难以置信,这件事终于发生了。
一种全新的大语言模型(LLM)架构有望代替至今在 AI 领域如日中天的 Transformer,性能也比 Mamba 更好。本周一,有关 Test-Time Training(TTT)的论文成为了人工智能社区热议的话题。

论文链接:https://arxiv.org/abs/2407.04620
该研究的作者来自斯坦福大学、加州大学伯克利分校、加州大学圣迭戈分校和 Meta。他们设计了一种新架构 TTT,用机器学习模型取代了 RNN 的隐藏状态。该模型通过输入 token 的实际梯度下降来压缩上下文。
该研究作者之一 Karan Dalal 表示,他相信这将根本性的改变语言模型方法。

在机器学习模型中,TTT 层直接取代 Attention,并通过表达性记忆解锁线性复杂性架构,使我们能够在上下文中训练具有数百万(有时是数十亿)个 token 的 LLM。
作者在 125M 到 1.3B 参数规模的大模型上进行了一系列对比发现,TTT-Linear 和 TTT-MLP 均能匹敌或击败最强大的 Transformers 和 Mamba 架构方法。
TTT 层作为一种新的信息压缩和模型记忆机制,可以简单地直接替代 Transformer 中的自注意力层。

与 Mamba 相比,TTT-Linear 的困惑度更低,FLOP 更少(左),对长上下文的利用更好(右):
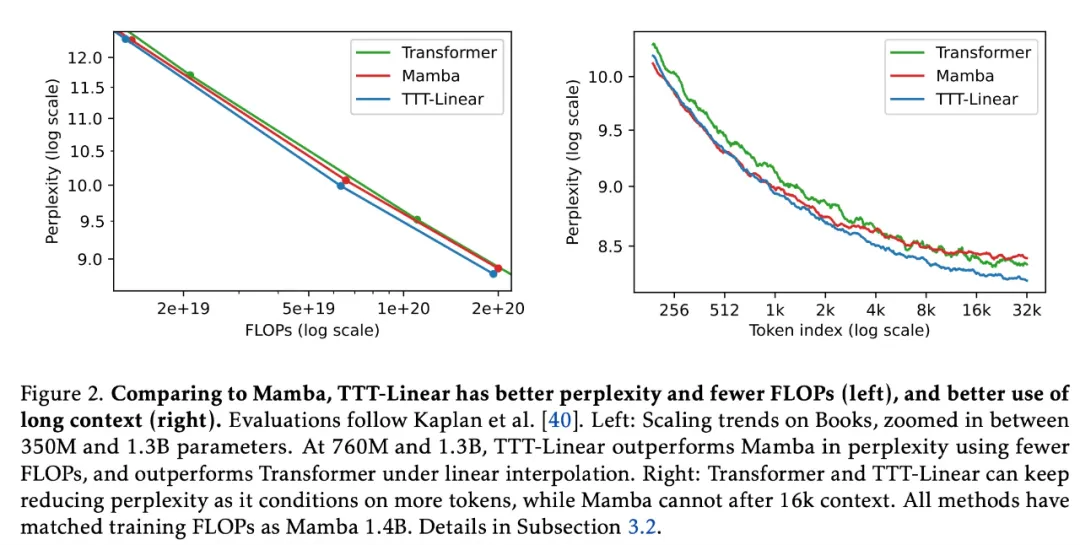
这不仅在理论上是线性的复杂度,而且实际运行时间也更快。
- 在论文上线后,作者公开了代码与 jax 以供人们训练和测试:https://github.com/test-time-training/ttt-lm-jax
- 还有 PyTorch 推理代码:https://github.com/test-time-training/ttt-lm-pytorch
方法介绍
长上下文的挑战是 RNN 层本质上所固有的:与自注意力机制不同,RNN 层必须将上下文压缩为固定大小的隐藏状态,更新规则需要发现数千甚至数百万个 token 之间的底层结构和关系。
研究团队首先观察到自监督学习可以将大量训练集压缩为 LLM 等模型的权重,而 LLM 模型通常表现出对其训练数据之间语义联系的深刻理解。
受此观察的启发,研究团队设计了一类新的序列建模层,其中隐藏状态是一个模型,更新规则是自监督学习的一个步骤。由于更新测试序列上的隐藏状态的过程相当于在测试时训练模型,因此研究团队将这种新的层称为测试时训练(Test-Time Training,TTT)层。
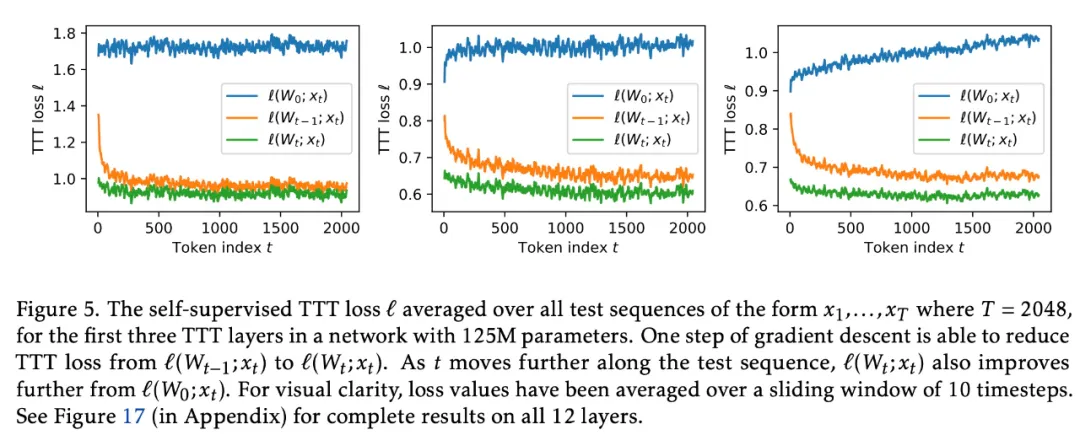
研究团队引入两个简单的实例:TTT-Linear 和 TTT-MLP,其中隐藏状态分别是线性模型和两层 MLP。TTT 层可以集成到任何网络架构中并进行端到端优化,类似于 RNN 层和自注意力。

为了让 TTT 层更加高效,该研究采取了一些技巧来改进 TTT 层:
首先,类似于在常规训练期间对小批量序列采取 gradient step 以获得更好的并行性,该研究在 TTT 期间使用小批量 token。
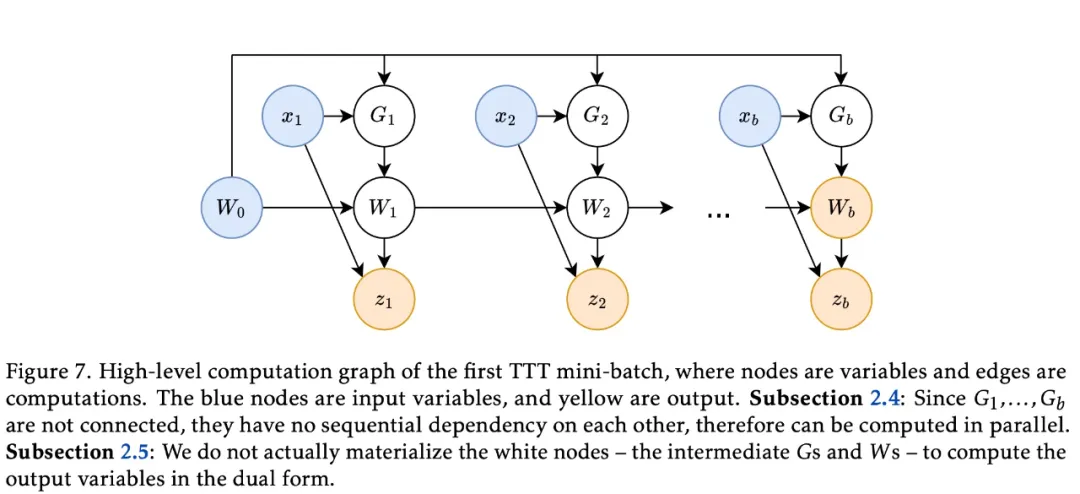
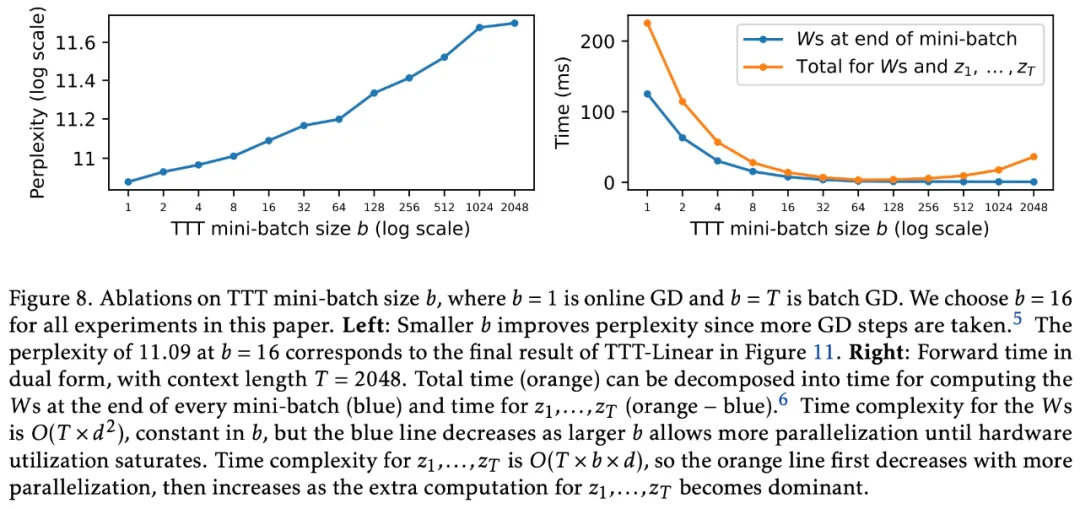
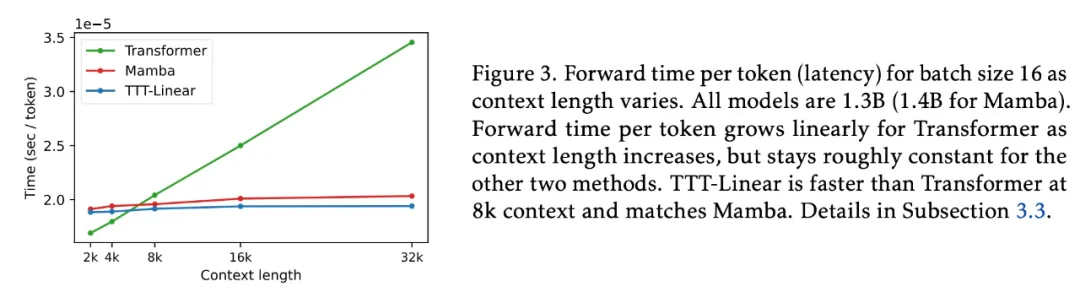
其次,该研究为每个 TTT 小批量内的操作开发了一种双重形式,以更好地利用现代 GPU 和 TPU。双重形式的输出与简单实现等效,但训练速度快了 5 倍以上。如图 3 所示,TTT-Linear 在 8k 上下文中比 Transformer 更快,与 Mamba 相当。
研究团队认为:所有序列建模层都可以看作将历史上下文存储到隐藏状态,如图 4 所示。

例如,RNN 层(如 LSTM、RWKV 和 Mamba 层)将上下文压缩为跨时间的固定大小状态。这种压缩会产生两种后果:一方面,将输入标记 x_t 映射到输出 token z_t 是高效的,因为每个 token 的更新规则和输出规则都需要恒定的时间。另一方面,RNN 层在长上下文中的性能受限于其隐藏状态 s_t 的表现力。
自注意力也可以从上述角度来看待,只不过它的隐藏状态(通常称为 Key-Value 缓存)是一个随 t 线性增长的列表。它的更新规则只是将当前的 KV 元组(tuple)追加到该列表中,而输出规则则扫描 t 前的所有元组,以形成注意力矩阵。隐藏状态明确存储了所有历史上下文,无需压缩,这使得自注意力在长上下文方面比 RNN 层更具表现力。然而,扫描这个线性增长的隐藏状态所需的时间也是线性增长的。为了保持长上下文的高效和表现力,研究者需要一种更好的压缩启发式。具体来说,需要将成千上万或可能上百万的 token 压缩到一个隐藏状态中,从而有效捕捉它们的底层结构和关系。这听起来似乎有些高难度,但实际上很多人都对这种启发式非常熟悉。
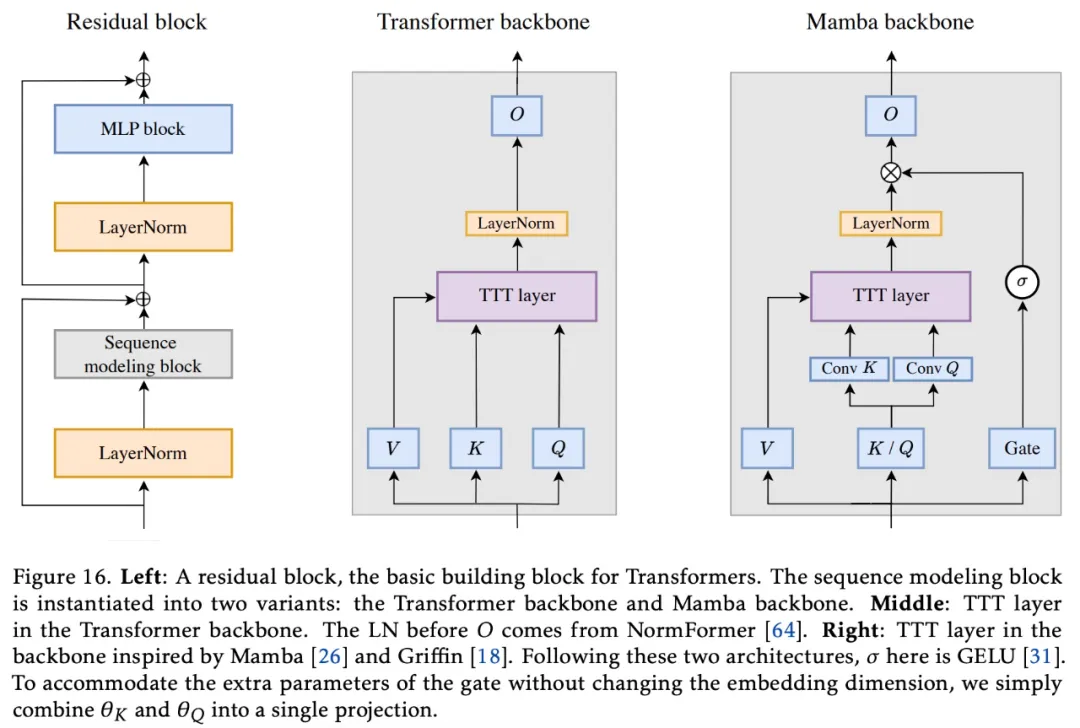
骨干架构。将任何 RNN 层集成到更大架构中的最简洁方法是直接替换 Transformer 中的自注意力,在这里称为骨干。然而,现有的 RNN(如 Mamba 和 Griffin 等)都使用了与 Transformer 不同的骨干层。最值得注意的是,它们的骨干层在 RNN 层之前包含了时间卷积,这可能有助于收集跨时间的局部信息。在对 Mamba 主干网进行试验后,研究者发现它也能改善 TTT 层的困惑度,因此将其纳入了建议方法中,详见图 16。
实验结果
在实验中,研究者将 TTT-Linear 、 TTT-MLP 与 Transformer、Mamba 这两种基线进行了比较。
短文本
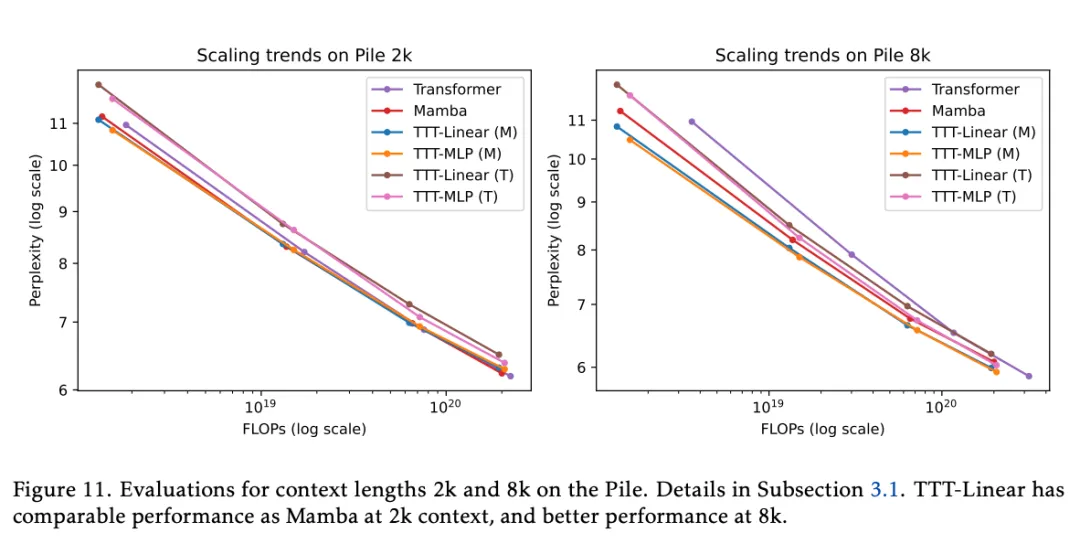
从图 11 中可以得出以下结论:
- 2k 上下文,TTT-Linear (M)、Mamba 和 Transformer 的性能相当,因为线条大多重叠。在 FLOP 预算较大的情况下,TTT-MLP (M) 的性能稍差。尽管 TTT-MLP 在各种模型大小下都比 TTT-Linear 有更好的困惑度,但 FLOPs 的额外成本抵消了这一优势。
- 8k 上下文,TTT-Linear (M) 和 TTT-MLP (M) 的表现都明显优于 Mamba,这与 2k 上下文中的观察结果截然不同。即使是使用 Transformer 主干网络的 TTT-MLP (T) 在 1.3B 左右也比 Mamba 略胜一筹。一个显著现象是,随着上下文长度的增加,TTT 层相对于 Mamba 层的优势也在扩大。
- 上下文长度达到 8k,Transformer 在每种模型尺寸下的困惑度依旧表现不错,但由于 FLOPs 成本的原因,已不具竞争力。
上图结果展示了将 TTT 层从 Mamba 主干网络切换到 Transformer 主干网络的影响。研究者假设,当序列建模层的隐藏状态表现力较低时,Mamba 主干网络中的时序卷积更有帮助。线性模型的表现力低于 MLP,因此从卷积中获益更多。
长文本:书籍
为了评估长上下文的能力,研究者使用 Pile 的一个流行子集 Books3,以 2 倍的增量对 1k 到 32k 的上下文长进行实验。这里的训练方法与 Pile 相同,并且 TTT 层的所有实验都在一次训练运行中完成。从图 12 中的结果子集,他们得出了以下观察结果:
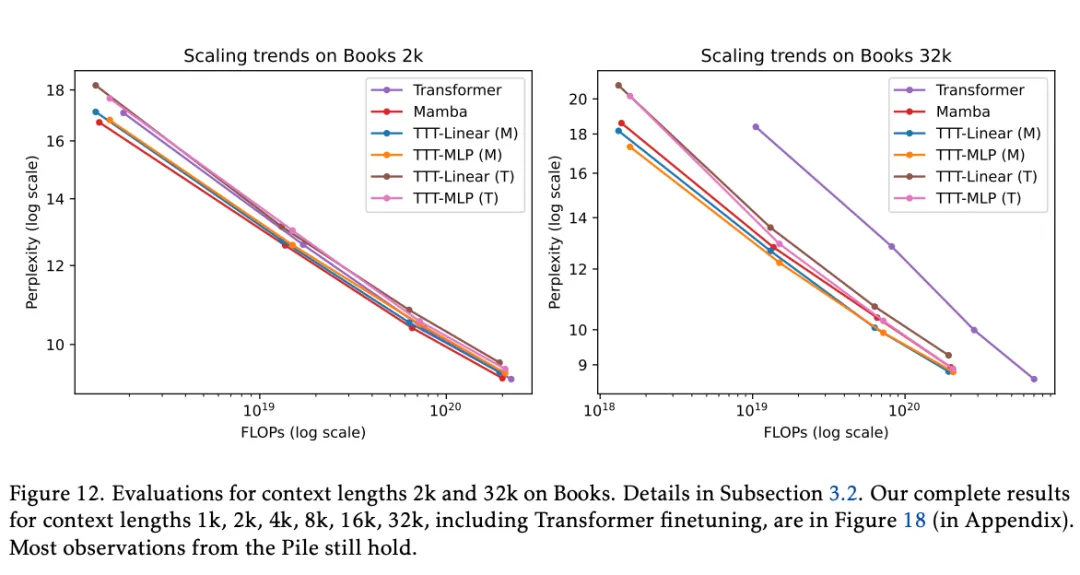
在 Books 的 2k 上下文中,Pile 2k 的所有观察结果仍然成立,只是 Mamba 现在的表现略好于 TTT-Linear(而它们的线条在 Pile 2k 中大致重叠)。
在 32k 上下文中,TTT-Linear (M) 和 TTT-MLP (M) 的表现都优于 Mamba,类似于 Pile 8k 的观察结果。即使是采用 Transformer 主干的 TTT-MLP (T) 在 32k 上下文中的表现也略好于 Mamba。
TTT-MLP (T) 在 1.3B 规模下仅略差于 TTT-MLP (M)。如上所述,由于缺乏清晰的线性拟合,很难得出经验缩放定律。然而,TTT-MLP (T) 的强劲趋势表明,Transformer 主干可能更适合更大的模型和更长的上下文,超出了我们的评估范围。
时钟时间
LLM 的训练和推理可分解为前向、后向和生成。推理过程中的提示词处理(也称为预填充)与训练过程中的前向运算相同,只是后向操作不需要存储中间激活值。
由于前向(训练和推理过程中)和后向都可以并行处理,因此这里使用了双重形式。生成新 token(也称为解码)本质上是顺序性的,因此这里使用了原始形式。
研究者提到,由于资源限制,本文实验使用 JAX 编写,并在 TPU 上运行。在 v5e-256 TPU pod 上,Transformer 基线在上下文为 2k 的情况下每次迭代训练需要 0.30 秒,而 TTT-Linear 每次迭代需要 0.27 秒,在没有任何系统优化的情况下快了 10%。鉴于 Mamba(用 PyTorch、Triton 和 CUDA 实现)只能在 GPU 上运行,为了进行公平比较,研究者将本文方法进行初步系统优化,使其能在 GPU 上运行。
图 15 左侧显示了各个模型的前向内核在批大小为 16 时的延迟。所有模型都是 1.3B(Mamba 为 1.4B)。值得注意的是,这里的 Transformer 基线要比 Mamba 论文中的快得多,因为此处使用了 vLLM ,而不是 HuggingFace Transformer 。
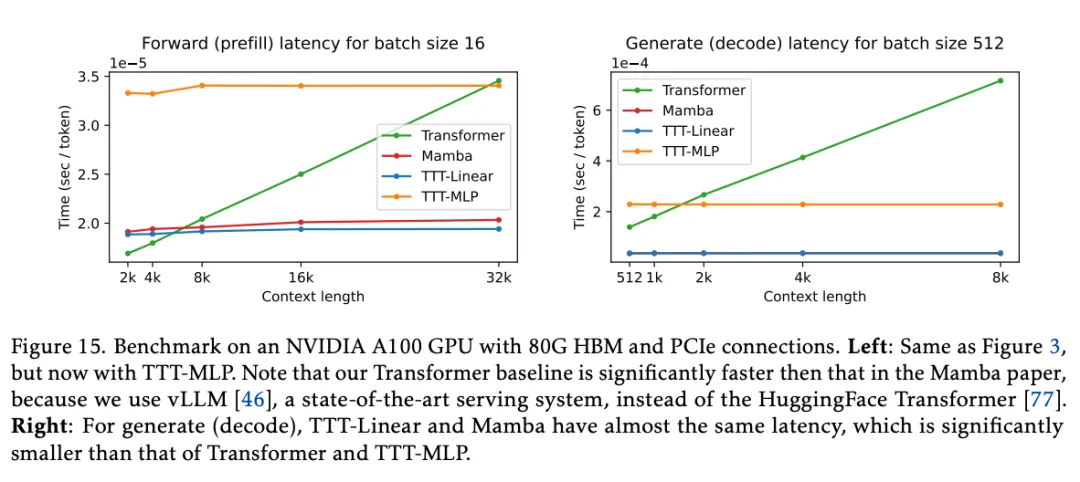
此外,研究者还编写了另一个用于生成的 GPU 内核,并在图 15 右侧以批大小 512 为基准测试其速度。另一个常用的挂钟时间(wall-clock time)指标是吞吐量(throughput),它考虑了使用更大的批大小的潜在好处。对于吞吐量,上述所有观察结果和方法之间的排序仍然有效。
主要作者
在 TTT 研究提交后,论文作者之一,UCSD 助理教授 Xiaolong Wang 发推表示祝贺。他表示,TTT 的研究持续了一年半,但测试时间训练(TTT)这个想法从诞生到现在其实已经过去了五年时间。虽然当初的想法和现在的成果完全不同了。

TTT 论文的三位主要作者分别来自于斯坦福、UC Berkeley 和 UCSD。
其中 Yu Sun 是斯坦福大学的博士后,他博士毕业于 UC Berkeley EECS,长期以来一直的研究方向就是 TTT。

Xinhao Li 是 UCSD 在读博士,他本科毕业于电子科技大学。

Karan Dalal 是 UC Berkeley 在读博士,他曾在高中时与他人共同创办了一家名为 Otto 的兽医远程医疗初创公司。

上述三人,都把 test-time training 写在了个人网站介绍研究方向的第一行。
更多研究细节,可参考原论文。














暂无评论内容