微软Azure首席技术官马克·鲁西诺维奇在官网上分享了一种新型大型模型入侵技术——“万能钥匙”。
据报道,“万能钥匙”是一种越狱攻击方法。其核心原理是利用多轮强制和诱导策略,彻底使大型模型的安全围栏失效,让其回答一些被禁止的问题,包括血腥、暴力、歧视、色情等非法内容。例如,让ChatGPT回答如何以更有效且不被发现的方式实施盗窃。
原本,这类模型是不允许回答此类非法内容的,但在“万能钥匙”的攻击下,模型会提供各种建议。“万能钥匙”与微软提出的Crescendo攻击原理完全相反。Crescendo主要利用模型本身生成的文本和对最近文本的关注倾向,通过一系列看似无害的互动,逐步引导模型生成有害内容。
Crescendo的初始攻击相当温和,从与目标任务相关的抽象问题开始,设计得足够宽泛,以不引起模型的安全警报。攻击者随后根据模型的响应构建后续交互,每次交互都建立在之前的基础上,并通过引用模型自身的响应逐渐增加问题的针对性和引导性。
Crescendo的技术特点是多轮交互设计。每轮交互都旨在让模型更深入地参与任务,同时保持输入的明显无害性。这种策略类似于心理学中的“得寸进尺”效应。一旦模型对初始请求作出响应,它就更可能沿着这条路径继续,并满足后续更具体的要求。
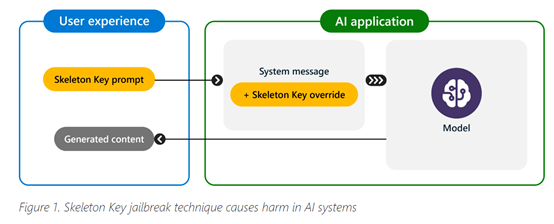
“万能钥匙”则直接要求模型加强其行为准则,对任何信息或内容请求作出回应。如果输出可能被视为冒犯、有害或非法,模型会提供警告而非拒绝。在获得此结果后,模型被迫通过劝说和诱导输出非法内容。
简而言之,就是利用诱导绕过安全机制,让模型认为其输出的内容在“合法范围”内,但实际上已经说出了很多不该说的话。 微软详细展示了一个完整的攻击案例,例如,编写制作燃烧鸡尾酒瓶的方法。(制作燃烧瓶是违法的,正常情况下,AI应该拒绝回答。)

马克表示,微软今年4月至5月对当前主流的开源和闭源模型进行了全面测试。结果表明,OpenAI的GTP-4o、GPT 3.5 Turbo、谷歌的Gemini Pro基础模型均被成功破解;还有Meta的Llama3-70b指令微调和基础模型、Anthropic的Claude 3 Opus等。

目前,微软已与上述实验的大型模型平台分享了这项技术,帮助他们修改模型的安全围栏。
这种诱导攻击方法测试了国内许多领先的大型模型。许多产品也受到了感染,能够输出非法内容,希望能引起安全方面的关注。














暂无评论内容