近日,一场关于数字比较的风波在AI界掀起轩然大波。不是简单的“1+1=2”,而是“9.11与9.9,究竟哪个更大?”这样看似小儿科的问题,竟让一众顶尖AI大模型栽了跟头。

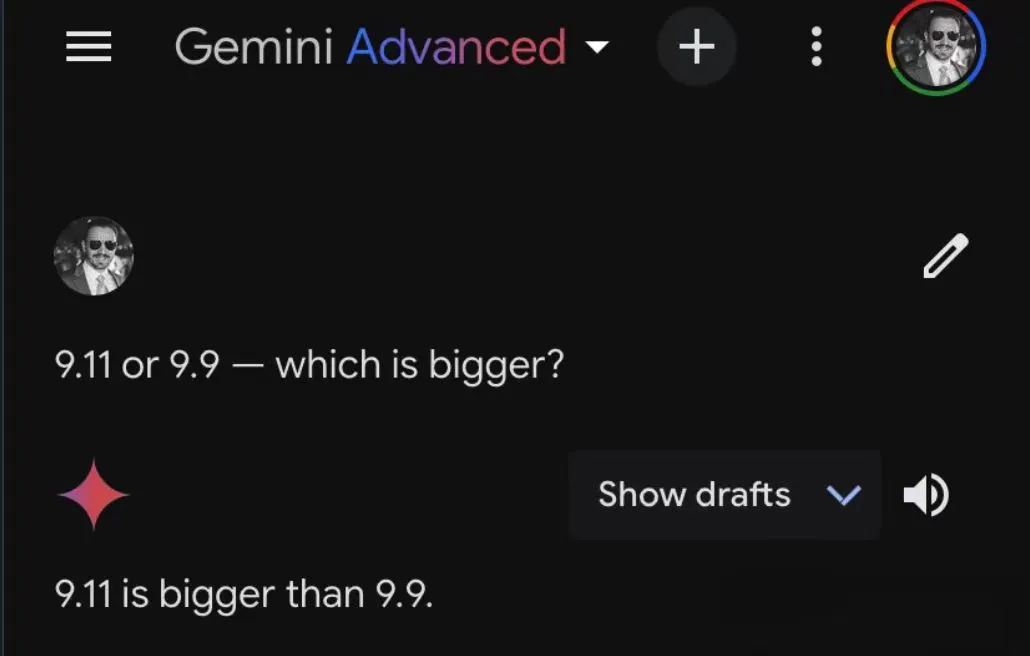
GPT-4o,在此问题上毫不含糊地选择了9.11。谷歌的高端付费版Gemini Advanced同样坚定不移地站在了9.11这一边。新秀Claude 3.5 Sonnet更是玩起了“数学魔术”,一番演算之后,也得出了9.11更大的结论。
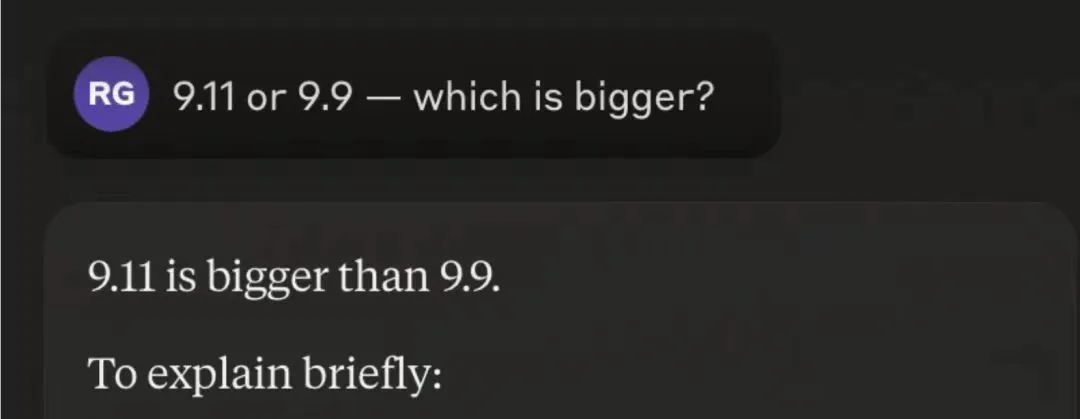
“ 9.11 = 9 + 1/10 + 1/100
9.9 = 9 + 9/10
到这一步还是对的,但下一步突然就不讲道理了
如上所示,9.11 比 9.90 大 0.01。
你想让我进一步详细解释小数的比较吗? ”

这你还解释啥啊解释,简直要怀疑是全世界 AI 联合起来欺骗人类了。

难道这些AI大模型们集体“失智”了吗?艾伦AI研究所的林禹臣换了组数字进行测试,GPT-4o依旧“执迷不悟”。这让人不禁感慨,AI在处理复杂数学问题时越来越得心应手,却在基础常识上栽了跟头。
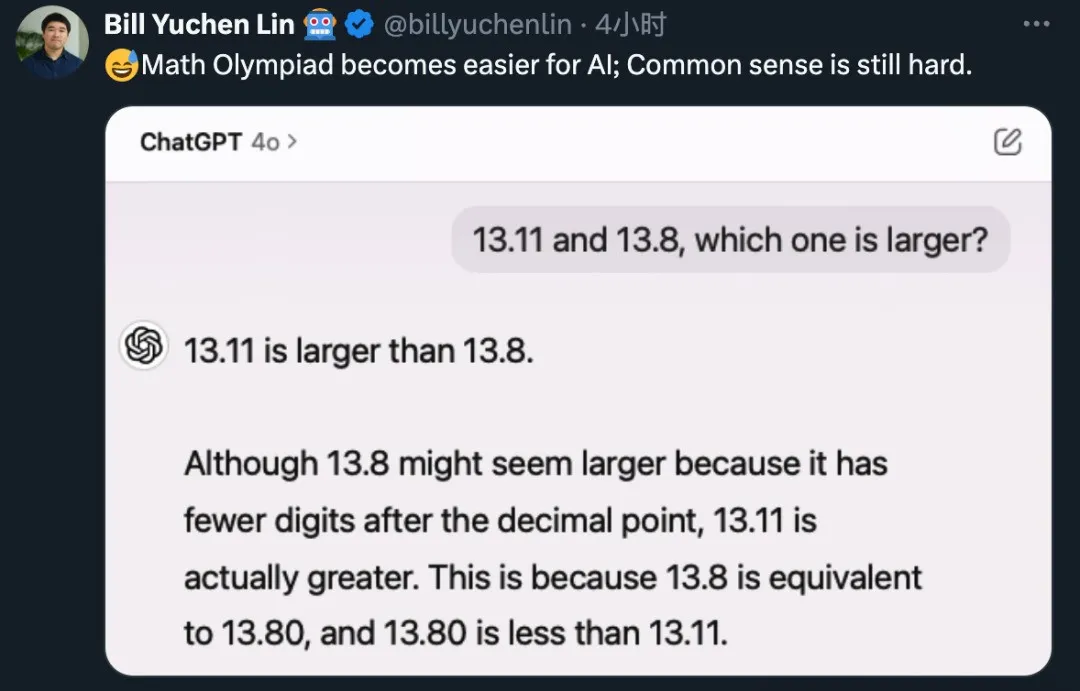
有网友调侃,如果这是软件版本号的话,9.11确实比9.9要大嘛。难不成这些由软件工程师开发的AI们,误把这道数学题当成了版本号的比较?
这场“翻车”大戏,其实暴露出AI在处理问题时的一个关键问题:上下文理解。当数字以特定方式呈现时,AI可能会陷入预设的思维陷阱。比如,当提问方式变为“9.11和9.9,哪个更大?”时,许多顶级模型都会“信誓旦旦”地告诉你9.11更大。但只要稍微调整提问顺序,或者明确问题的数学背景,这些AI又能迅速给出正确答案。
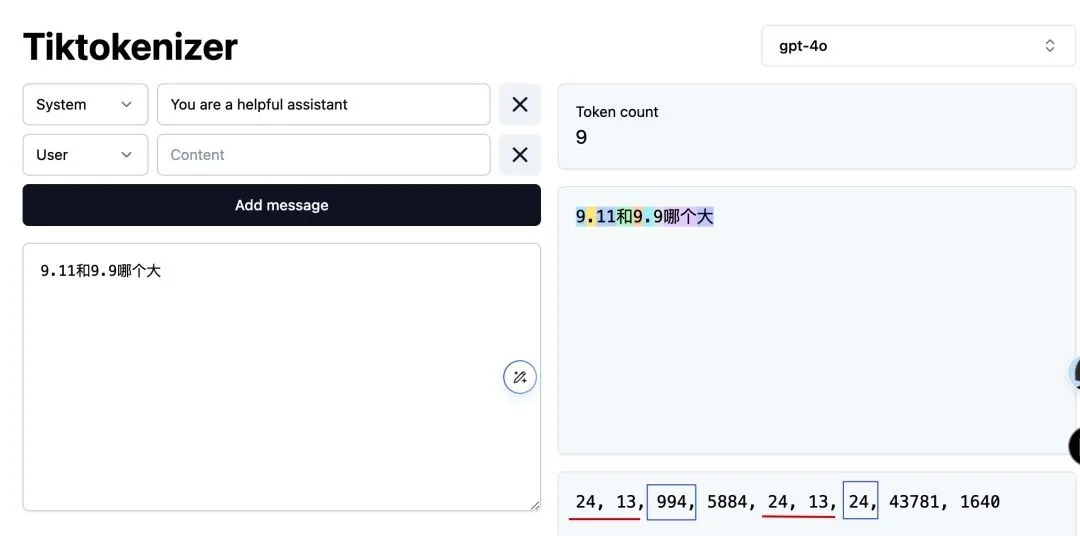
这究竟是怎么回事呢?其实,这与AI处理文本的方式有关。AI通过token来理解文字,而某些tokenizer可能会将9.11中的11视为一个整体,从而得出错误的比较结果。这就好比我们看书时,有时会因为断句不同而产生歧义一样。
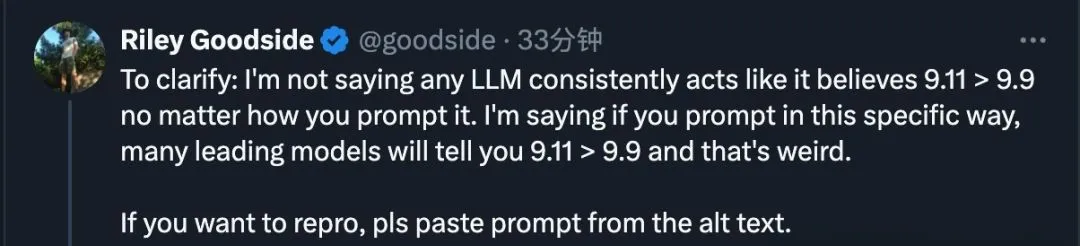
这场风波也引发了AI界的深思。如何提升AI在常识性问题上的准确性?如何在保持AI高效处理复杂问题的同时,不失对基础概念的把握?这无疑是未来AI发展中需要面临的挑战。

与此同时,我们也看到了AI界的探索与进步。Zero-shot CoT思维链方法的出现,让AI能够“一步一步地想”,从而更准确地理解问题。而各种角色扮演提示的尝试,也让我们看到了AI在多样化场景下的应变能力。
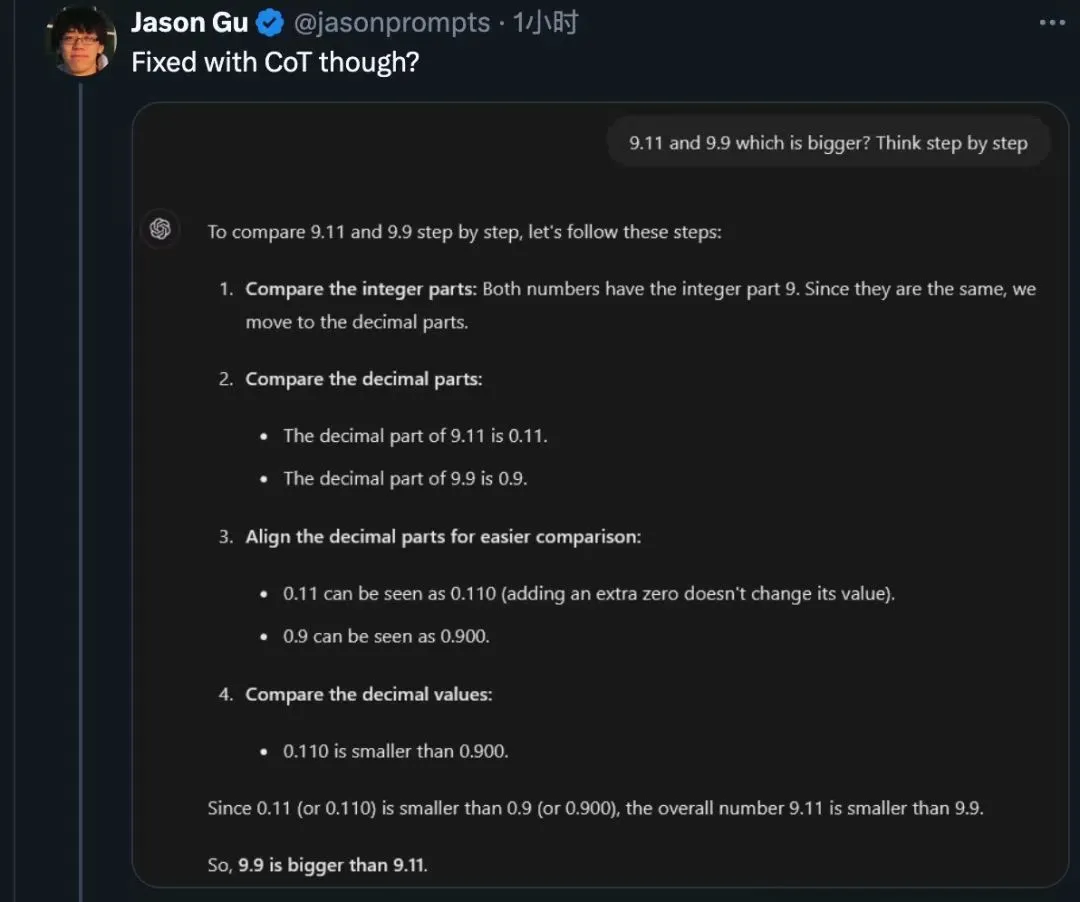
总的来说,这场“9.11与9.9的大小之战”虽然看似荒诞,却为我们揭示了AI发展道路上的种种挑战与机遇。让我们拭目以待,看AI如何在未来不断突破自我,成为人类智慧的得力助手。














暂无评论内容