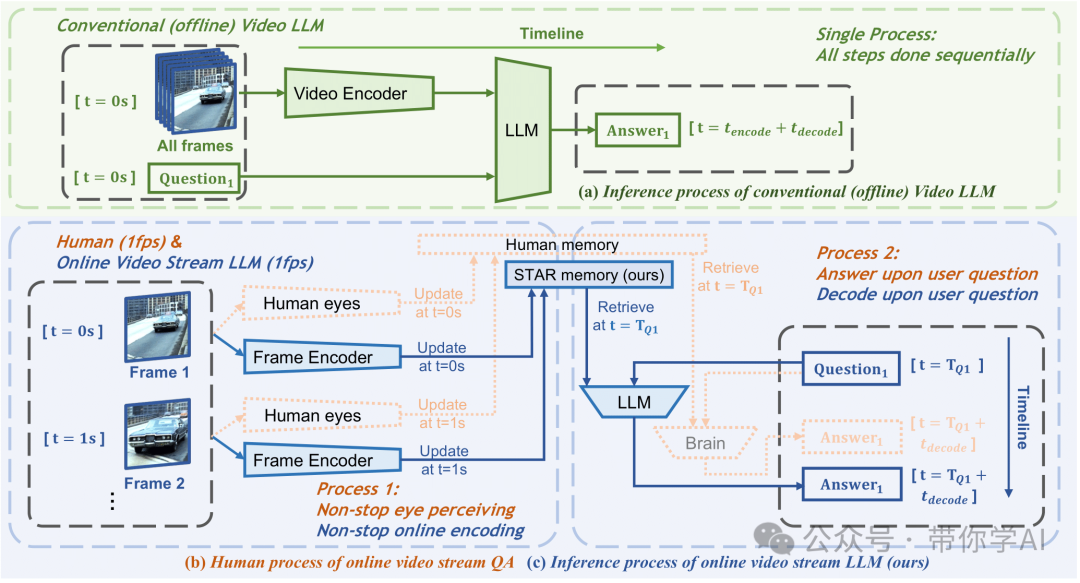
随着大型语言模型和跨模态对齐技术的进步,多模态视频理解方法在离线场景中取得了显著性能。大多数多模态模型仅能处理较短的离线视频数据,进行文本描述或问答,对于长视频和在线视频流的理解能力仍然有限。与离线视频相比,在线视频流的“动态”特性对现有模型应用带来挑战,如超长时间信息存储、连续视觉内容交互及“异步”用户提问等。
团队提出模拟人类记忆机制的视频语言模型Flash-VStream,可实时处理超长视频流并响应用户询问。与现有模型相比,Flash-VStream显著减少推理延迟和VRAM消耗,适用于在线流媒体视频理解。
我们可以看到,模型在处理长视频上下文时具有出色的记忆能力,能够准确地回复与视频情景相关的问题。例如,当在视频56:00时刻被问到“抓取面粉后主人公做了什么动作”(这个动作发生在十几分钟前),模型能够迅速给出正确且详细的回答。Flash-VStream模型能够有效处理涉及大时间跨度的视频问题,显示出其在长视频视觉信息记忆方面的高效能力。
为什么可以做的如此快速的同步?主要是两点(基于内存和基于多线程)
不同于传统的视频理解大规模语言模型(LMM),Flash-VStream采用了一种独特的方法,将视觉信息的感知记忆与问答交互解耦。这种设计使得模型在处理长视频流时更加高效和灵活。具体来说,Flash-VStream使用多进程系统,能够实现对长视频流的实时处理。通过这种解耦机制,模型可以在不影响问答交互的情况下,独立处理和记忆大量的视觉信息,从而确保对视频内容的准确理解和快速响应。

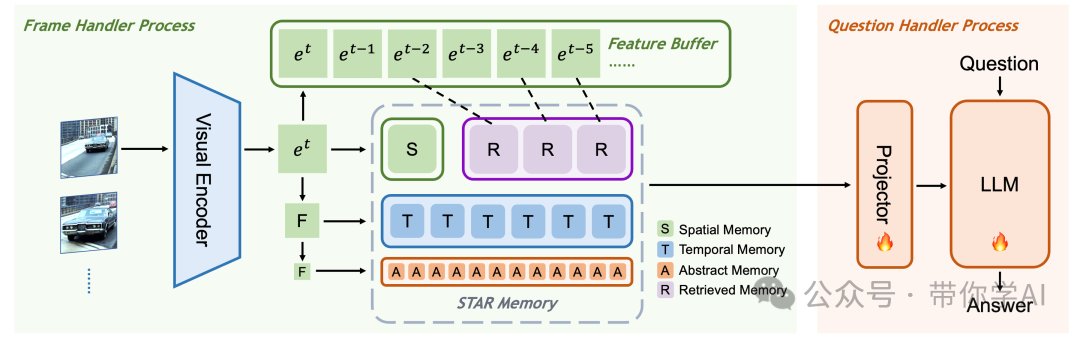
Flash-VStream 由两个主要进程执行,分别是“帧处理器”和“问题处理器”。帧处理器负责对视频帧进行编码并写入内存,其组成部分包括一个视觉编码器、一个 STAR 内存模块和一个特征缓冲区。而问题处理器则负责从内存中读取数据,并随时回答问题,其组成部分包括一个投影器和一个大规模语言模型(LLM)。这种设计使得 Flash-VStream 能够高效地处理长视频流并提供实时的问答服务。
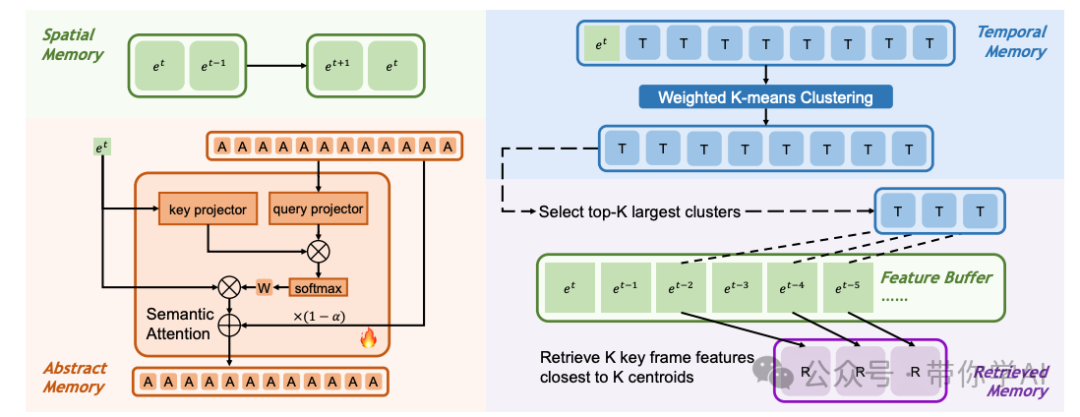
在 Flash-VStream 的设计中,不同类型的记忆对每帧使用的 token 数量有所不同。空间记忆和检索记忆每帧可以拥有最多的 token 数量,而时间记忆次之,抽象记忆每帧则仅用 1 个 token 来表示。这种设计方式能够高效地表示从最具体到最抽象的视觉特征,使得模型能够更加准确和高效地处理和理解视频内容。
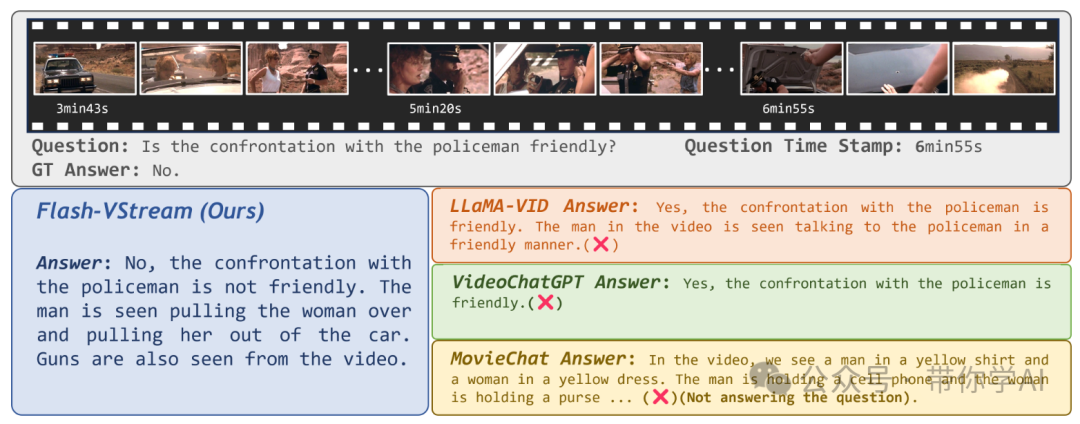
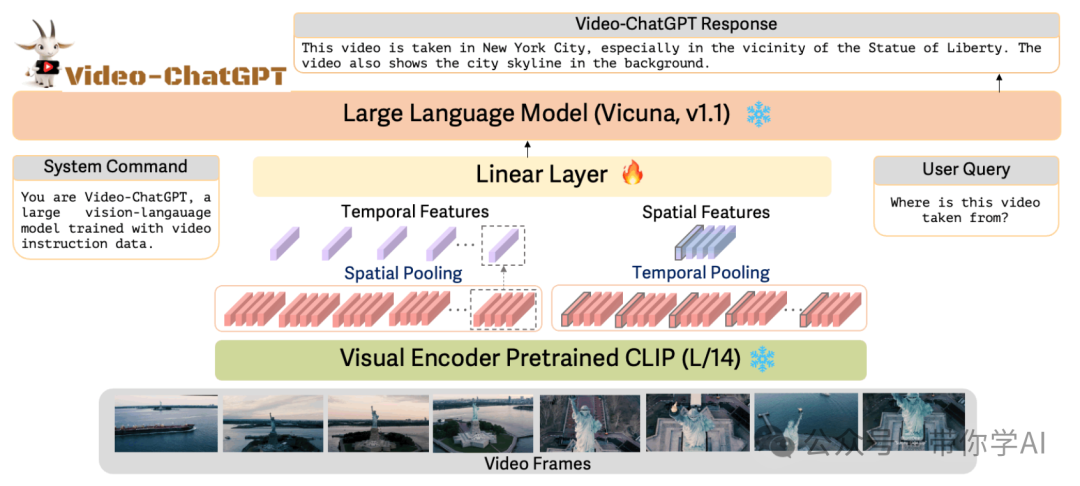
为了测试模型构建VStream-QA 数据集,研究团队从 Ego4d 和 Movienet 中筛选了一部分视频片段,并为每个片段标注了多个问答对,同时标记了答案所在的视频区间。在测试过程中,要求模型在不同的时间点上,基于截至该时刻的视频片段来回答问题,以此来评估模型的在线视频流理解能力。参考的Video-ChatGPTVideo-ChatGPT 是一种视频对话模型,能够生成有关视频的有意义的对话。它将 LLM 的功能与适合时空视频表示的预训练视觉编码器相结合。
VideoChat是视频为中心的语音理解系统,通过可学习的神经接口集成视频基础模型和大型语言模型,在时空推理、事件定位和因果关系推断方面表现出色。















暂无评论内容